 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedRBE -- a decentralized privacy-preserving federated batch effect correction tool for omics data based on limma
Dec 08, 2024



Batch effects in omics data obscure true biological signals and constitute a major challenge for privacy-preserving analyses of distributed patient data. Existing batch effect correction methods either require data centralization, which may easily conflict with privacy requirements, or lack support for missing values and automated workflows. To bridge this gap, we developed fedRBE, a federated implementation of limma's removeBatchEffect method. We implemented it as an app for the FeatureCloud platform. Unlike its existing analogs, fedRBE effectively handles data with missing values and offers an automated, user-friendly online user interface (https://featurecloud.ai/app/fedrbe). Leveraging secure multi-party computation provides enhanced security guarantees over classical federated learning approaches. We evaluated our fedRBE algorithm on simulated and real omics data, achieving performance comparable to the centralized method with negligible differences (no greater than 3.6E-13). By enabling collaborative correction without data sharing, fedRBE facilitates large-scale omics studies where batch effect correction is crucial.
UnPaSt: unsupervised patient stratification by differentially expressed biclusters in omics data
Jul 31, 2024Most complex diseases, including cancer and non-malignant diseases like asthma, have distinct molecular subtypes that require distinct clinical approaches. However, existing computational patient stratification methods have been benchmarked almost exclusively on cancer omics data and only perform well when mutually exclusive subtypes can be characterized by many biomarkers. Here, we contribute with a massive evaluation attempt, quantitatively exploring the power of 22 unsupervised patient stratification methods using both, simulated and real transcriptome data. From this experience, we developed UnPaSt (https://apps.cosy.bio/unpast/) optimizing unsupervised patient stratification, working even with only a limited number of subtype-predictive biomarkers. We evaluated all 23 methods on real-world breast cancer and asthma transcriptomics data. Although many methods reliably detected major breast cancer subtypes, only few identified Th2-high asthma, and UnPaSt significantly outperformed its closest competitors in both test datasets. Essentially, we showed that UnPaSt can detect many biologically insightful and reproducible patterns in omic datasets.
Privacy-Preserving Multi-Center Differential Protein Abundance Analysis with FedProt
Jul 21, 2024



Quantitative mass spectrometry has revolutionized proteomics by enabling simultaneous quantification of thousands of proteins. Pooling patient-derived data from multiple institutions enhances statistical power but raises significant privacy concerns. Here we introduce FedProt, the first privacy-preserving tool for collaborative differential protein abundance analysis of distributed data, which utilizes federated learning and additive secret sharing. In the absence of a multicenter patient-derived dataset for evaluation, we created two, one at five centers from LFQ E.coli experiments and one at three centers from TMT human serum. Evaluations using these datasets confirm that FedProt achieves accuracy equivalent to DEqMS applied to pooled data, with completely negligible absolute differences no greater than $\text{$4 \times 10^{-12}$}$. In contrast, -log10(p-values) computed by the most accurate meta-analysis methods diverged from the centralized analysis results by up to 25-27. FedProt is available as a web tool with detailed documentation as a FeatureCloud App.
The FeatureCloud AI Store for Federated Learning in Biomedicine and Beyond
May 12, 2021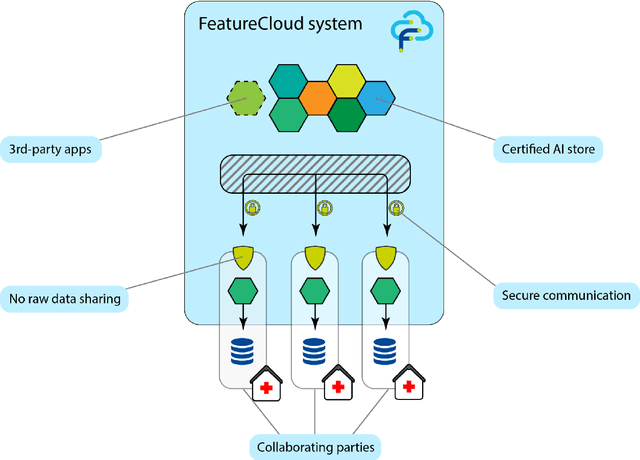
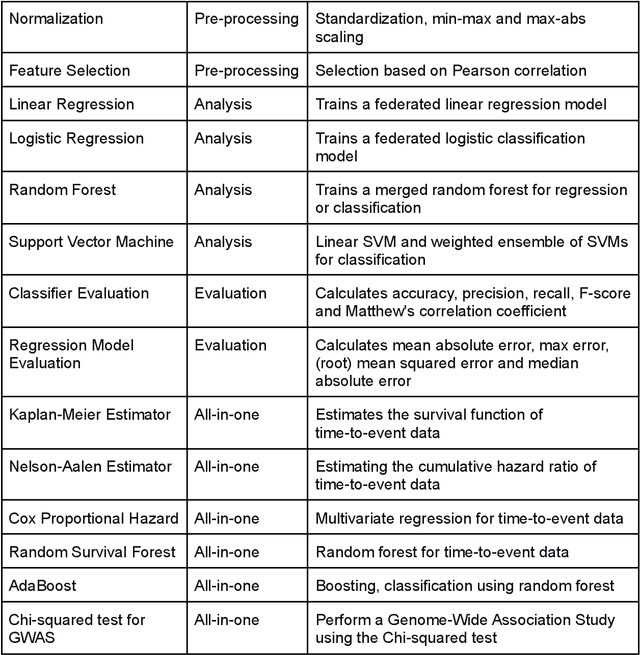
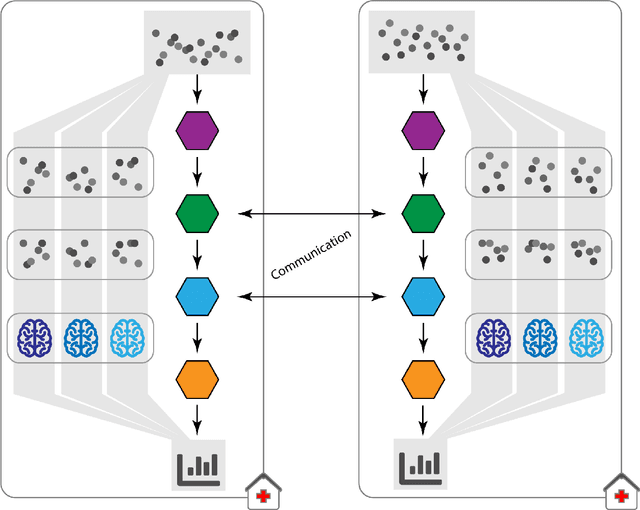
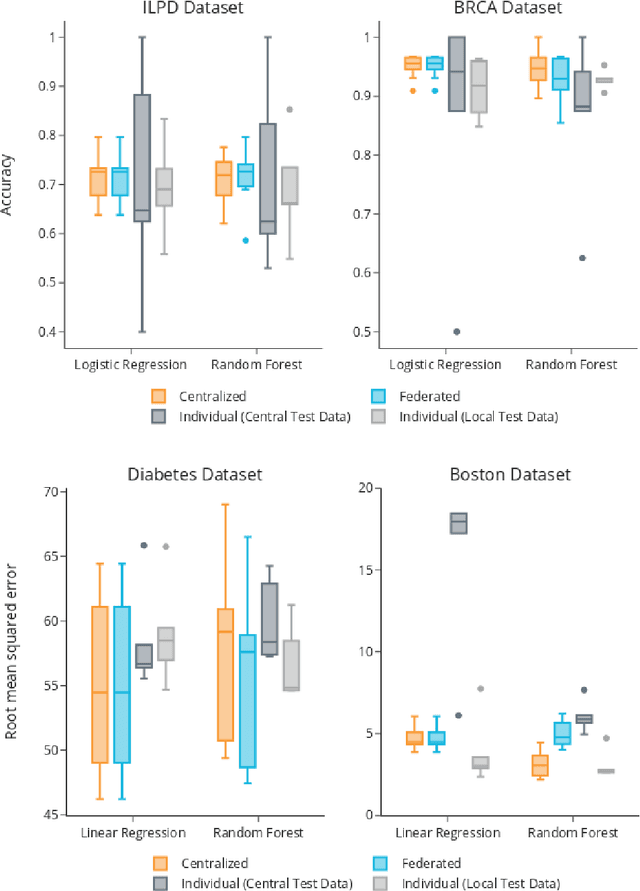
Machine Learning (ML) and Artificial Intelligence (AI) have shown promising results in many areas and are driven by the increasing amount of available data. However, this data is often distributed across different institutions and cannot be shared due to privacy concerns. Privacy-preserving methods, such as Federated Learning (FL), allow for training ML models without sharing sensitive data, but their implementation is time-consuming and requires advanced programming skills. Here, we present the FeatureCloud AI Store for FL as an all-in-one platform for biomedical research and other applications. It removes large parts of this complexity for developers and end-users by providing an extensible AI Store with a collection of ready-to-use apps. We show that the federated apps produce similar results to centralized ML, scale well for a typical number of collaborators and can be combined with Secure Multiparty Computation (SMPC), thereby making FL algorithms safely and easily applicable in biomedical and clinical environments.