 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElevating Skeleton-Based Action Recognition with Efficient Multi-Modality Self-Supervision
Sep 21, 2023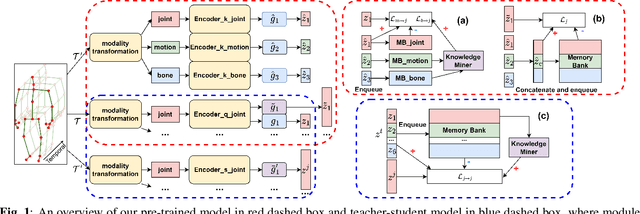

Self-supervised representation learning for human action recognition has developed rapidly in recent years. Most of the existing works are based on skeleton data while using a multi-modality setup. These works overlooked the differences in performance among modalities, which led to the propagation of erroneous knowledge between modalities while only three fundamental modalities, i.e., joints, bones, and motions are used, hence no additional modalities are explored. In this work, we first propose an Implicit Knowledge Exchange Module (IKEM) which alleviates the propagation of erroneous knowledge between low-performance modalities. Then, we further propose three new modalities to enrich the complementary information between modalities. Finally, to maintain efficiency when introducing new modalities, we propose a novel teacher-student framework to distill the knowledge from the secondary modalities into the mandatory modalities considering the relationship constrained by anchors, positives, and negatives, named relational cross-modality knowledge distillation. The experimental results demonstrate the effectiveness of our approach, unlocking the efficient use of skeleton-based multi-modality data. Source code will be made publicly available at https://github.com/desehuileng0o0/IKEM.