 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerturbation Inactivation Based Adversarial Defense for Face Recognition
Paper and Code
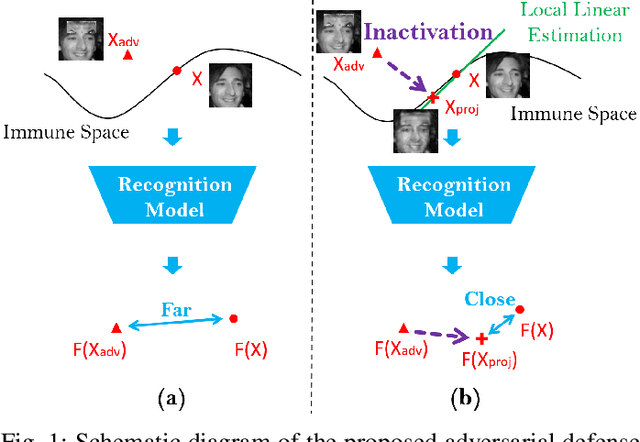
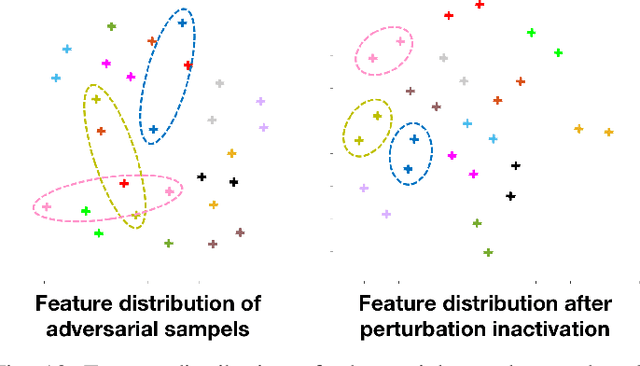

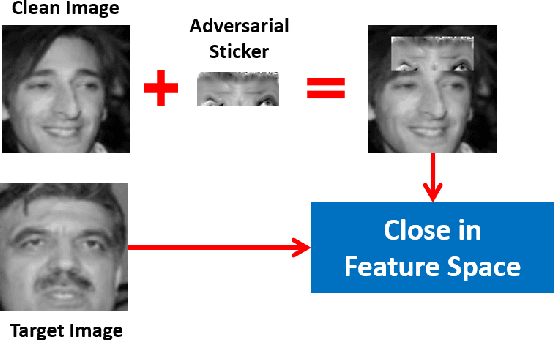
Deep learning-based face recognition models are vulnerable to adversarial attacks. To curb these attacks, most defense methods aim to improve the robustness of recognition models against adversarial perturbations. However, the generalization capacities of these methods are quite limited. In practice, they are still vulnerable to unseen adversarial attacks. Deep learning models are fairly robust to general perturbations, such as Gaussian noises. A straightforward approach is to inactivate the adversarial perturbations so that they can be easily handled as general perturbations. In this paper, a plug-and-play adversarial defense method, named perturbation inactivation (PIN), is proposed to inactivate adversarial perturbations for adversarial defense. We discover that the perturbations in different subspaces have different influences on the recognition model. There should be a subspace, called the immune space, in which the perturbations have fewer adverse impacts on the recognition model than in other subspaces. Hence, our method estimates the immune space and inactivates the adversarial perturbations by restricting them to this subspace. The proposed method can be generalized to unseen adversarial perturbations since it does not rely on a specific kind of adversarial attack method. This approach not only outperforms several state-of-the-art adversarial defense methods but also demonstrates a superior generalization capacity through exhaustive experiments. Moreover, the proposed method can be successfully applied to four commercial APIs without additional training, indicating that it can be easily generalized to existing face recognition systems. The source code is available at https://github.com/RenMin1991/Perturbation-Inactivate