 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistance-Restricted Explanations: Theoretical Underpinnings & Efficient Implementation
May 14, 2024The uses of machine learning (ML) have snowballed in recent years. In many cases, ML models are highly complex, and their operation is beyond the understanding of human decision-makers. Nevertheless, some uses of ML models involve high-stakes and safety-critical applications. Explainable artificial intelligence (XAI) aims to help human decision-makers in understanding the operation of such complex ML models, thus eliciting trust in their operation. Unfortunately, the majority of past XAI work is based on informal approaches, that offer no guarantees of rigor. Unsurprisingly, there exists comprehensive experimental and theoretical evidence confirming that informal methods of XAI can provide human-decision makers with erroneous information. Logic-based XAI represents a rigorous approach to explainability; it is model-based and offers the strongest guarantees of rigor of computed explanations. However, a well-known drawback of logic-based XAI is the complexity of logic reasoning, especially for highly complex ML models. Recent work proposed distance-restricted explanations, i.e. explanations that are rigorous provided the distance to a given input is small enough. Distance-restricted explainability is tightly related with adversarial robustness, and it has been shown to scale for moderately complex ML models, but the number of inputs still represents a key limiting factor. This paper investigates novel algorithms for scaling up the performance of logic-based explainers when computing and enumerating ML model explanations with a large number of inputs.
Feature Necessity & Relevancy in ML Classifier Explanations
Oct 27, 2022Given a machine learning (ML) model and a prediction, explanations can be defined as sets of features which are sufficient for the prediction. In some applications, and besides asking for an explanation, it is also critical to understand whether sensitive features can occur in some explanation, or whether a non-interesting feature must occur in all explanations. This paper starts by relating such queries respectively with the problems of relevancy and necessity in logic-based abduction. The paper then proves membership and hardness results for several families of ML classifiers. Afterwards the paper proposes concrete algorithms for two classes of classifiers. The experimental results confirm the scalability of the proposed algorithms.
Propositional Abduction with Implicit Hitting Sets
Apr 27, 2016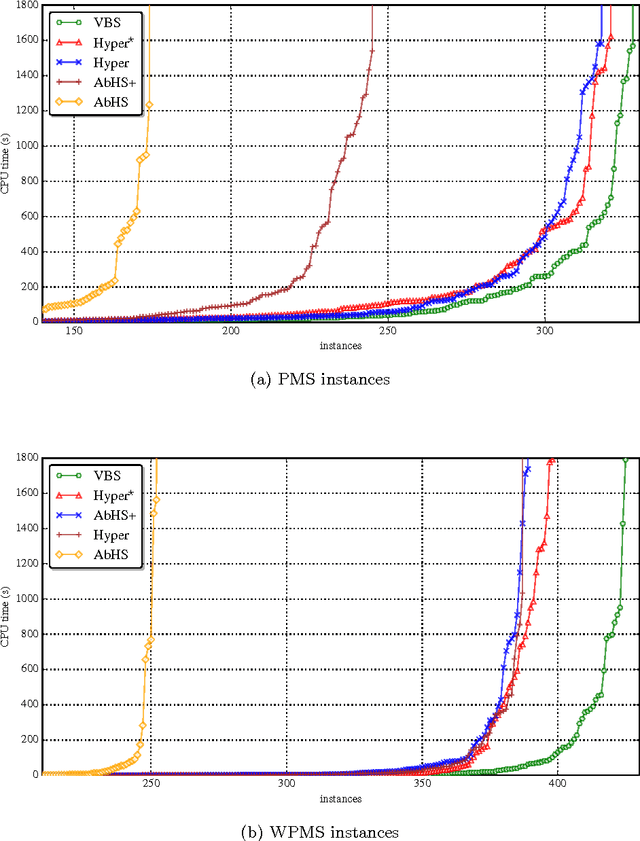

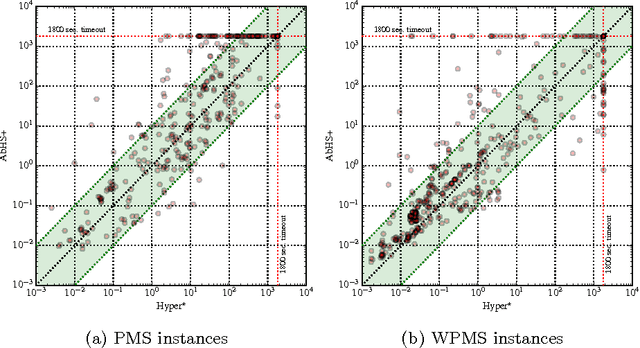

Logic-based abduction finds important applications in artificial intelligence and related areas. One application example is in finding explanations for observed phenomena. Propositional abduction is a restriction of abduction to the propositional domain, and complexity-wise is in the second level of the polynomial hierarchy. Recent work has shown that exploiting implicit hitting sets and propositional satisfiability (SAT) solvers provides an efficient approach for propositional abduction. This paper investigates this earlier work and proposes a number of algorithmic improvements. These improvements are shown to yield exponential reductions in the number of SAT solver calls. More importantly, the experimental results show significant performance improvements compared to the the best approaches for propositional abduction.
SAT-based Preprocessing for MaxSAT (extended version)
Oct 16, 2013
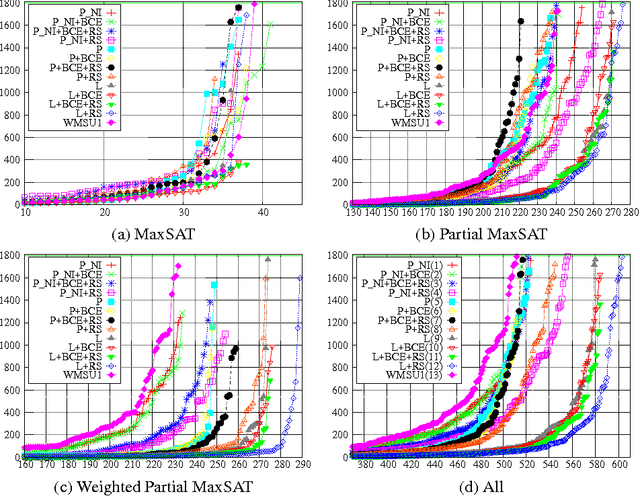

State-of-the-art algorithms for industrial instances of MaxSAT problem rely on iterative calls to a SAT solver. Preprocessing is crucial for the acceleration of SAT solving, and the key preprocessing techniques rely on the application of resolution and subsumption elimination. Additionally, satisfiability-preserving clause elimination procedures are often used. Since MaxSAT computation typically involves a large number of SAT calls, we are interested in whether an input instance to a MaxSAT problem can be preprocessed up-front, i.e. prior to running the MaxSAT solver, rather than (or, in addition to) during each iterative SAT solver call. The key requirement in this setting is that the preprocessing has to be sound, i.e. so that the solution can be reconstructed correctly and efficiently after the execution of a MaxSAT algorithm on the preprocessed instance. While, as we demonstrate in this paper, certain clause elimination procedures are sound for MaxSAT, it is well-known that this is not the case for resolution and subsumption elimination. In this paper we show how to adapt these preprocessing techniques to MaxSAT. To achieve this we recast the MaxSAT problem in a recently introduced labelled-CNF framework, and show that within the framework the preprocessing techniques can be applied soundly. Furthermore, we show that MaxSAT algorithms restated in the framework have a natural implementation on top of an incremental SAT solver. We evaluate the prototype implementation of a MaxSAT algorithm WMSU1 in this setting, demonstrate the effectiveness of preprocessing, and show overall improvement with respect to non-incremental versions of the algorithm on some classes of problems.
On Validating Boolean Optimizers
Sep 13, 2011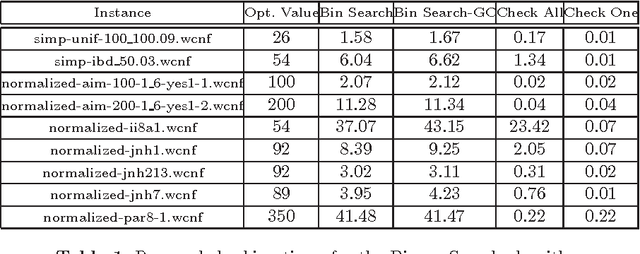
Boolean optimization finds a wide range of application domains, that motivated a number of different organizations of Boolean optimizers since the mid 90s. Some of the most successful approaches are based on iterative calls to an NP oracle, using either linear search, binary search or the identification of unsatisfiable sub-formulas. The increasing use of Boolean optimizers in practical settings raises the question of confidence in computed results. For example, the issue of confidence is paramount in safety critical settings. One way of increasing the confidence of the results computed by Boolean optimizers is to develop techniques for validating the results. Recent work studied the validation of Boolean optimizers based on branch-and-bound search. This paper complements existing work, and develops methods for validating Boolean optimizers that are based on iterative calls to an NP oracle. This entails implementing solutions for validating both satisfiable and unsatisfiable answers from the NP oracle. The work described in this paper can be applied to a wide range of Boolean optimizers, that find application in Pseudo-Boolean Optimization and in Maximum Satisfiability. Preliminary experimental results indicate that the impact of the proposed method in overall performance is negligible.
A Pseudo-Boolean Solution to the Maximum Quartet Consistency Problem
May 02, 2008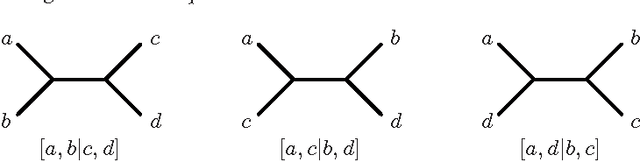



Determining the evolutionary history of a given biological data is an important task in biological sciences. Given a set of quartet topologies over a set of taxa, the Maximum Quartet Consistency (MQC) problem consists of computing a global phylogeny that satisfies the maximum number of quartets. A number of solutions have been proposed for the MQC problem, including Dynamic Programming, Constraint Programming, and more recently Answer Set Programming (ASP). ASP is currently the most efficient approach for optimally solving the MQC problem. This paper proposes encoding the MQC problem with pseudo-Boolean (PB) constraints. The use of PB allows solving the MQC problem with efficient PB solvers, and also allows considering different modeling approaches for the MQC problem. Initial results are promising, and suggest that PB can be an effective alternative for solving the MQC problem.