 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Framework for Campaign Performance Forecasting in Online Display Advertising
Feb 24, 2022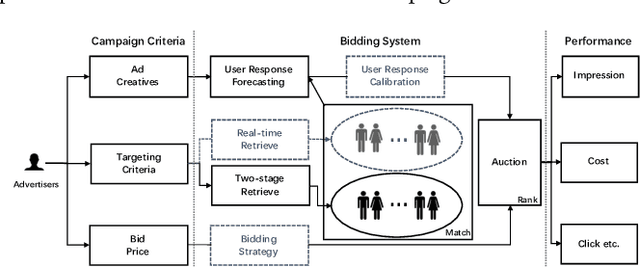

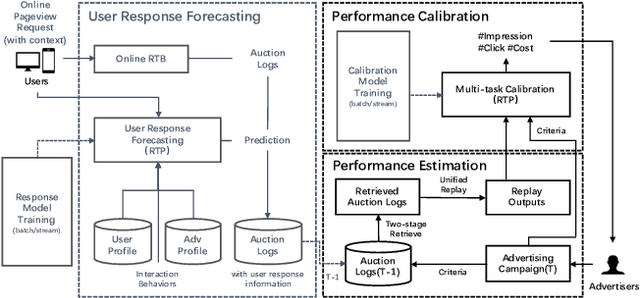

Advertisers usually enjoy the flexibility to choose criteria like target audience, geographic area and bid price when planning an campaign for online display advertising, while they lack forecast information on campaign performance to optimize delivery strategies in advance, resulting in a waste of labour and budget for feedback adjustments. In this paper, we aim to forecast key performance indicators for new campaigns given any certain criteria. Interpretable and accurate results could enable advertisers to manage and optimize their campaign criteria. There are several challenges for this very task. First, platforms usually offer advertisers various criteria when they plan an advertising campaign, it is difficult to estimate campaign performance unifiedly because of the great difference among bidding types. Furthermore, complex strategies applied in bidding system bring great fluctuation on campaign performance, making estimation accuracy an extremely tough problem. To address above challenges, we propose a novel Campaign Performance Forecasting framework, which firstly reproduces campaign performance on historical logs under various bidding types with a unified replay algorithm, in which essential auction processes like match and rank are replayed, ensuring the interpretability on forecast results. Then, we innovatively introduce a multi-task learning method to calibrate the deviation of estimation brought by hard-to-reproduce bidding strategies in replay. The method captures mixture calibration patterns among related forecast indicators to map the estimated results to the true ones, improving both accuracy and efficiency significantly. Experiment results on a dataset from Taobao.com demonstrate that the proposed framework significantly outperforms other baselines by a large margin, and an online A/B test verifies its effectiveness in the real world.
MBCT: Tree-Based Feature-Aware Binning for Individual Uncertainty Calibration
Feb 09, 2022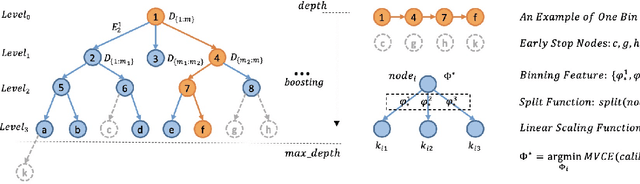
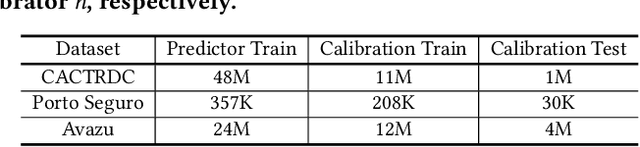
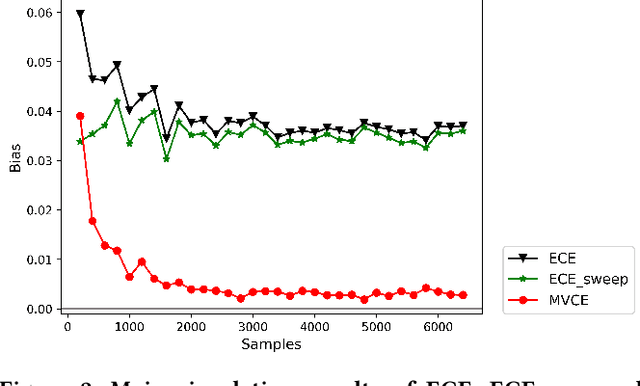
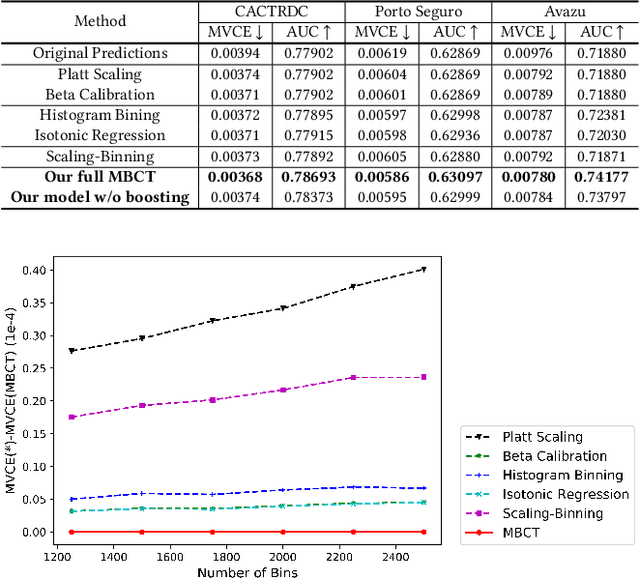
Most machine learning classifiers only concern classification accuracy, while certain applications (such as medical diagnosis, meteorological forecasting, and computation advertising) require the model to predict the true probability, known as a calibrated estimate. In previous work, researchers have developed several calibration methods to post-process the outputs of a predictor to obtain calibrated values, such as binning and scaling methods. Compared with scaling, binning methods are shown to have distribution-free theoretical guarantees, which motivates us to prefer binning methods for calibration. However, we notice that existing binning methods have several drawbacks: (a) the binning scheme only considers the original prediction values, thus limiting the calibration performance; and (b) the binning approach is non-individual, mapping multiple samples in a bin to the same value, and thus is not suitable for order-sensitive applications. In this paper, we propose a feature-aware binning framework, called Multiple Boosting Calibration Trees (MBCT), along with a multi-view calibration loss to tackle the above issues. Our MBCT optimizes the binning scheme by the tree structures of features, and adopts a linear function in a tree node to achieve individual calibration. Our MBCT is non-monotonic, and has the potential to improve order accuracy, due to its learnable binning scheme and the individual calibration. We conduct comprehensive experiments on three datasets in different fields. Results show that our method outperforms all competing models in terms of both calibration error and order accuracy. We also conduct simulation experiments, justifying that the proposed multi-view calibration loss is a better metric in modeling calibration error.