 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generative Map for Image-based Camera Localization
Paper and Code

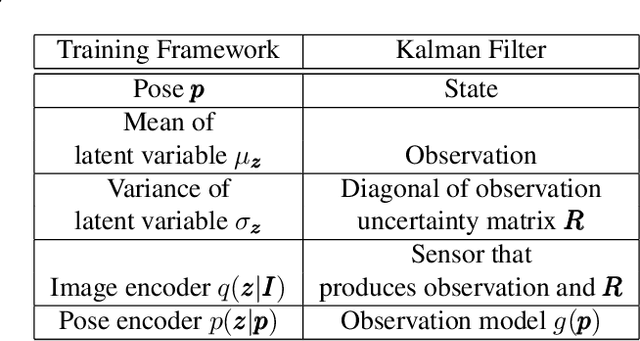

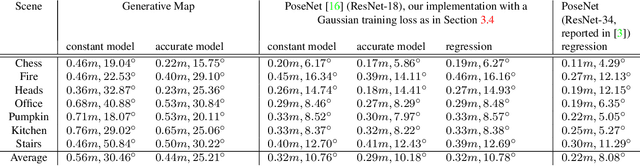
In image-based camera localization systems, information about the environment is usually stored in some representation, which can be referred to as a map. Conventionally, most maps are built upon hand-crafted features. Recently, neural networks have attracted attention as a data-driven map representation, and have shown promising results in visual localization. However, these neural network maps are generally hard to interpret by human. A readable map is not only accessible to humans, but also provides a way to be verified when the ground truth pose is unavailable. To tackle this problem, we propose Generative Map, a new framework for learning human-readable neural network maps, by combining a generative model with the Kalman filter, which also allows it to incorporate additional sensor information such as stereo visual odometry. For evaluation, we use real world images from the 7-Scenes and Oxford RobotCar datasets. We demonstrate that our Generative Map can be queried with a pose of interest from the test sequence to predict an image, which closely resembles the true scene. For localization, we show that Generative Map achieves comparable performance with current regression models. Moreover, our framework is trained completely from scratch, unlike regression models which rely on large ImageNet pretrained networks.