 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDP-Net: Dynamic Programming Guided Deep Neural Network Compression
Mar 21, 2020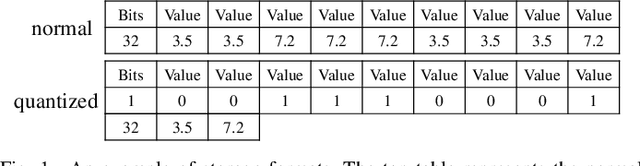


In this work, we propose an effective scheme (called DP-Net) for compressing the deep neural networks (DNNs). It includes a novel dynamic programming (DP) based algorithm to obtain the optimal solution of weight quantization and an optimization process to train a clustering-friendly DNN. Experiments showed that the DP-Net allows larger compression than the state-of-the-art counterparts while preserving accuracy. The largest 77X compression ratio on Wide ResNet is achieved by combining DP-Net with other compression techniques. Furthermore, the DP-Net is extended for compressing a robust DNN model with negligible accuracy loss. At last, a custom accelerator is designed on FPGA to speed up the inference computation with DP-Net.
Single Path One-Shot Neural Architecture Search with Uniform Sampling
Apr 06, 2019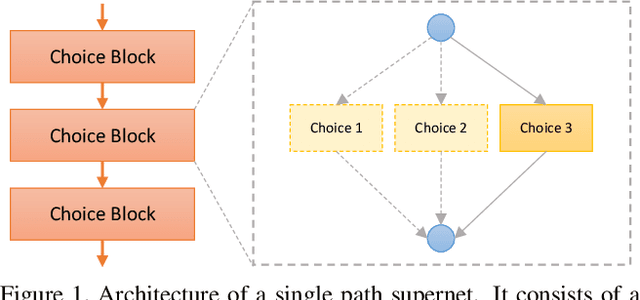
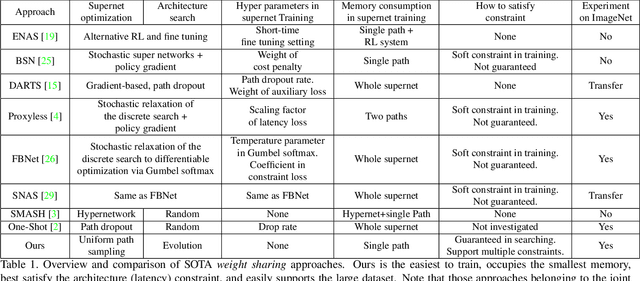
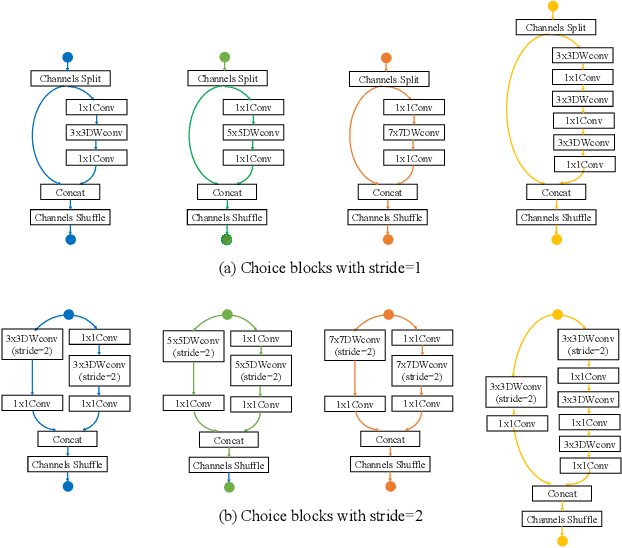
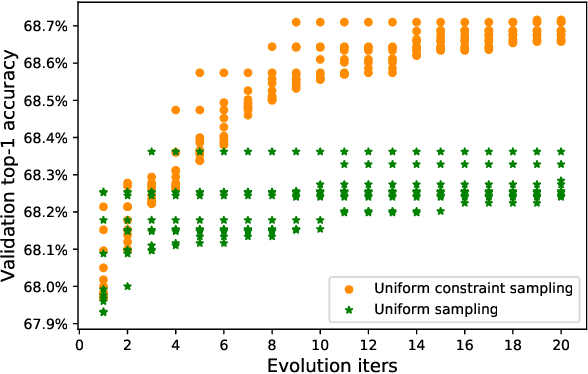
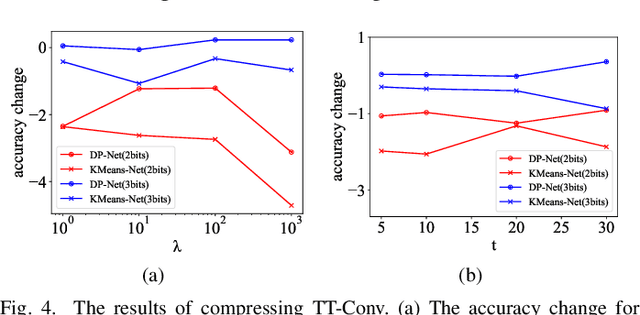
One-shot method is a powerful Neural Architecture Search (NAS) framework, but its training is non-trivial and it is difficult to achieve competitive results on large scale datasets like ImageNet. In this work, we propose a Single Path One-Shot model to address its main challenge in the training. Our central idea is to construct a simplified supernet, Single Path Supernet, which is trained by an uniform path sampling method. All underlying architectures (and their weights) get trained fully and equally. Once we have a trained supernet, we apply an evolutionary algorithm to efficiently search the best-performing architectures without any fine tuning. Comprehensive experiments verify that our approach is flexible and effective. It is easy to train and fast to search. It effortlessly supports complex search spaces (e.g., building blocks, channel, mixed-precision quantization) and different search constraints (e.g., FLOPs, latency). It is thus convenient to use for various needs. It achieves start-of-the-art performance on the large dataset ImageNet.
Meta-SR: A Magnification-Arbitrary Network for Super-Resolution
Apr 03, 2019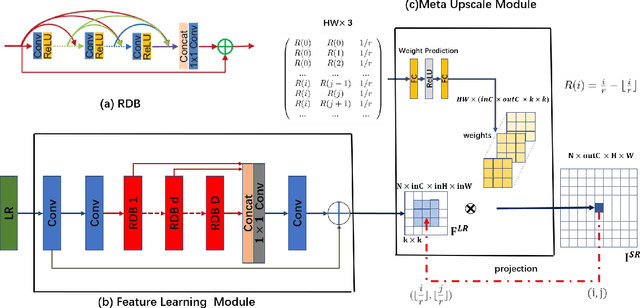
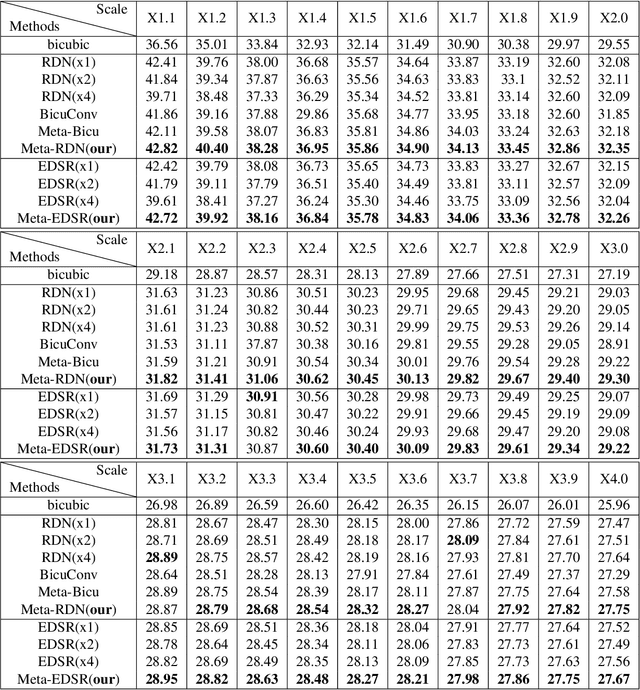
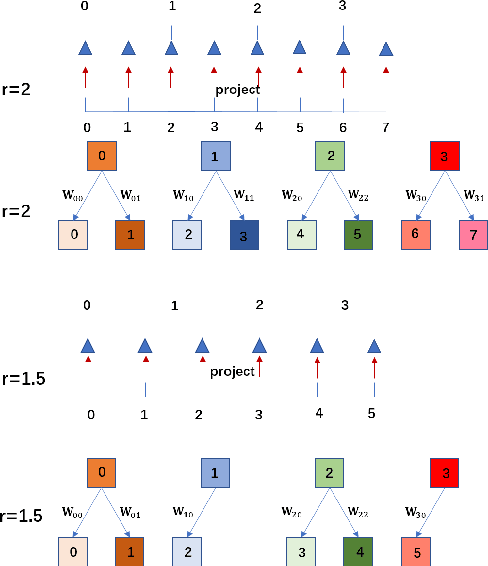
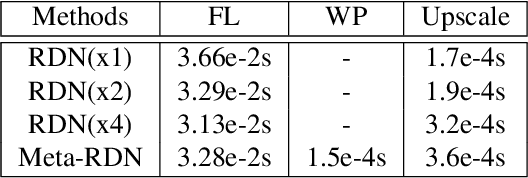
Recent research on super-resolution has achieved great success due to the development of deep convolutional neural networks (DCNNs). However, super-resolution of arbitrary scale factor has been ignored for a long time. Most previous researchers regard super-resolution of different scale factors as independent tasks. They train a specific model for each scale factor which is inefficient in computing, and prior work only take the super-resolution of several integer scale factors into consideration. In this work, we propose a novel method called Meta-SR to firstly solve super-resolution of arbitrary scale factor (including non-integer scale factors) with a single model. In our Meta-SR, the Meta-Upscale Module is proposed to replace the traditional upscale module. For arbitrary scale factor, the Meta-Upscale Module dynamically predicts the weights of the upscale filters by taking the scale factor as input and use these weights to generate the HR image of arbitrary size. For any low-resolution image, our Meta-SR can continuously zoom in it with arbitrary scale factor by only using a single model. We evaluated the proposed method through extensive experiments on widely used benchmark datasets on single image super-resolution. The experimental results show the superiority of our Meta-Upscale.
MetaPruning: Meta Learning for Automatic Neural Network Channel Pruning
Apr 03, 2019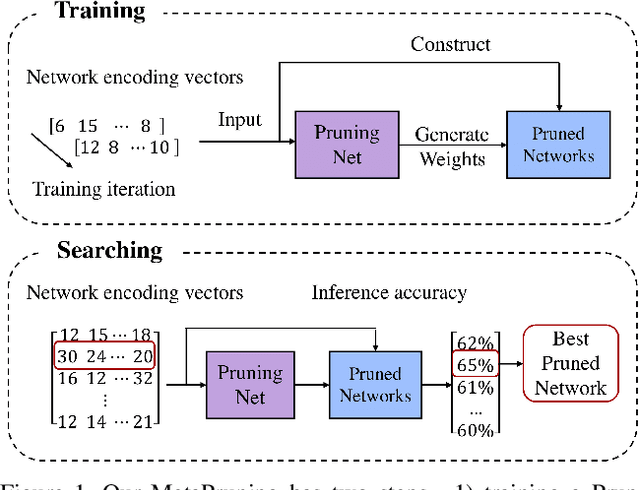
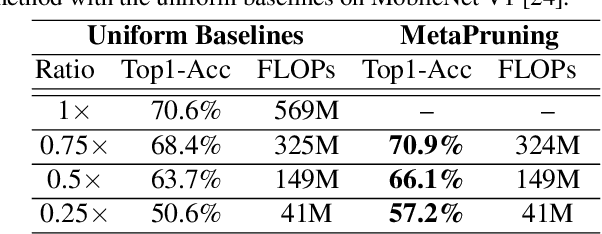
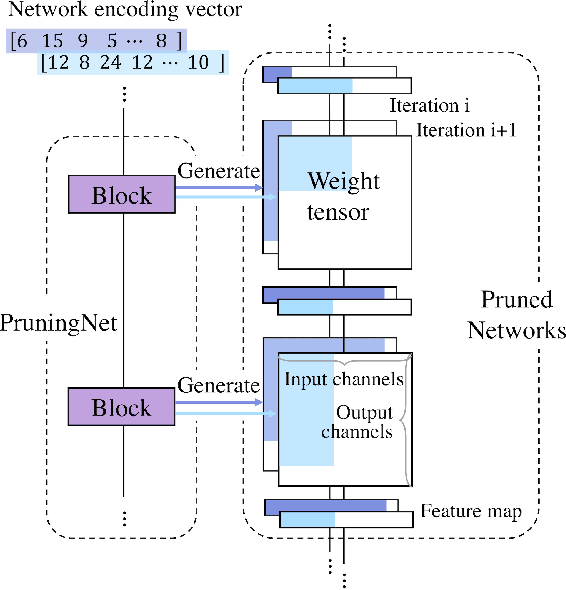
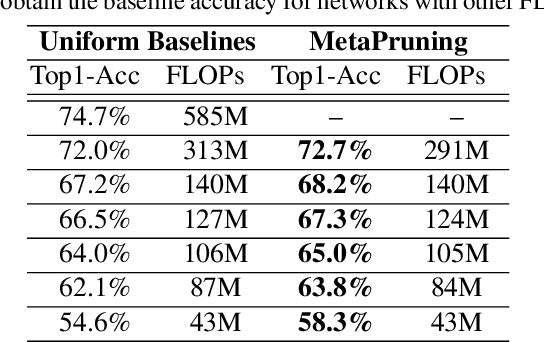
In this paper, we propose a novel meta learning approach for automatic channel pruning of very deep neural networks. We first train a PruningNet, a kind of meta network, which is able to generate weight parameters for any pruned structure given the target network. We use a simple stochastic structure sampling method for training the PruningNet. Then, we apply an evolutionary procedure to search for good-performing pruned networks. The search is highly efficient because the weights are directly generated by the trained PruningNet and we do not need any finetuning. With a single PruningNet trained for the target network, we can search for various Pruned Networks under different constraints with little human participation. We have demonstrated competitive performances on MobileNet V1/V2 networks, up to 9.0/9.9 higher ImageNet accuracy than V1/V2. Compared to the previous state-of-the-art AutoML-based pruning methods, like AMC and NetAdapt, we achieve higher or comparable accuracy under various conditions.