 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabel Noise-Robust Learning using a Confidence-Based Sieving Strategy
Paper and Code
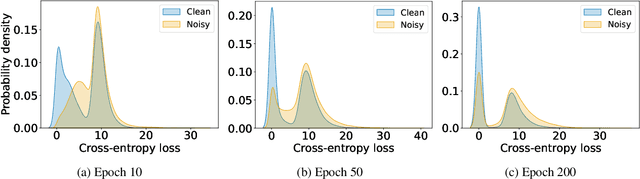
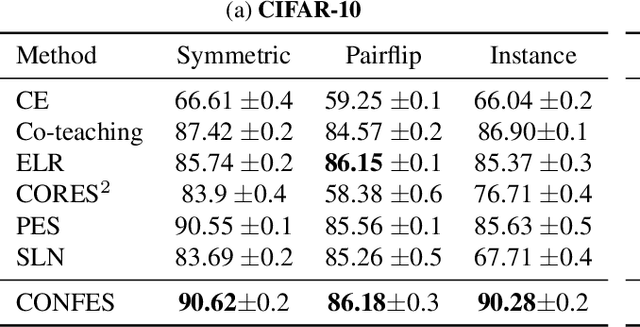
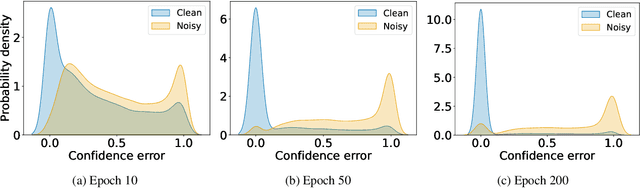
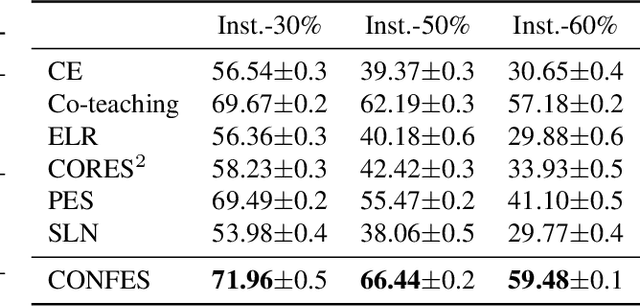
In learning tasks with label noise, boosting model robustness against overfitting is a pivotal challenge because the model eventually memorizes labels including the noisy ones. Identifying the samples with corrupted labels and preventing the model from learning them is a promising approach to address this challenge. Per-sample training loss is a previously studied metric that considers samples with small loss as clean samples on which the model should be trained. In this work, we first demonstrate the ineffectiveness of this small-loss trick. Then, we propose a novel discriminator metric called confidence error and a sieving strategy called CONFES to effectively differentiate between the clean and noisy samples. We experimentally illustrate the superior performance of our proposed approach compared to recent studies on various settings such as synthetic and real-world label noise.