 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Tackling Explanation Redundancy in Decision Trees
Paper and Code
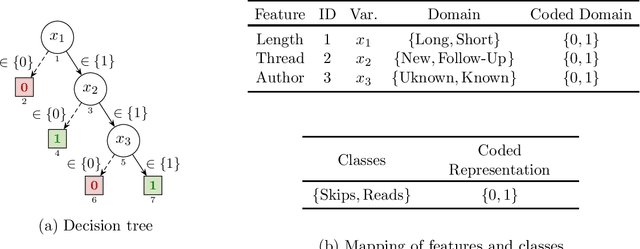



Decision trees (DTs) epitomize the ideal of interpretability of machine learning (ML) models. The interpretability of decision trees motivates explainability approaches by so-called intrinsic interpretability, and it is at the core of recent proposals for applying interpretable ML models in high-risk applications. The belief in DT interpretability is justified by the fact that explanations for DT predictions are generally expected to be succinct. Indeed, in the case of DTs, explanations correspond to DT paths. Since decision trees are ideally shallow, and so paths contain far fewer features than the total number of features, explanations in DTs are expected to be succinct, and hence interpretable. This paper offers both theoretical and experimental arguments demonstrating that, as long as interpretability of decision trees equates with succinctness of explanations, then decision trees ought not be deemed interpretable. The paper introduces logically rigorous path explanations and path explanation redundancy, and proves that there exist functions for which decision trees must exhibit paths with arbitrarily large explanation redundancy. The paper also proves that only a very restricted class of functions can be represented with DTs that exhibit no explanation redundancy. In addition, the paper includes experimental results substantiating that path explanation redundancy is observed ubiquitously in decision trees, including those obtained using different tree learning algorithms, but also in a wide range of publicly available decision trees. The paper also proposes polynomial-time algorithms for eliminating path explanation redundancy, which in practice require negligible time to compute. Thus, these algorithms serve to indirectly attain irreducible, and so succinct, explanations for decision trees.