 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLevenshtein OCR
Paper and Code
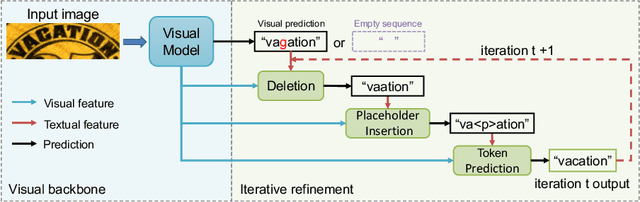
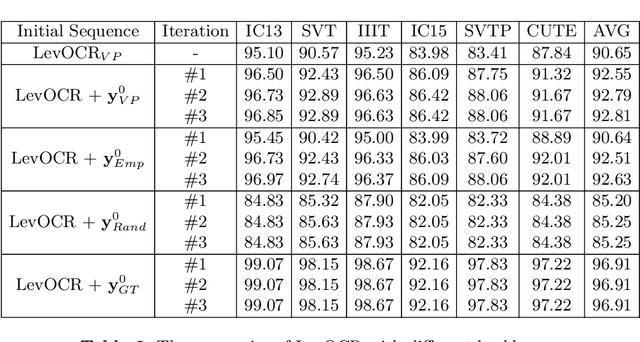
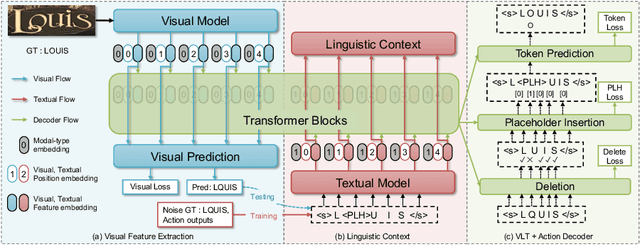
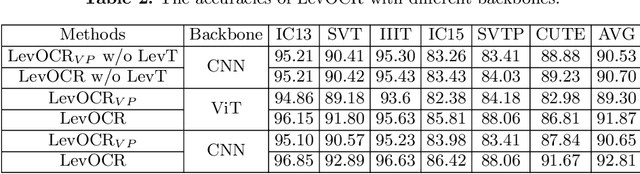
A novel scene text recognizer based on Vision-Language Transformer (VLT) is presented. Inspired by Levenshtein Transformer in the area of NLP, the proposed method (named Levenshtein OCR, and LevOCR for short) explores an alternative way for automatically transcribing textual content from cropped natural images. Specifically, we cast the problem of scene text recognition as an iterative sequence refinement process. The initial prediction sequence produced by a pure vision model is encoded and fed into a cross-modal transformer to interact and fuse with the visual features, to progressively approximate the ground truth. The refinement process is accomplished via two basic character-level operations: deletion and insertion, which are learned with imitation learning and allow for parallel decoding, dynamic length change and good interpretability. The quantitative experiments clearly demonstrate that LevOCR achieves state-of-the-art performances on standard benchmarks and the qualitative analyses verify the effectiveness and advantage of the proposed LevOCR algorithm. Code will be released soon.