 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Multi-Center Differential Protein Abundance Analysis with FedProt
Jul 21, 2024



Quantitative mass spectrometry has revolutionized proteomics by enabling simultaneous quantification of thousands of proteins. Pooling patient-derived data from multiple institutions enhances statistical power but raises significant privacy concerns. Here we introduce FedProt, the first privacy-preserving tool for collaborative differential protein abundance analysis of distributed data, which utilizes federated learning and additive secret sharing. In the absence of a multicenter patient-derived dataset for evaluation, we created two, one at five centers from LFQ E.coli experiments and one at three centers from TMT human serum. Evaluations using these datasets confirm that FedProt achieves accuracy equivalent to DEqMS applied to pooled data, with completely negligible absolute differences no greater than $\text{$4 \times 10^{-12}$}$. In contrast, -log10(p-values) computed by the most accurate meta-analysis methods diverged from the centralized analysis results by up to 25-27. FedProt is available as a web tool with detailed documentation as a FeatureCloud App.
The FeatureCloud AI Store for Federated Learning in Biomedicine and Beyond
May 12, 2021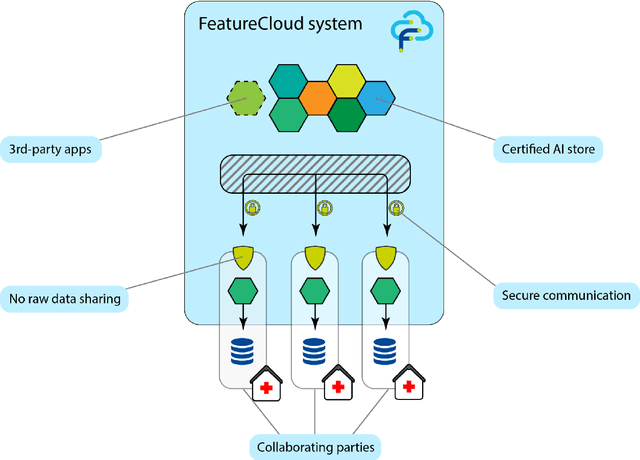
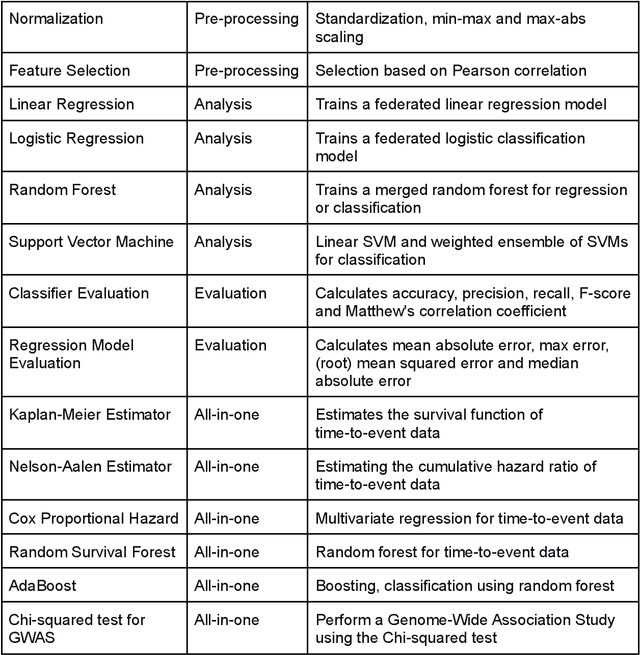
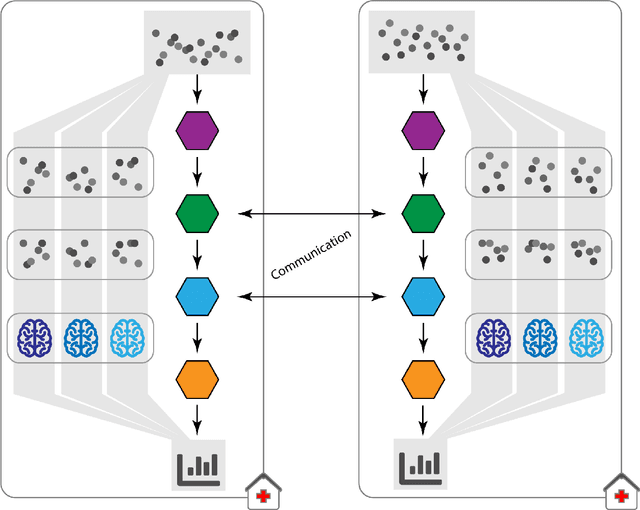
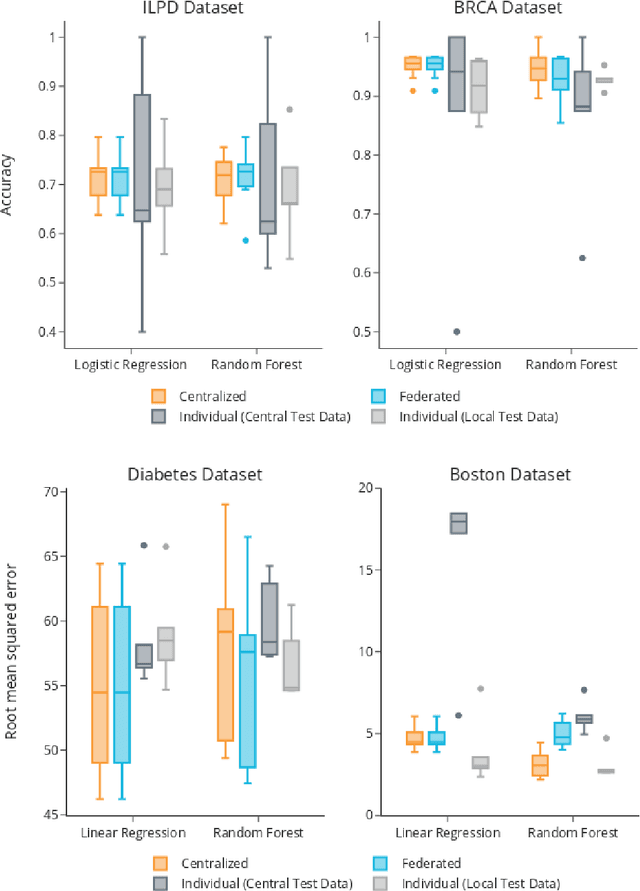
Machine Learning (ML) and Artificial Intelligence (AI) have shown promising results in many areas and are driven by the increasing amount of available data. However, this data is often distributed across different institutions and cannot be shared due to privacy concerns. Privacy-preserving methods, such as Federated Learning (FL), allow for training ML models without sharing sensitive data, but their implementation is time-consuming and requires advanced programming skills. Here, we present the FeatureCloud AI Store for FL as an all-in-one platform for biomedical research and other applications. It removes large parts of this complexity for developers and end-users by providing an extensible AI Store with a collection of ready-to-use apps. We show that the federated apps produce similar results to centralized ML, scale well for a typical number of collaborators and can be combined with Secure Multiparty Computation (SMPC), thereby making FL algorithms safely and easily applicable in biomedical and clinical environments.
Privacy-preserving Artificial Intelligence Techniques in Biomedicine
Jul 22, 2020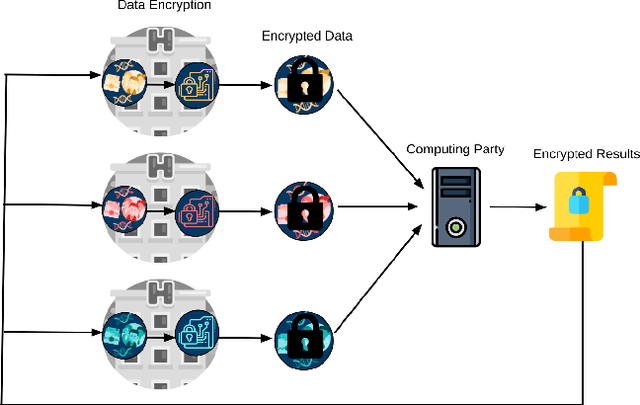
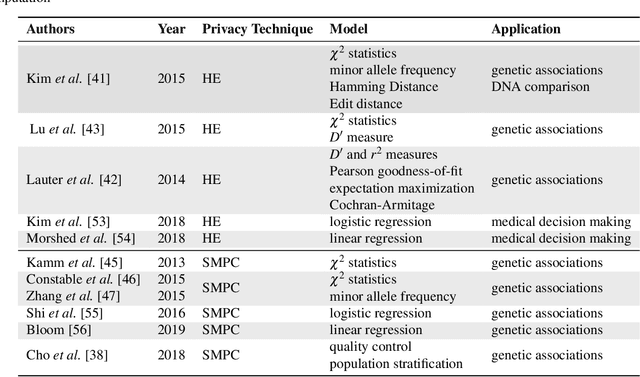
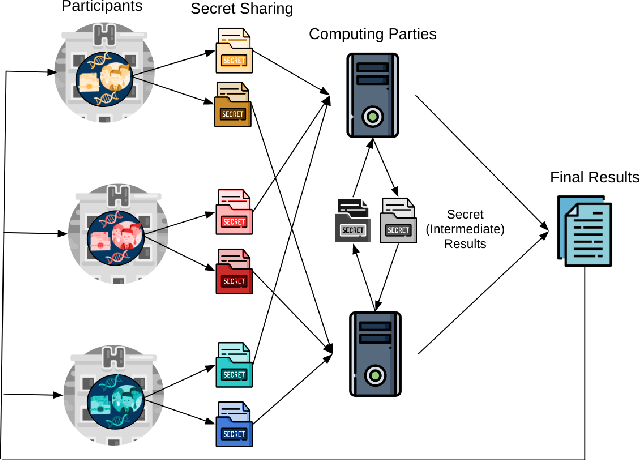
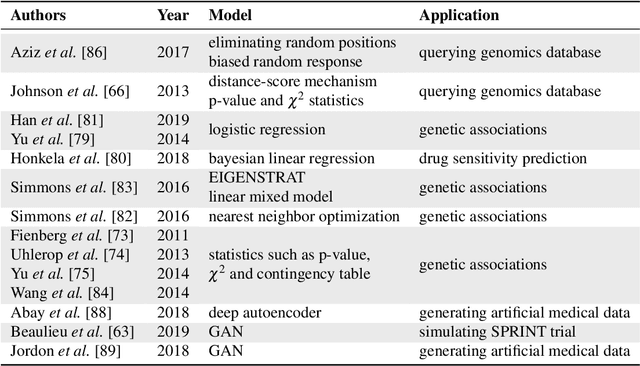
Artificial intelligence (AI) has been successfully applied in numerous scientific domains including biomedicine and healthcare. Here, it has led to several breakthroughs ranging from clinical decision support systems, image analysis to whole genome sequencing. However, training an AI model on sensitive data raises also concerns about the privacy of individual participants. Adversary AIs, for example, can abuse even summary statistics of a study to determine the presence or absence of an individual in a given dataset. This has resulted in increasing restrictions to access biomedical data, which in turn is detrimental for collaborative research and impedes scientific progress. Hence there has been an explosive growth in efforts to harness the power of AI for learning from sensitive data while protecting patients' privacy. This paper provides a structured overview of recent advances in privacy-preserving AI techniques in biomedicine. It places the most important state-of-the-art approaches within a unified taxonomy, and discusses their strengths, limitations, and open problems.