 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPMSqueeze: A Communication Efficient Adam-Preconditioned Momentum SGD Algorithm
Paper and Code
Aug 28, 2020
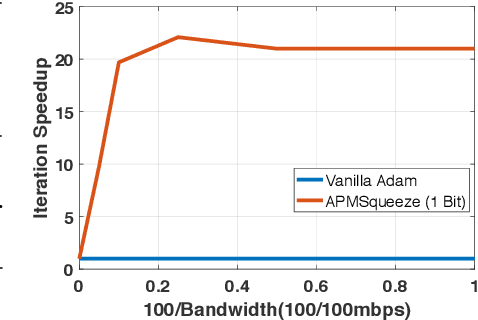
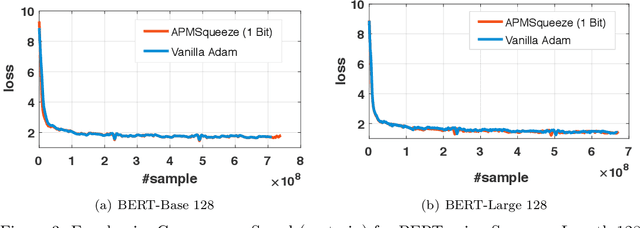
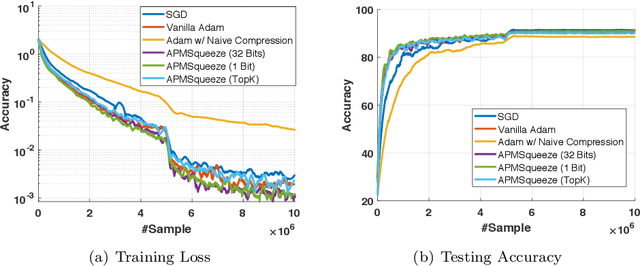
Adam is the important optimization algorithm to guarantee efficiency and accuracy for training many important tasks such as BERT and ImageNet. However, Adam is generally not compatible with information (gradient) compression technology. Therefore, the communication usually becomes the bottleneck for parallelizing Adam. In this paper, we propose a communication efficient {\bf A}DAM {\bf p}reconditioned {\bf M}omentum SGD algorithm-- named APMSqueeze-- through an error compensated method compressing gradients. The proposed algorithm achieves a similar convergence efficiency to Adam in term of epochs, but significantly reduces the running time per epoch. In terms of end-to-end performance (including the full-precision pre-condition step), APMSqueeze is able to provide {sometimes by up to $2-10\times$ speed-up depending on network bandwidth.} We also conduct theoretical analysis on the convergence and efficiency.