 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsuring Semantics in Weights of Implicit Neural Representations through the Implicit Function Theorem
Jan 30, 2026Weight Space Learning (WSL), which frames neural network weights as a data modality, is an emerging field with potential for tasks like meta-learning or transfer learning. Particularly, Implicit Neural Representations (INRs) provide a convenient testbed, where each set of weights determines the corresponding individual data sample as a mapping from coordinates to contextual values. So far, a precise theoretical explanation for the mechanism of encoding semantics of data into network weights is still missing. In this work, we deploy the Implicit Function Theorem (IFT) to establish a rigorous mapping between the data space and its latent weight representation space. We analyze a framework that maps instance-specific embeddings to INR weights via a shared hypernetwork, achieving performance competitive with existing baselines on downstream classification tasks across 2D and 3D datasets. These findings offer a theoretical lens for future investigations into network weights.
Resource-Efficient Adaptation of Large Language Models for Text Embeddings via Prompt Engineering and Contrastive Fine-tuning
Jul 30, 2025



Large Language Models (LLMs) have become a cornerstone in Natural Language Processing (NLP), achieving impressive performance in text generation. Their token-level representations capture rich, human-aligned semantics. However, pooling these vectors into a text embedding discards crucial information. Nevertheless, many non-generative downstream tasks, such as clustering, classification, or retrieval, still depend on accurate and controllable sentence- or document-level embeddings. We explore several adaptation strategies for pre-trained, decoder-only LLMs: (i) various aggregation techniques for token embeddings, (ii) task-specific prompt engineering, and (iii) text-level augmentation via contrastive fine-tuning. Combining these components yields state-of-the-art performance on the English clustering track of the Massive Text Embedding Benchmark (MTEB). An analysis of the attention map further shows that fine-tuning shifts focus from prompt tokens to semantically relevant words, indicating more effective compression of meaning into the final hidden state. Our experiments demonstrate that LLMs can be effectively adapted as text embedding models through a combination of prompt engineering and resource-efficient contrastive fine-tuning on synthetically generated positive pairs.
Knowledge Augmented Machine Learning with Applications in Autonomous Driving: A Survey
May 10, 2022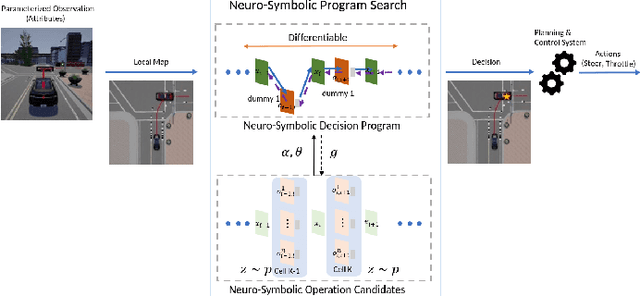
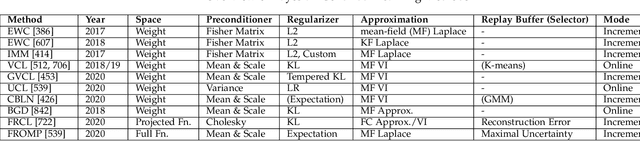
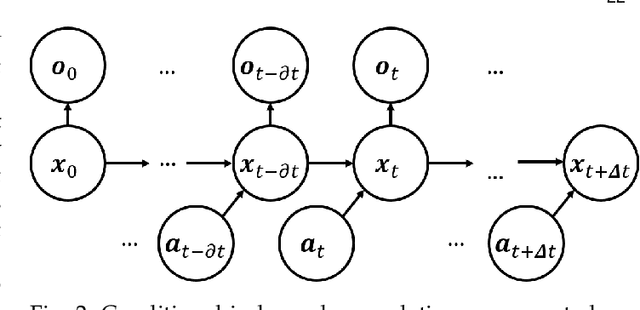
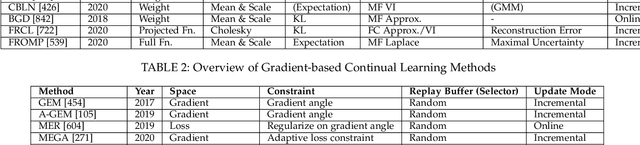
The existence of representative datasets is a prerequisite of many successful artificial intelligence and machine learning models. However, the subsequent application of these models often involves scenarios that are inadequately represented in the data used for training. The reasons for this are manifold and range from time and cost constraints to ethical considerations. As a consequence, the reliable use of these models, especially in safety-critical applications, is a huge challenge. Leveraging additional, already existing sources of knowledge is key to overcome the limitations of purely data-driven approaches, and eventually to increase the generalization capability of these models. Furthermore, predictions that conform with knowledge are crucial for making trustworthy and safe decisions even in underrepresented scenarios. This work provides an overview of existing techniques and methods in the literature that combine data-based models with existing knowledge. The identified approaches are structured according to the categories integration, extraction and conformity. Special attention is given to applications in the field of autonomous driving.
Knowledge as Invariance -- History and Perspectives of Knowledge-augmented Machine Learning
Dec 21, 2020
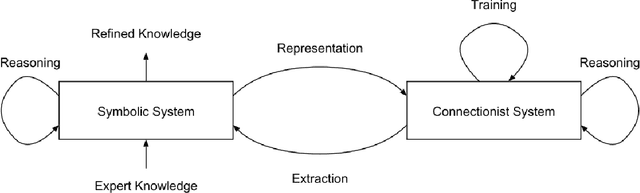
Research in machine learning is at a turning point. While supervised deep learning has conquered the field at a breathtaking pace and demonstrated the ability to solve inference problems with unprecedented accuracy, it still does not quite live up to its name if we think of learning as the process of acquiring knowledge about a subject or problem. Major weaknesses of present-day deep learning models are, for instance, their lack of adaptability to changes of environment or their incapability to perform other kinds of tasks than the one they were trained for. While it is still unclear how to overcome these limitations, one can observe a paradigm shift within the machine learning community, with research interests shifting away from increasing the performance of highly parameterized models to exceedingly specific tasks, and towards employing machine learning algorithms in highly diverse domains. This research question can be approached from different angles. For instance, the field of Informed AI investigates the problem of infusing domain knowledge into a machine learning model, by using techniques such as regularization, data augmentation or post-processing. On the other hand, a remarkable number of works in the recent years has focused on developing models that by themselves guarantee a certain degree of versatility and invariance with respect to the domain or problem at hand. Thus, rather than investigating how to provide domain-specific knowledge to machine learning models, these works explore methods that equip the models with the capability of acquiring the knowledge by themselves. This white paper provides an introduction and discussion of this emerging field in machine learning research. To this end, it reviews the role of knowledge in machine learning, and discusses its relation to the concept of invariance, before providing a literature review of the field.
Metapath- and Entity-aware Graph Neural Network for Recommendation
Oct 22, 2020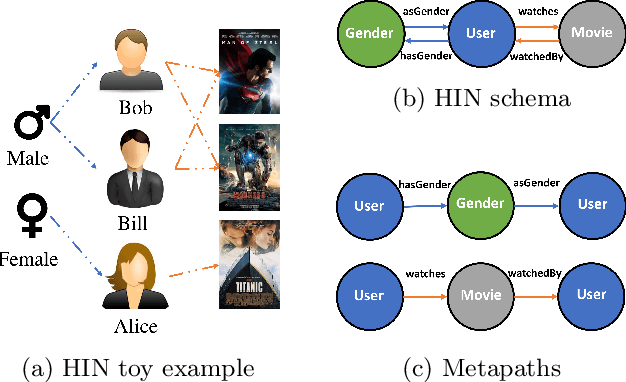
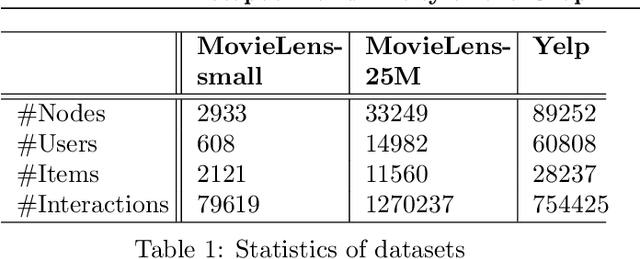
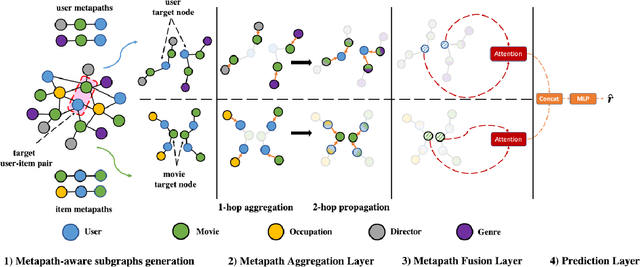
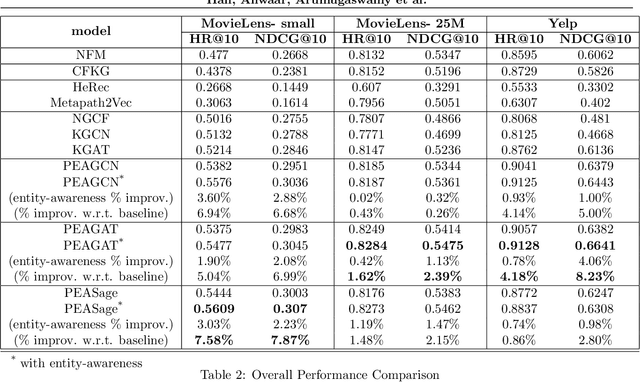
Due to the shallow structure, classic graph neural networks (GNNs) failed in modelling high-order graph structures that deliver critical insights of task relevant relations. The negligence of those insights lead to insufficient distillation of collaborative signals in recommender systems. In this paper, we propose PEAGNN, a unified GNN framework tailored for recommendation tasks, which is capable of exploiting the rich semantics in metapaths. PEAGNN trains multilayer GNNs to perform metapath-aware information aggregation on collaborative subgraphs, $h$-hop subgraphs around the target user-item pairs. After the attentive fusion of aggregated information from different metapaths, a graph-level representation is then extracted for matching score prediction. To leverage the local structure of collaborative subgraphs, we present entity-awareness that regularizes node embedding with the presence of features in a contrastive manner. Moreover, PEAGNN is compatible with the mainstream GNN structures such as GCN, GAT and GraphSage. The empirical analysis on three public datasets demonstrate that our model outperforms or is at least on par with other competitive baselines. Further analysis indicates that trained PEAGNN automatically derives meaningful metapath combinations from the given metapaths.