 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagicAgent: Towards Generalized Agent Planning
Feb 22, 2026The evolution of Large Language Models (LLMs) from passive text processors to autonomous agents has established planning as a core component of modern intelligence. However, achieving generalized planning remains elusive, not only by the scarcity of high-quality interaction data but also by inherent conflicts across heterogeneous planning tasks. These challenges result in models that excel at isolated tasks yet struggle to generalize, while existing multi-task training attempts suffer from gradient interference. In this paper, we present \textbf{MagicAgent}, a series of foundation models specifically designed for generalized agent planning. We introduce a lightweight and scalable synthetic data framework that generates high-quality trajectories across diverse planning tasks, including hierarchical task decomposition, tool-augmented planning, multi-constraint scheduling, procedural logic orchestration, and long-horizon tool execution. To mitigate training conflicts, we propose a two-stage training paradigm comprising supervised fine-tuning followed by multi-objective reinforcement learning over both static datasets and dynamic environments. Empirical results demonstrate that MagicAgent-32B and MagicAgent-30B-A3B deliver superior performance, achieving accuracies of $75.1\%$ on Worfbench, $55.9\%$ on NaturalPlan, $57.5\%$ on $τ^2$-Bench, $86.9\%$ on BFCL-v3, and $81.2\%$ on ACEBench, as well as strong results on our in-house MagicEval benchmarks. These results substantially outperform existing sub-100B models and even surpass leading closed-source models.
Speech-Language Models with Decoupled Tokenizers and Multi-Token Prediction
Jun 14, 2025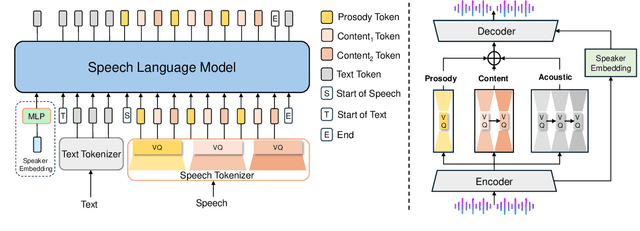
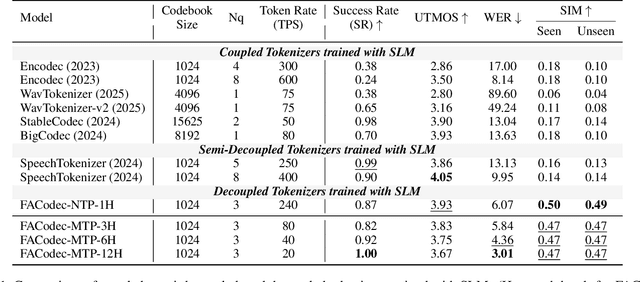
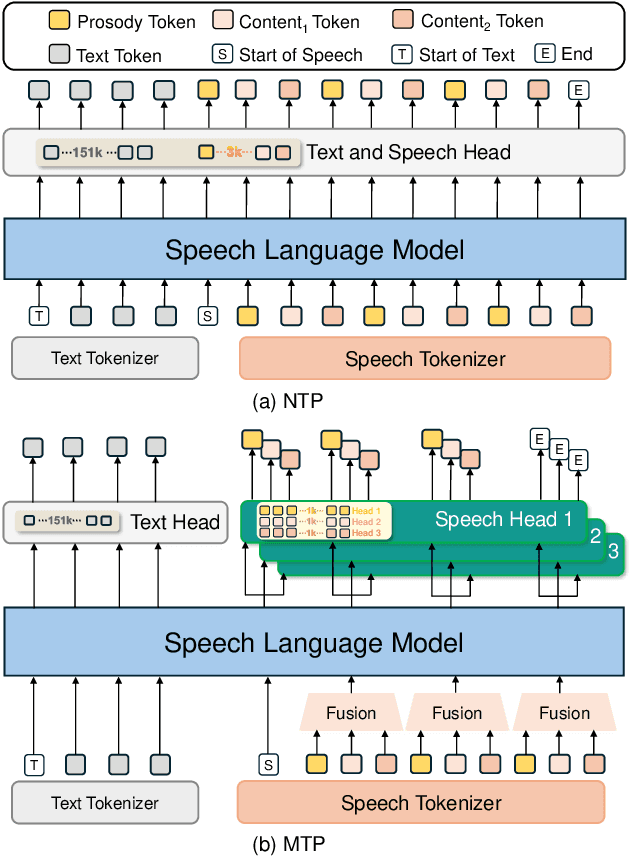
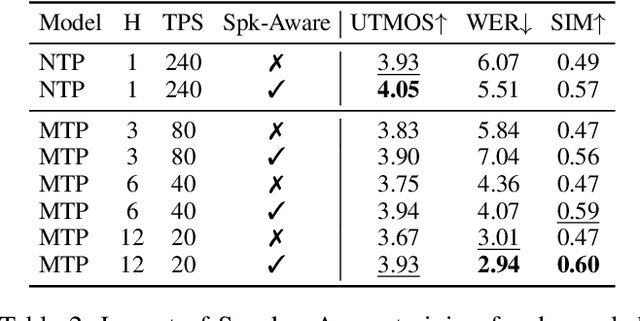
Speech-language models (SLMs) offer a promising path toward unifying speech and text understanding and generation. However, challenges remain in achieving effective cross-modal alignment and high-quality speech generation. In this work, we systematically investigate the impact of key components (i.e., speech tokenizers, speech heads, and speaker modeling) on the performance of LLM-centric SLMs. We compare coupled, semi-decoupled, and fully decoupled speech tokenizers under a fair SLM framework and find that decoupled tokenization significantly improves alignment and synthesis quality. To address the information density mismatch between speech and text, we introduce multi-token prediction (MTP) into SLMs, enabling each hidden state to decode multiple speech tokens. This leads to up to 12$\times$ faster decoding and a substantial drop in word error rate (from 6.07 to 3.01). Furthermore, we propose a speaker-aware generation paradigm and introduce RoleTriviaQA, a large-scale role-playing knowledge QA benchmark with diverse speaker identities. Experiments demonstrate that our methods enhance both knowledge understanding and speaker consistency.
Online Attentive Kernel-Based Temporal Difference Learning
Jan 22, 2022



With rising uncertainty in the real world, online Reinforcement Learning (RL) has been receiving increasing attention due to its fast learning capability and improving data efficiency. However, online RL often suffers from complex Value Function Approximation (VFA) and catastrophic interference, creating difficulty for the deep neural network to be applied to an online RL algorithm in a fully online setting. Therefore, a simpler and more adaptive approach is introduced to evaluate value function with the kernel-based model. Sparse representations are superior at handling interference, indicating that competitive sparse representations should be learnable, non-prior, non-truncated and explicit when compared with current sparse representation methods. Moreover, in learning sparse representations, attention mechanisms are utilized to represent the degree of sparsification, and a smooth attentive function is introduced into the kernel-based VFA. In this paper, we propose an Online Attentive Kernel-Based Temporal Difference (OAKTD) algorithm using two-timescale optimization and provide convergence analysis of our proposed algorithm. Experimental evaluations showed that OAKTD outperformed several Online Kernel-based Temporal Difference (OKTD) learning algorithms in addition to the Temporal Difference (TD) learning algorithm with Tile Coding on public Mountain Car, Acrobot, CartPole and Puddle World tasks.