 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Emergence of Autonomous Penetration Capabilities in Large Language Model-Powered AI Systems
Jun 11, 2026Nowadays, the autonomous execution of cyberattacks capable of causing substantial real-world harm is widely regarded as one of the critical red lines that frontier AI systems must not cross. Within this broader red-line scenario, autonomous penetration represents a core enabling capability and subtask: the ability of LLM-powered AI systems to independently conduct adversarial operations against a target server without human intervention, identify and exploit vulnerabilities, and obtain unauthorized access or control. A growing body of work has sought to assess the autonomous penetration capabilities of AI systems. However, existing evaluations often employ opaque methodologies, rely on unrealistic or overly simplified penetration-testing scenarios, or provide LLMs with excessive prior knowledge and task-specific guidance, and cannot accurately capture the extent to which modern AI systems can autonomously perform this core capability within broader high-impact cyberattack scenarios. To address these limitations, we construct a new autonomous penetration evaluation framework consisting of two components: target servers and agent scaffolding. Specifically, on the target-server side, we design two levels of target environments based on the number of secure services without known vulnerabilities deployed alongside a vulnerable service: Tier~1 (one secure service) and Tier~2 (three secure services), resulting in a total of 300 target servers. Meanwhile, the agent scaffolding adopts a general-purpose agent architecture equipped with a set of general-purpose cybersecurity tools, without any target-specific prior knowledge. We evaluate 19 open-weight and proprietary LLMs, and find that current models achieve penetration success rates ranging from 10.7% to 69.3%. Moreover, we observe that autonomous penetration capability continues to improve alongside advances in overall model capability.
Parameter-Efficient Adapter Tuning for Tabular-Image Multimodal Learning
Jun 10, 2026Tabular-image multimodal learning aims to improve predictive modeling by jointly using structured tabular attributes and visual data. Although pretrained encoders provide strong modality-specific representations, full fine-tuning can be computationally expensive, while keeping encoders frozen may limit task-specific adaptation. We propose the Tabular-Image Adapter (TI-Adapter), a modality-specific adapter-based fine-tuning framework for efficient multimodal adaptation. TI-Adapter freezes the pretrained tabular encoder and learns an adapter after the extracted tabular embedding, while adapting the image branch with embedding-level and bottleneck-level adapters instead of full fine-tuning. Experiments on 20 tabular-image datasets show that TI-Adapter achieves competitive or better predictive performance than full fine-tuning while using substantially fewer trainable parameters. Ablation studies further demonstrate the importance of adapter placement for balancing performance and practical efficiency.
TILBench: A Systematic Benchmark for Tabular Imbalanced Learning Across Data Regimes
May 14, 2026Imbalanced learning remains a fundamental challenge in tabular data applications. Despite decades of research and numerous proposed algorithms, a systematic empirical understanding of how different imbalanced learning methods behave across diverse data characteristics is still lacking. In particular, it remains unclear how different method families compare in predictive performance, robustness under varying data characteristics, and computational scalability. In this work, we present Tabular Imbalanced Learning Benchmark (TILBench), a large-scale empirical benchmark for tabular imbalanced learning. TILBench evaluates more than 40 representative algorithms across 57 diverse tabular datasets, resulting in over 200000 controlled experiments across a wide range of data characteristics. Our findings show that no single method consistently dominates across all settings; instead, the effectiveness of imbalanced learning methods depends strongly on dataset characteristics and computational constraints. Based on these findings, we provide practical recommendations for selecting appropriate methods in real-world applications.
An Imbalanced Learning-based Sampling Method for Physics-informed Neural Networks
Jan 20, 2025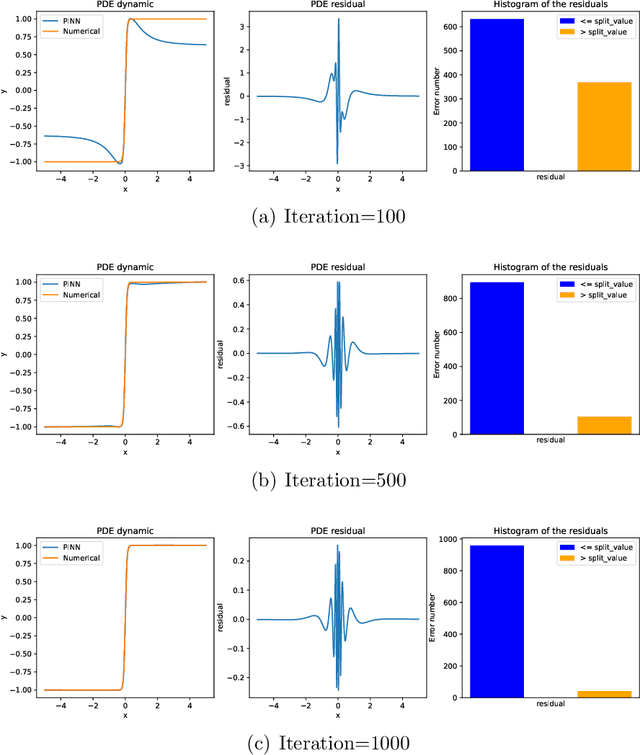
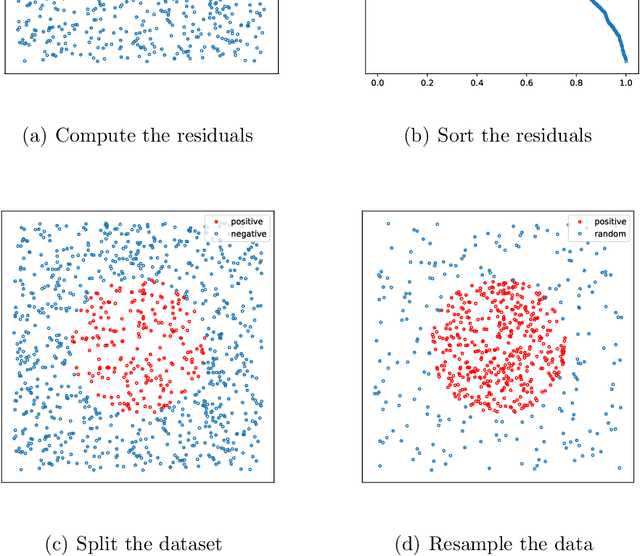

This paper introduces Residual-based Smote (RSmote), an innovative local adaptive sampling technique tailored to improve the performance of Physics-Informed Neural Networks (PINNs) through imbalanced learning strategies. Traditional residual-based adaptive sampling methods, while effective in enhancing PINN accuracy, often struggle with efficiency and high memory consumption, particularly in high-dimensional problems. RSmote addresses these challenges by targeting regions with high residuals and employing oversampling techniques from imbalanced learning to refine the sampling process. Our approach is underpinned by a rigorous theoretical analysis that supports the effectiveness of RSmote in managing computational resources more efficiently. Through extensive evaluations, we benchmark RSmote against the state-of-the-art Residual-based Adaptive Distribution (RAD) method across a variety of dimensions and differential equations. The results demonstrate that RSmote not only achieves or exceeds the accuracy of RAD but also significantly reduces memory usage, making it particularly advantageous in high-dimensional scenarios. These contributions position RSmote as a robust and resource-efficient solution for solving complex partial differential equations, especially when computational constraints are a critical consideration.
Improving GBDT Performance on Imbalanced Datasets: An Empirical Study of Class-Balanced Loss Functions
Jul 19, 2024Class imbalance remains a significant challenge in machine learning, particularly for tabular data classification tasks. While Gradient Boosting Decision Trees (GBDT) models have proven highly effective for such tasks, their performance can be compromised when dealing with imbalanced datasets. This paper presents the first comprehensive study on adapting class-balanced loss functions to three GBDT algorithms across various tabular classification tasks, including binary, multi-class, and multi-label classification. We conduct extensive experiments on multiple datasets to evaluate the impact of class-balanced losses on different GBDT models, establishing a valuable benchmark. Our results demonstrate the potential of class-balanced loss functions to enhance GBDT performance on imbalanced datasets, offering a robust approach for practitioners facing class imbalance challenges in real-world applications. Additionally, we introduce a Python package that facilitates the integration of class-balanced loss functions into GBDT workflows, making these advanced techniques accessible to a wider audience.
Robust-GBDT: A Novel Gradient Boosting Model for Noise-Robust Classification
Oct 08, 2023



Robust boosting algorithms have emerged as alternative solutions to traditional boosting techniques for addressing label noise in classification tasks. However, these methods have predominantly focused on binary classification, limiting their applicability to multi-class tasks. Furthermore, they encounter challenges with imbalanced datasets, missing values, and computational efficiency. In this paper, we establish that the loss function employed in advanced Gradient Boosting Decision Trees (GBDT), particularly Newton's method-based GBDT, need not necessarily exhibit global convexity. Instead, the loss function only requires convexity within a specific region. Consequently, these GBDT models can leverage the benefits of nonconvex robust loss functions, making them resilient to noise. Building upon this theoretical insight, we introduce a new noise-robust boosting model called Robust-GBDT, which seamlessly integrates the advanced GBDT framework with robust losses. Additionally, we enhance the existing robust loss functions and introduce a novel robust loss function, Robust Focal Loss, designed to address class imbalance. As a result, Robust-GBDT generates more accurate predictions, significantly enhancing its generalization capabilities, especially in scenarios marked by label noise and class imbalance. Furthermore, Robust-GBDT is user-friendly and can easily integrate existing open-source code, enabling it to effectively handle complex datasets while improving computational efficiency. Numerous experiments confirm the superiority of Robust-GBDT over other noise-robust methods.
NCART: Neural Classification and Regression Tree for Tabular Data
Jul 23, 2023



Deep learning models have become popular in the analysis of tabular data, as they address the limitations of decision trees and enable valuable applications like semi-supervised learning, online learning, and transfer learning. However, these deep-learning approaches often encounter a trade-off. On one hand, they can be computationally expensive when dealing with large-scale or high-dimensional datasets. On the other hand, they may lack interpretability and may not be suitable for small-scale datasets. In this study, we propose a novel interpretable neural network called Neural Classification and Regression Tree (NCART) to overcome these challenges. NCART is a modified version of Residual Networks that replaces fully-connected layers with multiple differentiable oblivious decision trees. By integrating decision trees into the architecture, NCART maintains its interpretability while benefiting from the end-to-end capabilities of neural networks. The simplicity of the NCART architecture makes it well-suited for datasets of varying sizes and reduces computational costs compared to state-of-the-art deep learning models. Extensive numerical experiments demonstrate the superior performance of NCART compared to existing deep learning models, establishing it as a strong competitor to tree-based models.
Generating Adversarial Examples with Better Transferability via Masking Unimportant Parameters of Surrogate Model
Apr 14, 2023Deep neural networks (DNNs) have been shown to be vulnerable to adversarial examples. Moreover, the transferability of the adversarial examples has received broad attention in recent years, which means that adversarial examples crafted by a surrogate model can also attack unknown models. This phenomenon gave birth to the transfer-based adversarial attacks, which aim to improve the transferability of the generated adversarial examples. In this paper, we propose to improve the transferability of adversarial examples in the transfer-based attack via masking unimportant parameters (MUP). The key idea in MUP is to refine the pretrained surrogate models to boost the transfer-based attack. Based on this idea, a Taylor expansion-based metric is used to evaluate the parameter importance score and the unimportant parameters are masked during the generation of adversarial examples. This process is simple, yet can be naturally combined with various existing gradient-based optimizers for generating adversarial examples, thus further improving the transferability of the generated adversarial examples. Extensive experiments are conducted to validate the effectiveness of the proposed MUP-based methods.
TRBoost: A Generic Gradient Boosting Machine based on Trust-region Method
Oct 08, 2022
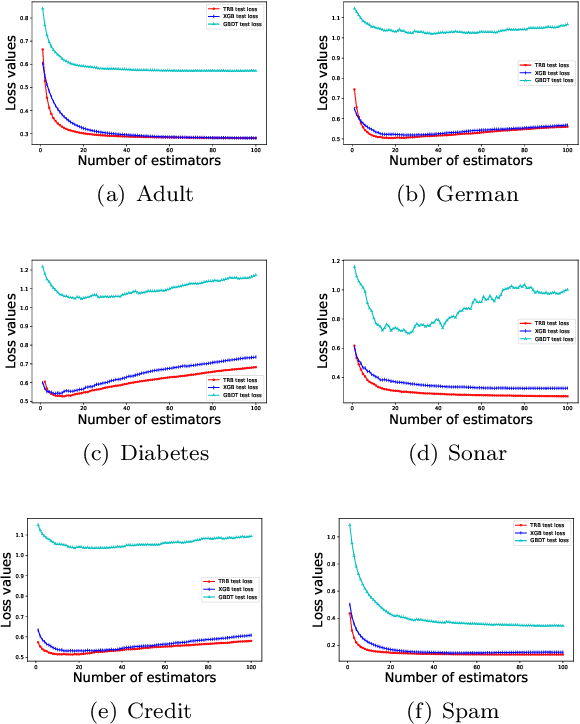
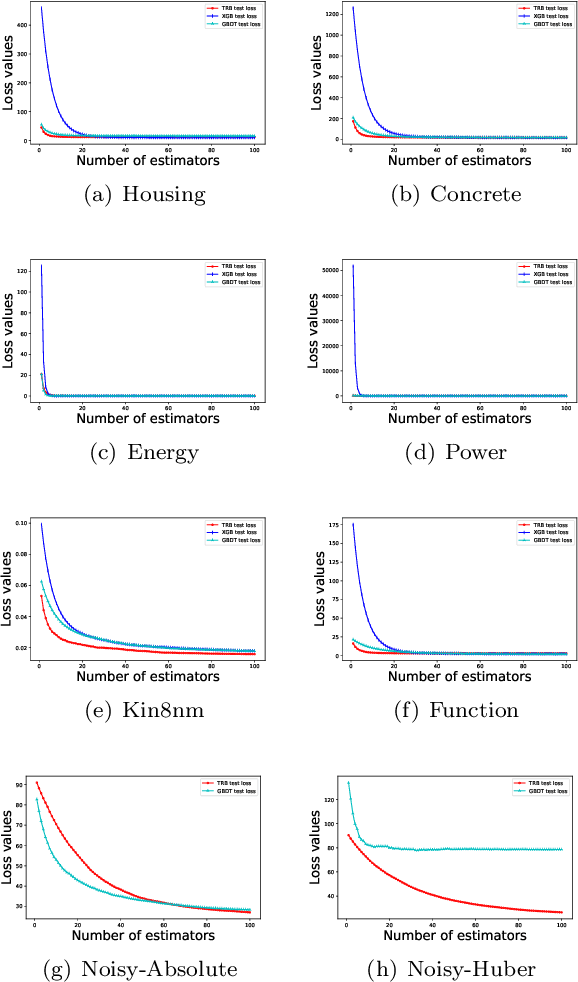
Gradient Boosting Machines (GBMs) are derived from Taylor expansion in functional space and have achieved state-of-the-art results on a variety of problems. However, there is a dilemma for GBMs to maintain a balance between performance and generality. Specifically, gradient descent-based GBMs employ the first-order Taylor expansion to make them appropriate for all loss functions. And Newton's method-based GBMs use the positive hessian information to achieve better performance at the expense of generality. In this paper, a generic Gradient Boosting Machine called Trust-region Boosting (TRBoost) is presented to maintain this balance. In each iteration, we apply a constrained quadratic model to approximate the objective and solve it by the Trust-region algorithm to obtain a new learner. TRBoost offers the benefit that we do not need the hessian to be positive definite, which generalizes GBMs to suit arbitrary loss functions while keeping up the good performance as the second-order algorithm. Several numerical experiments are conducted to confirm that TRBoost is not only as general as the first-order GBMs but also able to get competitive results with the second-order GBMs.