 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable Subspace Identification of Nonlinear Multi-view CCA
Feb 27, 2026We investigate the identifiability of nonlinear Canonical Correlation Analysis (CCA) in a multi-view setup, where each view is generated by an unknown nonlinear map applied to a linear mixture of shared latents and view-private noise. Rather than attempting exact unmixing, a problem proven to be ill-posed, we instead reframe multi-view CCA as a basis-invariant subspace identification problem. We prove that, under suitable latent priors and spectral separation conditions, multi-view CCA recovers the pairwise correlated signal subspaces up to view-wise orthogonal ambiguity. For $N \geq 3$ views, the objective provably isolates the jointly correlated subspaces shared across all views while eliminating view-private variations. We further establish finite-sample consistency guarantees by translating the concentration of empirical cross-covariances into explicit subspace error bounds via spectral perturbation theory. Experiments on synthetic and rendered image datasets validate our theoretical findings and confirm the necessity of the assumed conditions.
Physics-Informed Learning of Flow Distribution and Receiver Heat Losses in Parabolic Trough Solar Fields
Dec 11, 2025



Parabolic trough Concentrating Solar Power (CSP) plants operate large hydraulic networks of collector loops that must deliver a uniform outlet temperature despite spatially heterogeneous optical performance, heat losses, and pressure drops. While loop temperatures are measured, loop-level mass flows and receiver heat-loss parameters are unobserved, making it impossible to diagnose hydraulic imbalances or receiver degradation using standard monitoring tools. We present a physics-informed learning framework that infers (i) loop-level mass-flow ratios and (ii) time-varying receiver heat-transfer coefficients directly from routine operational data. The method exploits nocturnal homogenization periods -- when hot oil is circulated through a non-irradiated field -- to isolate hydraulic and thermal-loss effects. A differentiable conjugate heat-transfer model is discretized and embedded into an end-to-end learning pipeline optimized using historical plant data from the 50 MW Andasol 3 solar field. The model accurately reconstructs loop temperatures (RMSE $<2^\circ$C) and produces physically meaningful estimates of loop imbalances and receiver heat losses. Comparison against drone-based infrared thermography (QScan) shows strong correspondence, correctly identifying all areas with high-loss receivers. This demonstrates that noisy real-world CSP operational data contain enough information to recover latent physical parameters when combined with appropriate modeling and differentiable optimization.
Provable Affine Identifiability of Nonlinear CCA under Latent Distributional Priors
Oct 06, 2025In this work, we establish conditions under which nonlinear CCA recovers the ground-truth latent factors up to an orthogonal transform after whitening. Building on the classical result that linear mappings maximize canonical correlations under Gaussian priors, we prove affine identifiability for a broad class of latent distributions in the population setting. Central to our proof is a reparameterization result that transports the analysis from observation space to source space, where identifiability becomes tractable. We further show that whitening is essential for ensuring boundedness and well-conditioning, thereby underpinning identifiability. Beyond the population setting, we prove that ridge-regularized empirical CCA converges to its population counterpart, transferring these guarantees to the finite-sample regime. Experiments on a controlled synthetic dataset and a rendered image dataset validate our theory and demonstrate the necessity of its assumptions through systematic ablations.
Mechanistic Independence: A Principle for Identifiable Disentangled Representations
Sep 26, 2025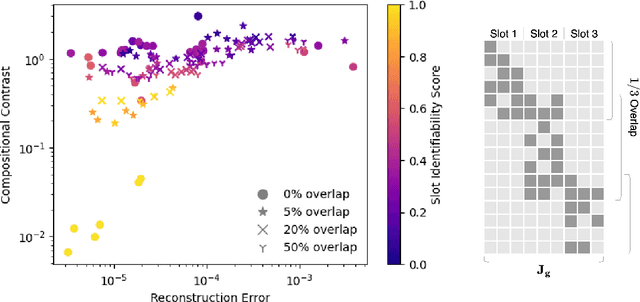
Disentangled representations seek to recover latent factors of variation underlying observed data, yet their identifiability is still not fully understood. We introduce a unified framework in which disentanglement is achieved through mechanistic independence, which characterizes latent factors by how they act on observed variables rather than by their latent distribution. This perspective is invariant to changes of the latent density, even when such changes induce statistical dependencies among factors. Within this framework, we propose several related independence criteria -- ranging from support-based and sparsity-based to higher-order conditions -- and show that each yields identifiability of latent subspaces, even under nonlinear, non-invertible mixing. We further establish a hierarchy among these criteria and provide a graph-theoretic characterization of latent subspaces as connected components. Together, these results clarify the conditions under which disentangled representations can be identified without relying on statistical assumptions.
Towards a Unified Framework of Contrastive Learning for Disentangled Representations
Nov 08, 2023Contrastive learning has recently emerged as a promising approach for learning data representations that discover and disentangle the explanatory factors of the data. Previous analyses of such approaches have largely focused on individual contrastive losses, such as noise-contrastive estimation (NCE) and InfoNCE, and rely on specific assumptions about the data generating process. This paper extends the theoretical guarantees for disentanglement to a broader family of contrastive methods, while also relaxing the assumptions about the data distribution. Specifically, we prove identifiability of the true latents for four contrastive losses studied in this paper, without imposing common independence assumptions. The theoretical findings are validated on several benchmark datasets. Finally, practical limitations of these methods are also investigated.
Knowledge Augmented Machine Learning with Applications in Autonomous Driving: A Survey
May 10, 2022
The existence of representative datasets is a prerequisite of many successful artificial intelligence and machine learning models. However, the subsequent application of these models often involves scenarios that are inadequately represented in the data used for training. The reasons for this are manifold and range from time and cost constraints to ethical considerations. As a consequence, the reliable use of these models, especially in safety-critical applications, is a huge challenge. Leveraging additional, already existing sources of knowledge is key to overcome the limitations of purely data-driven approaches, and eventually to increase the generalization capability of these models. Furthermore, predictions that conform with knowledge are crucial for making trustworthy and safe decisions even in underrepresented scenarios. This work provides an overview of existing techniques and methods in the literature that combine data-based models with existing knowledge. The identified approaches are structured according to the categories integration, extraction and conformity. Special attention is given to applications in the field of autonomous driving.
Knowledge as Invariance -- History and Perspectives of Knowledge-augmented Machine Learning
Dec 21, 2020
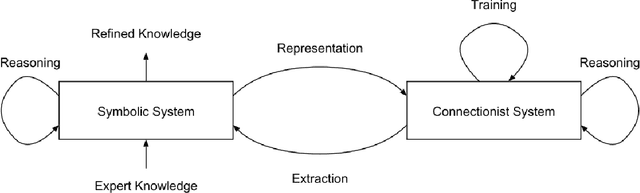
Research in machine learning is at a turning point. While supervised deep learning has conquered the field at a breathtaking pace and demonstrated the ability to solve inference problems with unprecedented accuracy, it still does not quite live up to its name if we think of learning as the process of acquiring knowledge about a subject or problem. Major weaknesses of present-day deep learning models are, for instance, their lack of adaptability to changes of environment or their incapability to perform other kinds of tasks than the one they were trained for. While it is still unclear how to overcome these limitations, one can observe a paradigm shift within the machine learning community, with research interests shifting away from increasing the performance of highly parameterized models to exceedingly specific tasks, and towards employing machine learning algorithms in highly diverse domains. This research question can be approached from different angles. For instance, the field of Informed AI investigates the problem of infusing domain knowledge into a machine learning model, by using techniques such as regularization, data augmentation or post-processing. On the other hand, a remarkable number of works in the recent years has focused on developing models that by themselves guarantee a certain degree of versatility and invariance with respect to the domain or problem at hand. Thus, rather than investigating how to provide domain-specific knowledge to machine learning models, these works explore methods that equip the models with the capability of acquiring the knowledge by themselves. This white paper provides an introduction and discussion of this emerging field in machine learning research. To this end, it reviews the role of knowledge in machine learning, and discusses its relation to the concept of invariance, before providing a literature review of the field.
A Generative Map for Image-based Camera Localization
Apr 16, 2019
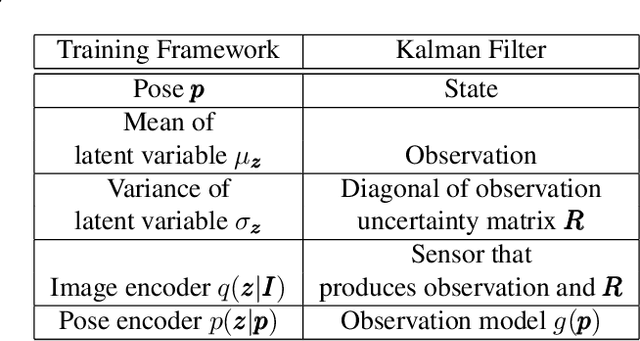

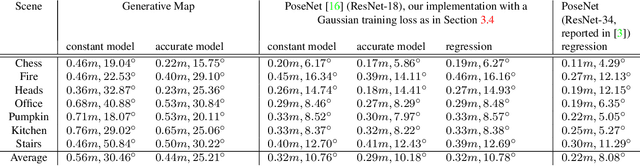
In image-based camera localization systems, information about the environment is usually stored in some representation, which can be referred to as a map. Conventionally, most maps are built upon hand-crafted features. Recently, neural networks have attracted attention as a data-driven map representation, and have shown promising results in visual localization. However, these neural network maps are generally hard to interpret by human. A readable map is not only accessible to humans, but also provides a way to be verified when the ground truth pose is unavailable. To tackle this problem, we propose Generative Map, a new framework for learning human-readable neural network maps, by combining a generative model with the Kalman filter, which also allows it to incorporate additional sensor information such as stereo visual odometry. For evaluation, we use real world images from the 7-Scenes and Oxford RobotCar datasets. We demonstrate that our Generative Map can be queried with a pose of interest from the test sequence to predict an image, which closely resembles the true scene. For localization, we show that Generative Map achieves comparable performance with current regression models. Moreover, our framework is trained completely from scratch, unlike regression models which rely on large ImageNet pretrained networks.