 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePQD: Post-training Quantization for Efficient Diffusion Models
Dec 30, 2024



Diffusionmodels(DMs)havedemonstratedremarkableachievements in synthesizing images of high fidelity and diversity. However, the extensive computational requirements and slow generative speed of diffusion models have limited their widespread adoption. In this paper, we propose a novel post-training quantization for diffusion models (PQD), which is a time-aware optimization framework for diffusion models based on post-training quantization. The proposed framework optimizes the inference process by selecting representative samples and conducting time-aware calibration. Experimental results show that our proposed method is able to directly quantize full-precision diffusion models into 8-bit or 4-bit models while maintaining comparable performance in a training-free manner, achieving a few FID change on ImageNet for unconditional image generation. Our approach demonstrates compatibility and can also be applied to 512x512 text-guided image generation for the first time.
An effective coaxiality error measurement for twist drill based on line structured light sensor
Dec 18, 2021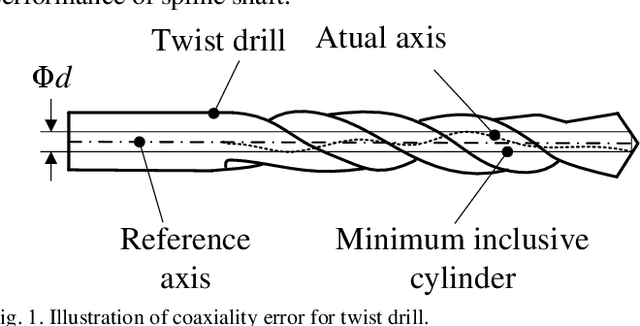
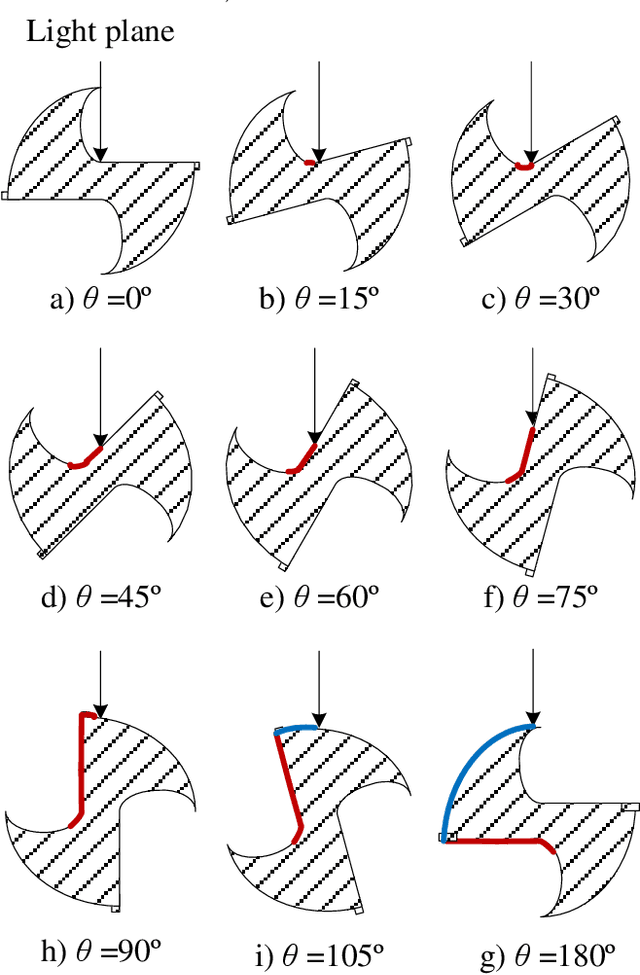
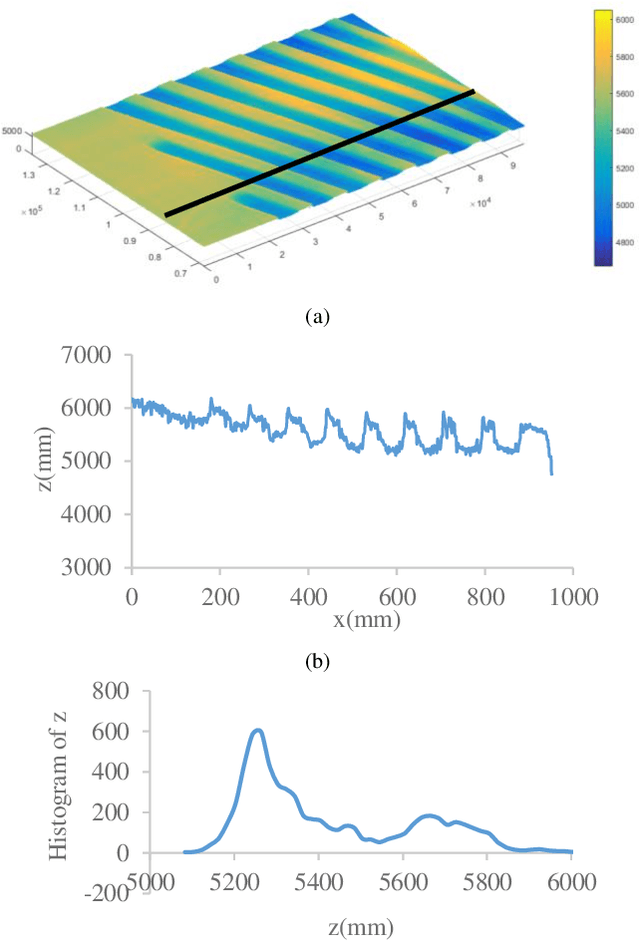
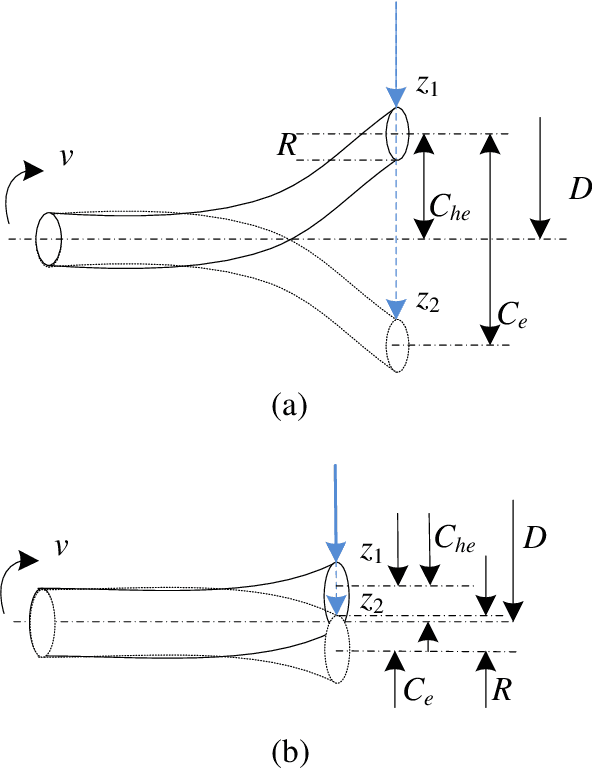
Since the structure of twist drill is complex, it is hard and challenging for its coaxiality error measurement. In this paper, a novel mechanism, framework and method of coaxiality error measurement for twist drill is proposed. The mechanism includes encoder, PLC controller, line structured sensor and high precision turntable. First, profile point cloud data of the twist drill is collected through the line structured light sensor when the drill turns around in the controlling of PLC. Second, a GMM-based point cloud segmentation algorithm based on local depth features is investigated to extract blade back data. To improve the measurement accuracy, a statistical filter is designed to remove outliers during the target region extraction. Then, according to two characteristics of coaxiality error, an axis reconstruction method based on orthogonal synthesis of axisymmetric contour differences is presented, which is facilitated to pre-position the maximum deviation cross sections of the drill axis. Finally, the coaxiality error is measured through fitting the benchmark axis and the axis at the pre-positioned maximum deviation position. At the end, a large number of experiments are carried out, and it shows that our method is accuracy and robust.
A Generative Map for Image-based Camera Localization
Apr 16, 2019
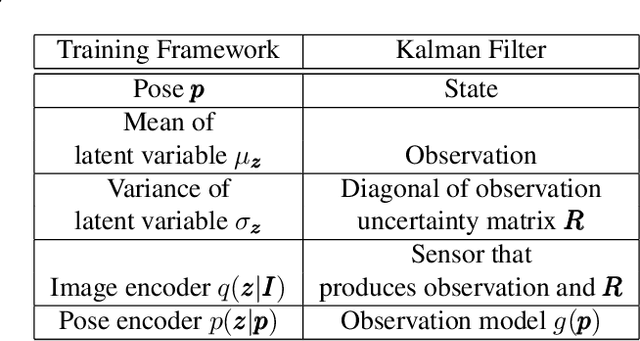

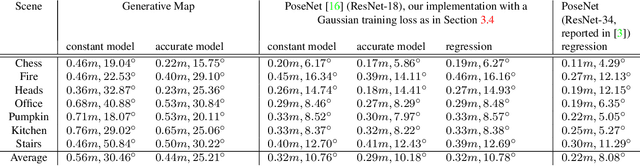
In image-based camera localization systems, information about the environment is usually stored in some representation, which can be referred to as a map. Conventionally, most maps are built upon hand-crafted features. Recently, neural networks have attracted attention as a data-driven map representation, and have shown promising results in visual localization. However, these neural network maps are generally hard to interpret by human. A readable map is not only accessible to humans, but also provides a way to be verified when the ground truth pose is unavailable. To tackle this problem, we propose Generative Map, a new framework for learning human-readable neural network maps, by combining a generative model with the Kalman filter, which also allows it to incorporate additional sensor information such as stereo visual odometry. For evaluation, we use real world images from the 7-Scenes and Oxford RobotCar datasets. We demonstrate that our Generative Map can be queried with a pose of interest from the test sequence to predict an image, which closely resembles the true scene. For localization, we show that Generative Map achieves comparable performance with current regression models. Moreover, our framework is trained completely from scratch, unlike regression models which rely on large ImageNet pretrained networks.