 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Localized Machine Unlearning Through the Lens of Memorization
Dec 03, 2024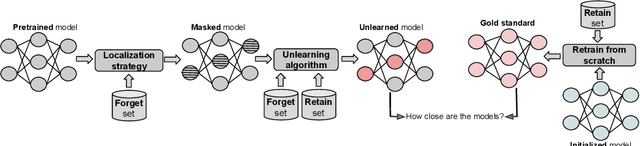
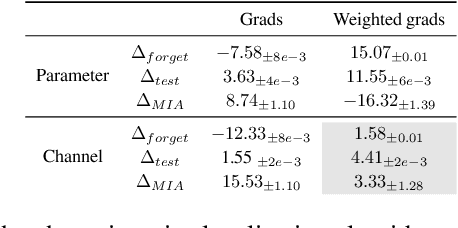
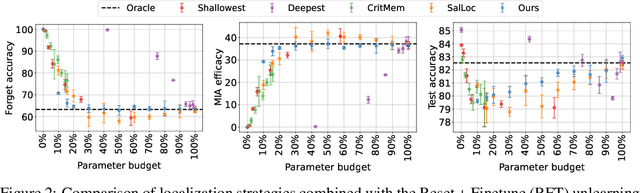
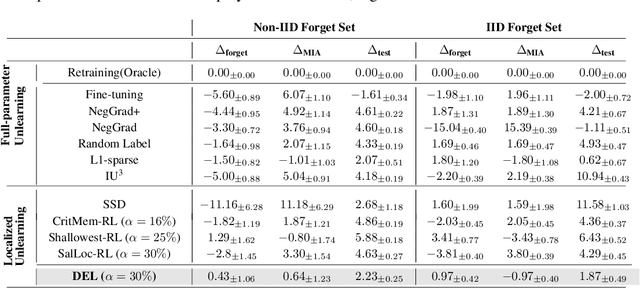
Machine unlearning refers to removing the influence of a specified subset of training data from a machine learning model, efficiently, after it has already been trained. This is important for key applications, including making the model more accurate by removing outdated, mislabeled, or poisoned data. In this work, we study localized unlearning, where the unlearning algorithm operates on a (small) identified subset of parameters. Drawing inspiration from the memorization literature, we propose an improved localization strategy that yields strong results when paired with existing unlearning algorithms. We also propose a new unlearning algorithm, Deletion by Example Localization (DEL), that resets the parameters deemed-to-be most critical according to our localization strategy, and then finetunes them. Our extensive experiments on different datasets, forget sets and metrics reveal that DEL sets a new state-of-the-art for unlearning metrics, against both localized and full-parameter methods, while modifying a small subset of parameters, and outperforms the state-of-the-art localized unlearning in terms of test accuracy too.
Label Noise-Robust Learning using a Confidence-Based Sieving Strategy
Oct 11, 2022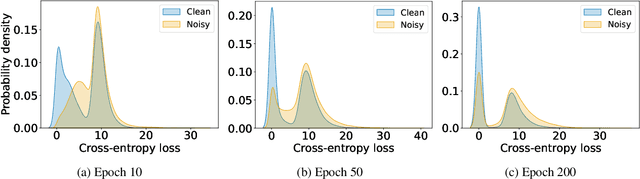
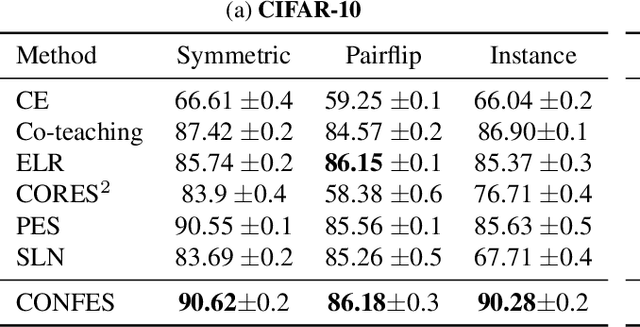
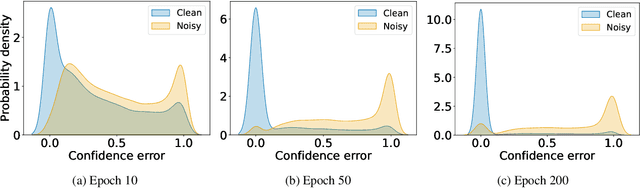
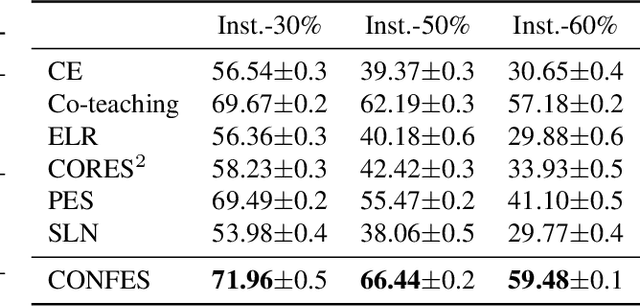
In learning tasks with label noise, boosting model robustness against overfitting is a pivotal challenge because the model eventually memorizes labels including the noisy ones. Identifying the samples with corrupted labels and preventing the model from learning them is a promising approach to address this challenge. Per-sample training loss is a previously studied metric that considers samples with small loss as clean samples on which the model should be trained. In this work, we first demonstrate the ineffectiveness of this small-loss trick. Then, we propose a novel discriminator metric called confidence error and a sieving strategy called CONFES to effectively differentiate between the clean and noisy samples. We experimentally illustrate the superior performance of our proposed approach compared to recent studies on various settings such as synthetic and real-world label noise.
Kernel Normalized Convolutional Networks
May 20, 2022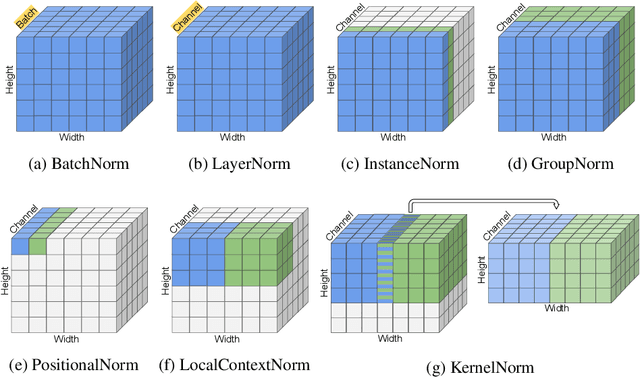
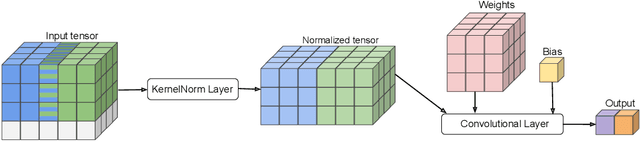

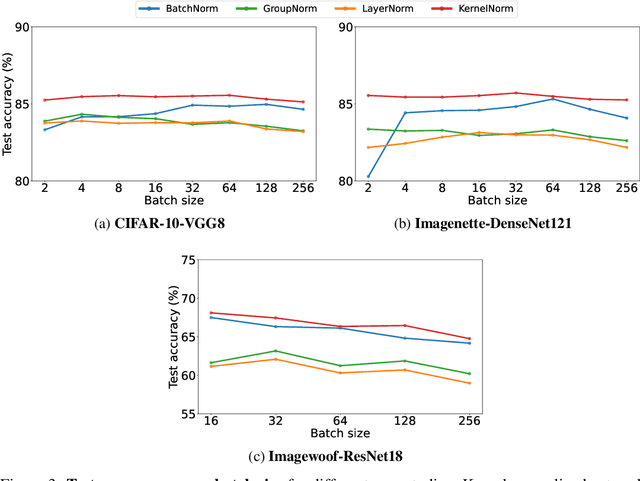
Existing deep convolutional neural network (CNN) architectures frequently rely upon batch normalization (BatchNorm) to effectively train the model. BatchNorm significantly improves model performance, but performs poorly with smaller batch sizes. To address this limitation, we propose kernel normalization and kernel normalized convolutional layers, and incorporate them into kernel normalized convolutional networks (KNConvNets) as the main building blocks. We implement KNConvNets corresponding to the state-of-the-art CNNs such as ResNet and DenseNet while forgoing BatchNorm layers. Through extensive experiments, we illustrate that KNConvNets consistently outperform their batch, group, and layer normalized counterparts in terms of both accuracy and convergence rate while maintaining competitive computational efficiency.
HyFed: A Hybrid Federated Framework for Privacy-preserving Machine Learning
May 21, 2021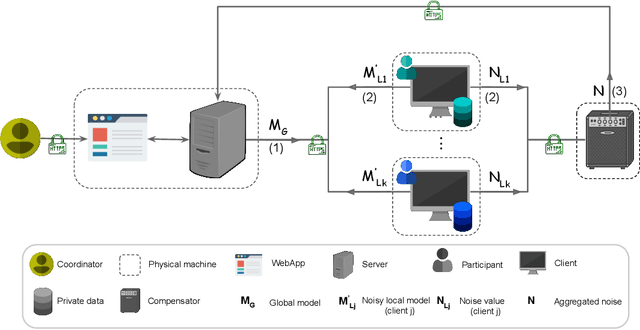


Federated learning (FL) enables multiple clients to jointly train a global model under the coordination of a central server. Although FL is a privacy-aware paradigm, where raw data sharing is not required, recent studies have shown that FL might leak the private data of a client through the model parameters shared with the server or the other clients. In this paper, we present the HyFed framework, which enhances the privacy of FL while preserving the utility of the global model. HyFed provides developers with a generic API to develop federated, privacy-preserving algorithms. HyFed supports both simulation and federated operation modes and its source code is publicly available at https://github.com/tum-aimed/hyfed.
The FeatureCloud AI Store for Federated Learning in Biomedicine and Beyond
May 12, 2021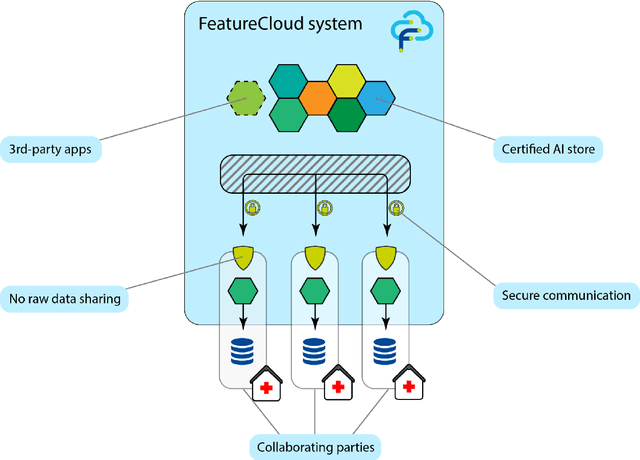
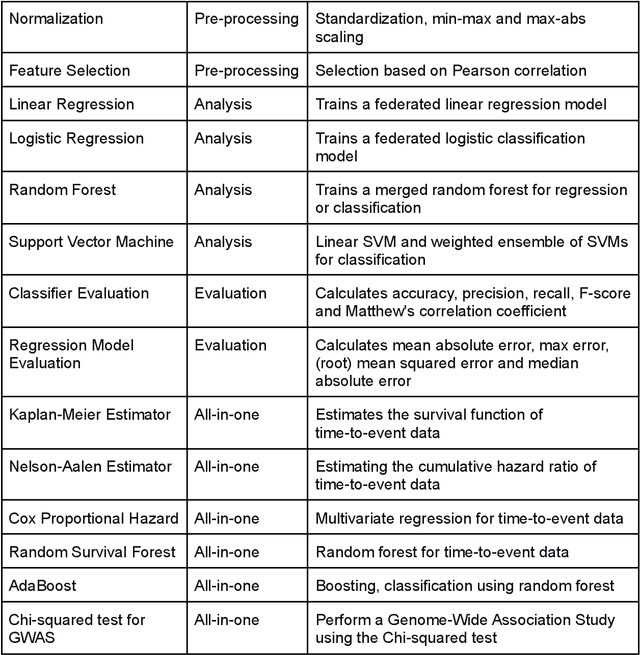
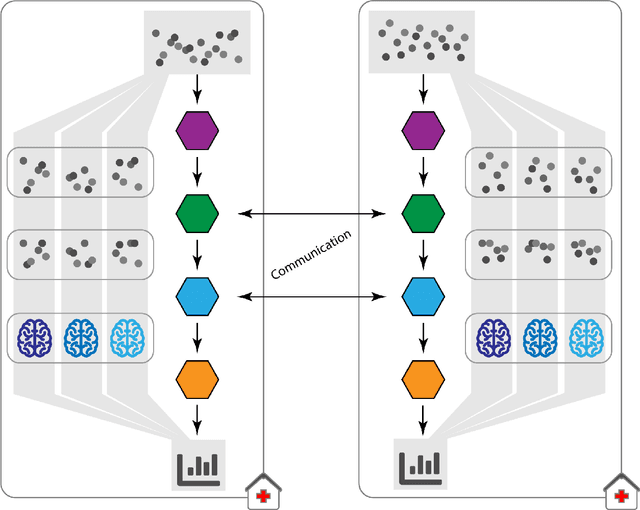
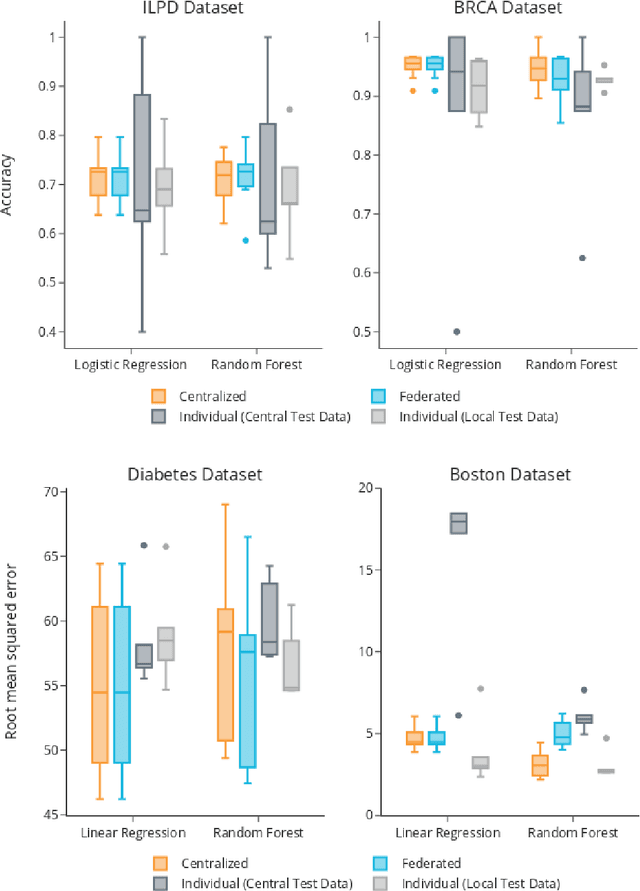
Machine Learning (ML) and Artificial Intelligence (AI) have shown promising results in many areas and are driven by the increasing amount of available data. However, this data is often distributed across different institutions and cannot be shared due to privacy concerns. Privacy-preserving methods, such as Federated Learning (FL), allow for training ML models without sharing sensitive data, but their implementation is time-consuming and requires advanced programming skills. Here, we present the FeatureCloud AI Store for FL as an all-in-one platform for biomedical research and other applications. It removes large parts of this complexity for developers and end-users by providing an extensible AI Store with a collection of ready-to-use apps. We show that the federated apps produce similar results to centralized ML, scale well for a typical number of collaborators and can be combined with Secure Multiparty Computation (SMPC), thereby making FL algorithms safely and easily applicable in biomedical and clinical environments.
Federated Multi-Mini-Batch: An Efficient Training Approach to Federated Learning in Non-IID Environments
Nov 13, 2020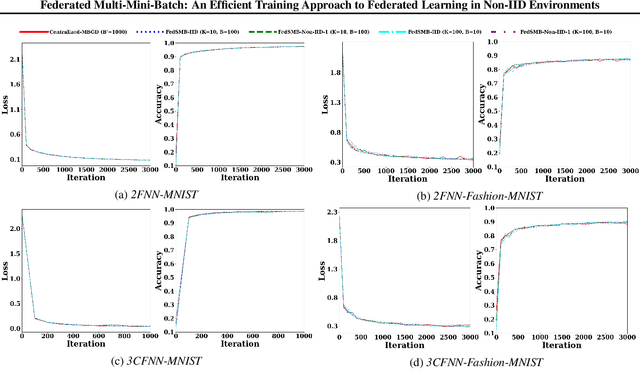

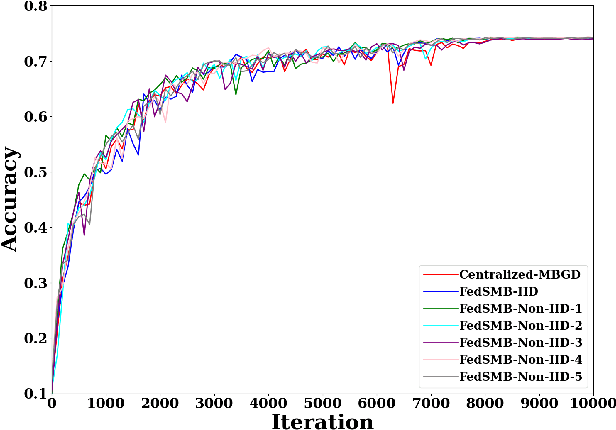
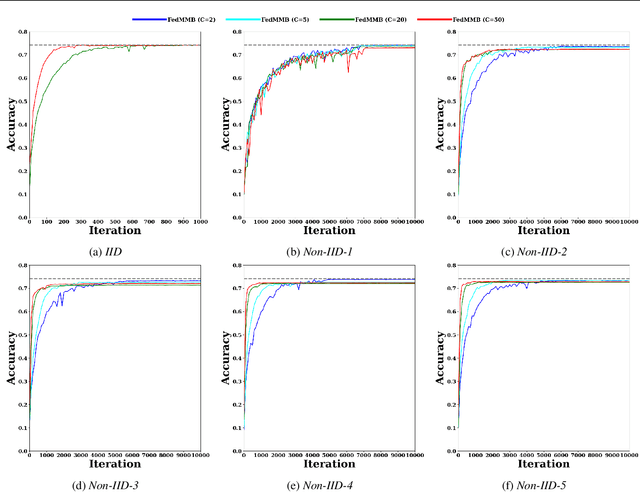
Federated learning is a well-established approach to privacy-preserving training of a joint model on heavily distributed data. Federated averaging (FedAvg) is a well-known communication-efficient algorithm for federated learning, which performs well if the data distribution across the clients is independently and identically distributed (IID). However, FedAvg provides a lower accuracy and still requires a large number of communication rounds to achieve a target accuracy when it comes to Non-IID environments. To address the former limitation, we present federated single mini-batch (FedSMB), where the clients train the model on a single mini-batch from their dataset in each iteration. We show that FedSMB achieves the accuracy of the centralized training in Non-IID configurations, but in a considerable number of iterations. To address the latter limitation, we introduce federated multi-mini-batch (FedMMB) as a generalization of FedSMB, where the clients train the model on multiple mini-batches (specified by the batch count) in each communication round. FedMMB decouples the batch size from the batch count and provides a trade-off between the accuracy and communication efficiency in Non-IID settings. This is not possible with FedAvg, in which a single parameter determines both the batch size and batch count. The simulation results illustrate that FedMMB outperforms FedAvg in terms of the accuracy, communication efficiency, as well as computational efficiency and is an efficient training approach to federated learning in Non-IID environments.
Privacy-preserving Artificial Intelligence Techniques in Biomedicine
Jul 22, 2020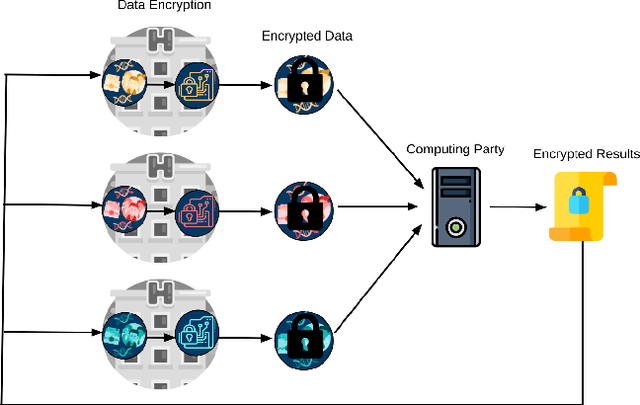
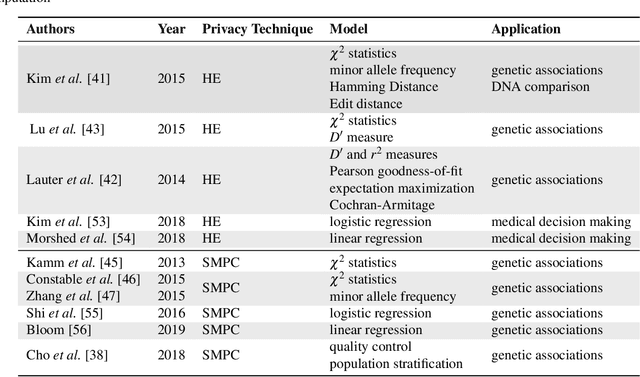
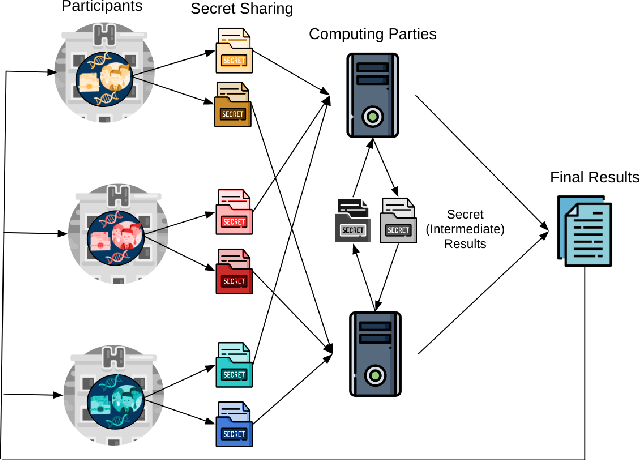
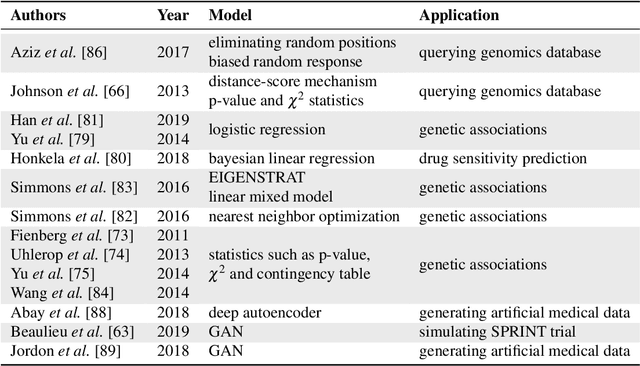
Artificial intelligence (AI) has been successfully applied in numerous scientific domains including biomedicine and healthcare. Here, it has led to several breakthroughs ranging from clinical decision support systems, image analysis to whole genome sequencing. However, training an AI model on sensitive data raises also concerns about the privacy of individual participants. Adversary AIs, for example, can abuse even summary statistics of a study to determine the presence or absence of an individual in a given dataset. This has resulted in increasing restrictions to access biomedical data, which in turn is detrimental for collaborative research and impedes scientific progress. Hence there has been an explosive growth in efforts to harness the power of AI for learning from sensitive data while protecting patients' privacy. This paper provides a structured overview of recent advances in privacy-preserving AI techniques in biomedicine. It places the most important state-of-the-art approaches within a unified taxonomy, and discusses their strengths, limitations, and open problems.
DP-CGAN: Differentially Private Synthetic Data and Label Generation
Jan 27, 2020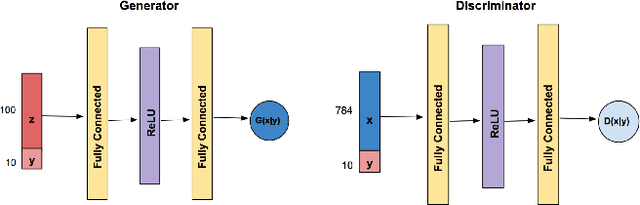

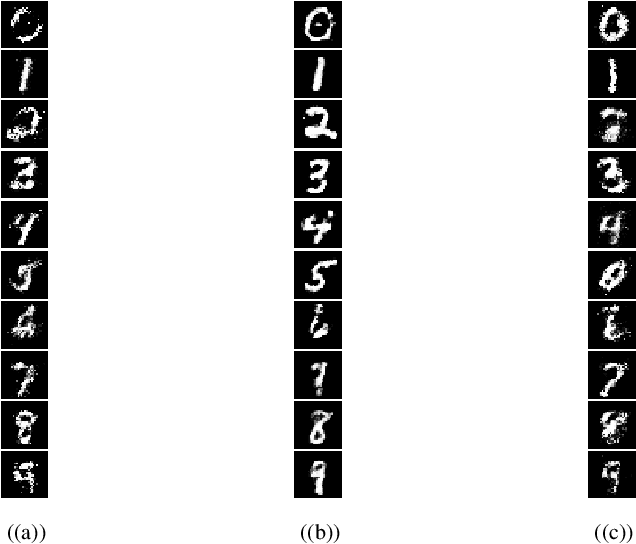
Generative Adversarial Networks (GANs) are one of the well-known models to generate synthetic data including images, especially for research communities that cannot use original sensitive datasets because they are not publicly accessible. One of the main challenges in this area is to preserve the privacy of individuals who participate in the training of the GAN models. To address this challenge, we introduce a Differentially Private Conditional GAN (DP-CGAN) training framework based on a new clipping and perturbation strategy, which improves the performance of the model while preserving privacy of the training dataset. DP-CGAN generates both synthetic data and corresponding labels and leverages the recently introduced Renyi differential privacy accountant to track the spent privacy budget. The experimental results show that DP-CGAN can generate visually and empirically promising results on the MNIST dataset with a single-digit epsilon parameter in differential privacy.