 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep-Learning-Based Pre-Layout Parasitic Capacitance Prediction on SRAM Designs
Jul 09, 2025To achieve higher system energy efficiency, SRAM in SoCs is often customized. The parasitic effects cause notable discrepancies between pre-layout and post-layout circuit simulations, leading to difficulty in converging design parameters and excessive design iterations. Is it possible to well predict the parasitics based on the pre-layout circuit, so as to perform parasitic-aware pre-layout simulation? In this work, we propose a deep-learning-based 2-stage model to accurately predict these parasitics in pre-layout stages. The model combines a Graph Neural Network (GNN) classifier and Multi-Layer Perceptron (MLP) regressors, effectively managing class imbalance of the net parasitics in SRAM circuits. We also employ Focal Loss to mitigate the impact of abundant internal net samples and integrate subcircuit information into the graph to abstract the hierarchical structure of schematics. Experiments on 4 real SRAM designs show that our approach not only surpasses the state-of-the-art model in parasitic prediction by a maximum of 19X reduction of error but also significantly boosts the simulation process by up to 598X speedup.
NAS-Cap: Deep-Learning Driven 3-D Capacitance Extraction with Neural Architecture Search and Data Augmentation
Aug 23, 2024



More accurate capacitance extraction is demanded for designing integrated circuits under advanced process technology. The pattern matching approach and the field solver for capacitance extraction have the drawbacks of inaccuracy and large computational cost, respectively. Recent work \cite{yang2023cnn} proposes a grid-based data representation and a convolutional neural network (CNN) based capacitance models (called CNN-Cap), which opens the third way for 3-D capacitance extraction to get accurate results with much less time cost than field solver. In this work, the techniques of neural architecture search (NAS) and data augmentation are proposed to train better CNN models for 3-D capacitance extraction. Experimental results on datasets from different designs show that the obtained NAS-Cap models achieve remarkably higher accuracy than CNN-Cap, while consuming less runtime for inference and space for model storage. Meanwhile, the transferability of the NAS is validated, as the once searched architecture brought similar error reduction on coupling/total capacitance for the test cases from different design and/or process technology.
Cheating Suffix: Targeted Attack to Text-To-Image Diffusion Models with Multi-Modal Priors
Feb 02, 2024Diffusion models have been widely deployed in various image generation tasks, demonstrating an extraordinary connection between image and text modalities. However, they face challenges of being maliciously exploited to generate harmful or sensitive images by appending a specific suffix to the original prompt. Existing works mainly focus on using single-modal information to conduct attacks, which fails to utilize multi-modal features and results in less than satisfactory performance. Integrating multi-modal priors (MMP), i.e. both text and image features, we propose a targeted attack method named MMP-Attack in this work. Specifically, the goal of MMP-Attack is to add a target object into the image content while simultaneously removing the original object. The MMP-Attack shows a notable advantage over existing works with superior universality and transferability, which can effectively attack commercial text-to-image (T2I) models such as DALL-E 3. To the best of our knowledge, this marks the first successful attempt of transfer-based attack to commercial T2I models. Our code is publicly available at \url{https://github.com/ydc123/MMP-Attack}.
Generating Adversarial Examples with Better Transferability via Masking Unimportant Parameters of Surrogate Model
Apr 14, 2023Deep neural networks (DNNs) have been shown to be vulnerable to adversarial examples. Moreover, the transferability of the adversarial examples has received broad attention in recent years, which means that adversarial examples crafted by a surrogate model can also attack unknown models. This phenomenon gave birth to the transfer-based adversarial attacks, which aim to improve the transferability of the generated adversarial examples. In this paper, we propose to improve the transferability of adversarial examples in the transfer-based attack via masking unimportant parameters (MUP). The key idea in MUP is to refine the pretrained surrogate models to boost the transfer-based attack. Based on this idea, a Taylor expansion-based metric is used to evaluate the parameter importance score and the unimportant parameters are masked during the generation of adversarial examples. This process is simple, yet can be naturally combined with various existing gradient-based optimizers for generating adversarial examples, thus further improving the transferability of the generated adversarial examples. Extensive experiments are conducted to validate the effectiveness of the proposed MUP-based methods.
Boosting the Adversarial Transferability of Surrogate Model with Dark Knowledge
Jun 16, 2022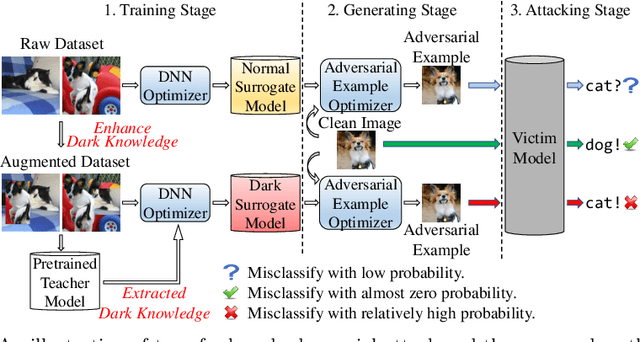
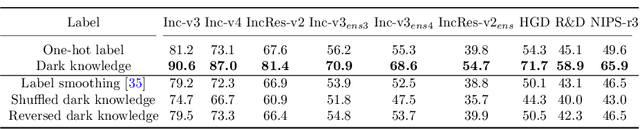
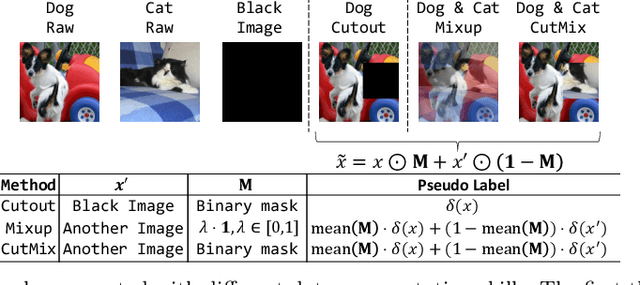
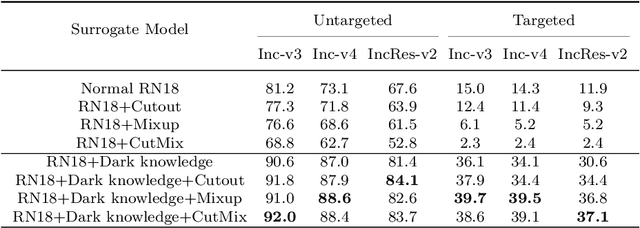
Deep neural networks (DNNs) for image classification are known to be vulnerable to adversarial examples. And, the adversarial examples have transferability, which means an adversarial example for a DNN model can fool another black-box model with a non-trivial probability. This gave birth of the transfer-based adversarial attack where the adversarial examples generated by a pretrained or known model (called surrogate model) are used to conduct black-box attack. There are some work on how to generate the adversarial examples from a given surrogate model to achieve better transferability. However, training a special surrogate model to generate adversarial examples with better transferability is relatively under-explored. In this paper, we propose a method of training a surrogate model with abundant dark knowledge to boost the adversarial transferability of the adversarial examples generated by the surrogate model. This trained surrogate model is named dark surrogate model (DSM), and the proposed method to train DSM consists of two key components: a teacher model extracting dark knowledge and providing soft labels, and the mixing augmentation skill which enhances the dark knowledge of training data. Extensive experiments have been conducted to show that the proposed method can substantially improve the adversarial transferability of surrogate model across different architectures of surrogate model and optimizers for generating adversarial examples. We also show that the proposed method can be applied to other scenarios of transfer-based attack that contain dark knowledge, like face verification.
CNN-Cap: Effective Convolutional Neural Network Based Capacitance Models for Full-Chip Parasitic Extraction
Jul 14, 2021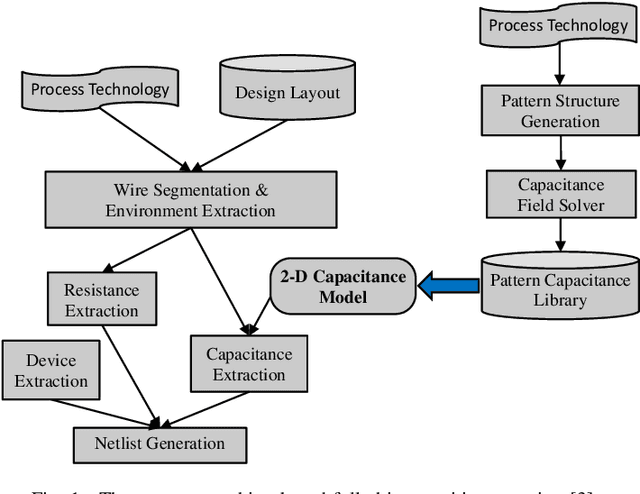
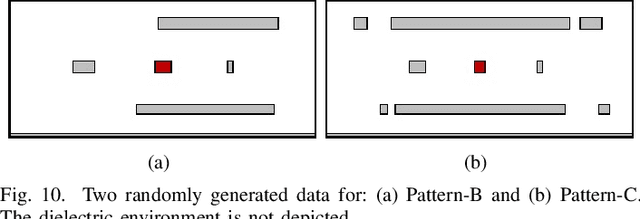
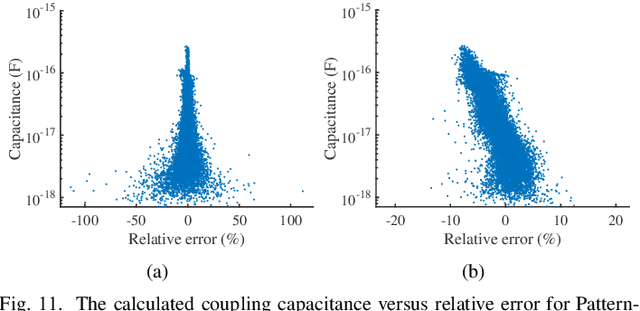
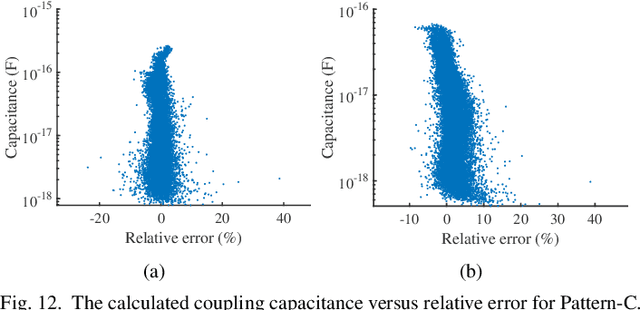
Accurate capacitance extraction is becoming more important for designing integrated circuits under advanced process technology. The pattern matching based full-chip extraction methodology delivers fast computational speed, but suffers from large error, and tedious efforts on building capacitance models of the increasing structure patterns. In this work, we propose an effective method for building convolutional neural network (CNN) based capacitance models (called CNN-Cap) for two-dimensional (2-D) structures in full-chip capacitance extraction. With a novel grid-based data representation, the proposed method is able to model the pattern with a variable number of conductors, so that largely reduce the number of patterns. Based on the ability of ResNet architecture on capturing spatial information and the proposed training skills, the obtained CNN-Cap exhibits much better performance over the multilayer perception neural network based capacitance model while being more versatile. Extensive experiments on a 55nm and a 15nm process technologies have demonstrated that the error of total capacitance produced with CNN-Cap is always within 1.3% and the error of produced coupling capacitance is less than 10% in over 99.5% probability. CNN-Cap runs more than 4000X faster than 2-D field solver on a GPU server, while it consumes negligible memory compared to the look-up table based capacitance model.
Delving into the Adversarial Robustness on Face Recognition
Jul 08, 2020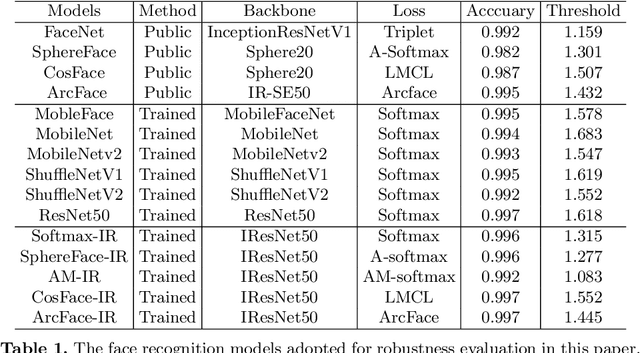


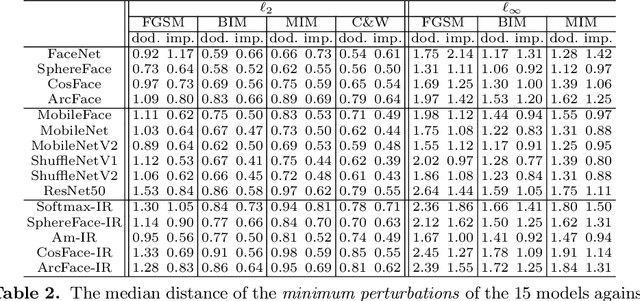
Face recognition has recently made substantial progress and achieved high accuracy on standard benchmarks based on the development of deep convolutional neural networks (CNNs). However, the lack of robustness in deep CNNs to adversarial examples has raised security concerns to enormous face recognition applications. To facilitate a better understanding of the adversarial vulnerability of the existing face recognition models, in this paper we perform comprehensive robustness evaluations, which can be applied as reference for evaluating the robustness of subsequent works on face recognition. We investigate 15 popular face recognition models and evaluate their robustness by using various adversarial attacks as an important surrogate. These evaluations are conducted under diverse adversarial settings, including dodging and impersonation attacks, $\ell_2$ and $\ell_\infty$ attacks, white-box and black-box attacks. We further propose a landmark-guided cutout (LGC) attack method to improve the transferability of adversarial examples for black-box attacks, by considering the special characteristics of face recognition. Based on our evaluations, we draw several important findings, which are crucial for understanding the adversarial robustness and providing insights for future research on face recognition. Code is available at \url{https://github.com/ShawnXYang/Face-Robustness-Benchmark}.
DP-Net: Dynamic Programming Guided Deep Neural Network Compression
Mar 21, 2020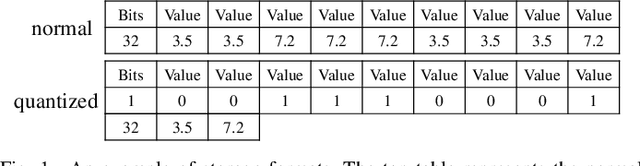

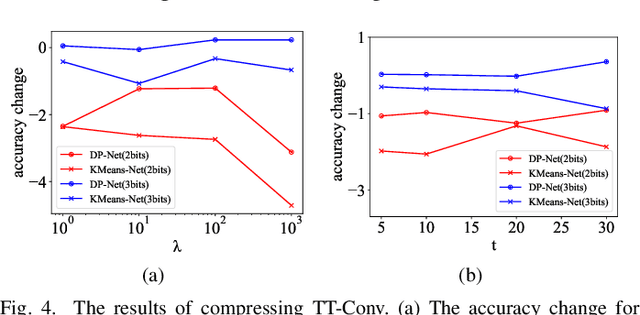

In this work, we propose an effective scheme (called DP-Net) for compressing the deep neural networks (DNNs). It includes a novel dynamic programming (DP) based algorithm to obtain the optimal solution of weight quantization and an optimization process to train a clustering-friendly DNN. Experiments showed that the DP-Net allows larger compression than the state-of-the-art counterparts while preserving accuracy. The largest 77X compression ratio on Wide ResNet is achieved by combining DP-Net with other compression techniques. Furthermore, the DP-Net is extended for compressing a robust DNN model with negligible accuracy loss. At last, a custom accelerator is designed on FPGA to speed up the inference computation with DP-Net.
Pose2Seg: Human Instance Segmentation Without Detection
Mar 28, 2018



The general method of image instance segmentation is to perform the object detection first, and then segment the object from the detection bounding-box. More recently, deep learning methods like Mask R-CNN perform them jointly. However, little research takes into account the uniqueness of the "1human" category, which can be well defined by the pose skeleton. In this paper, we present a brand new pose-based instance segmentation framework for humans which separates instances based on human pose, not proposal region detection. We demonstrate that our pose-based framework can achieve similar accuracy to the detection-based approach, and can moreover better handle occlusion, which is the most challenging problem in the detection-based framework.