 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMost General Explanations of Tree Ensembles
May 19, 2025Explainable Artificial Intelligence (XAI) is critical for attaining trust in the operation of AI systems. A key question of an AI system is ``why was this decision made this way''. Formal approaches to XAI use a formal model of the AI system to identify abductive explanations. While abductive explanations may be applicable to a large number of inputs sharing the same concrete values, more general explanations may be preferred for numeric inputs. So-called inflated abductive explanations give intervals for each feature ensuring that any input whose values fall withing these intervals is still guaranteed to make the same prediction. Inflated explanations cover a larger portion of the input space, and hence are deemed more general explanations. But there can be many (inflated) abductive explanations for an instance. Which is the best? In this paper, we show how to find a most general abductive explanation for an AI decision. This explanation covers as much of the input space as possible, while still being a correct formal explanation of the model's behaviour. Given that we only want to give a human one explanation for a decision, the most general explanation gives us the explanation with the broadest applicability, and hence the one most likely to seem sensible. (The paper has been accepted at IJCAI2025 conference.)
Example-Free Learning of Regular Languages with Prefix Queries
Apr 02, 2025Language learning refers to the problem of inferring a mathematical model which accurately represents a formal language. Many language learning algorithms learn by asking certain types of queries about the language being modeled. Language learning is of practical interest in the field of cybersecurity, where it is used to model the language accepted by a program's input parser (also known as its input processor). In this setting, a learner can only query a string of its choice by executing the parser on it, which limits the language learning algorithms that can be used. Most practical parsers can indicate not only whether the string is valid or not, but also where the parsing failed. This extra information can be leveraged into producing a type of query we call the prefix query. Notably, no existing language learning algorithms make use of prefix queries, though some ask membership queries i.e., they ask whether or not a given string is valid. When these approaches are used to learn the language of a parser, the prefix information provided by the parser remains unused. In this work, we present PL*, the first known language learning algorithm to make use of the prefix query, and a novel modification of the classical L* algorithm. We show both theoretically and empirically that PL* is able to learn more efficiently than L* due to its ability to exploit the additional information given by prefix queries over membership queries. Furthermore, we show how PL* can be used to learn the language of a parser, by adapting it to a more practical setting in which prefix queries are the only source of information available to it; that is, it does not have access to any labelled examples or any other types of queries. We demonstrate empirically that, even in this more constrained setting, PL* is still capable of accurately learning a range of languages of practical interest.
LTLf+ and PPLTL+: Extending LTLf and PPLTL to Infinite Traces
Nov 14, 2024We introduce LTLf+ and PPLTL+, two logics to express properties of infinite traces, that are based on the linear-time temporal logics LTLf and PPLTL on finite traces. LTLf+/PPLTL+ use levels of Manna and Pnueli's LTL safety-progress hierarchy, and thus have the same expressive power as LTL. However, they also retain a crucial characteristic of the reactive synthesis problem for the base logics: the game arena for strategy extraction can be derived from deterministic finite automata (DFA). Consequently, these logics circumvent the notorious difficulties associated with determinizing infinite trace automata, typical of LTL reactive synthesis. We present DFA-based synthesis techniques for LTLf+/PPLTL+, and show that synthesis is 2EXPTIME-complete for LTLf+ (matching LTLf) and EXPTIME-complete for PPLTL+ (matching PPLTL). Notably, while PPLTL+ retains the full expressive power of LTL, reactive synthesis is EXPTIME-complete instead of 2EXPTIME-complete. The techniques are also adapted to optimally solve satisfiability, validity, and model-checking, to get EXPSPACE-complete for LTLf+ (extending a recent result for the guarantee level using LTLf), and PSPACE-complete for PPLTL+.
LTLf Synthesis Under Environment Specifications for Reachability and Safety Properties
Aug 29, 2023In this paper, we study LTLf synthesis under environment specifications for arbitrary reachability and safety properties. We consider both kinds of properties for both agent tasks and environment specifications, providing a complete landscape of synthesis algorithms. For each case, we devise a specific algorithm (optimal wrt complexity of the problem) and prove its correctness. The algorithms combine common building blocks in different ways. While some cases are already studied in literature others are studied here for the first time.
Sufficient reasons for classifier decisions in the presence of constraints
May 12, 2021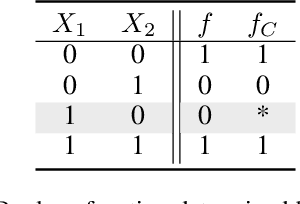
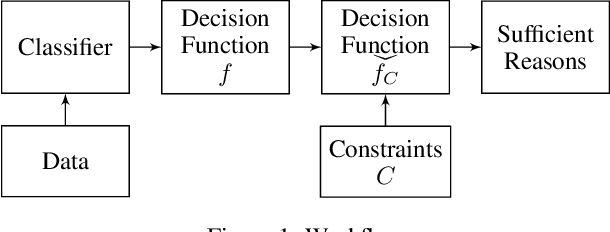
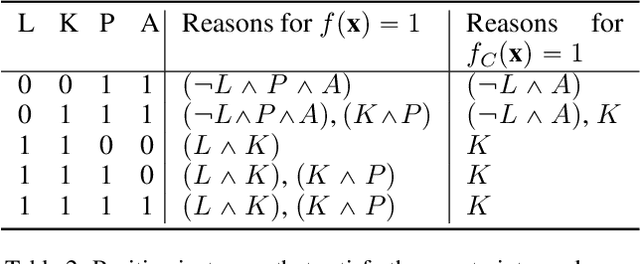
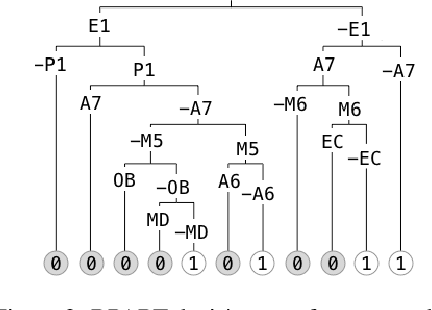
Recent work has unveiled a theory for reasoning about the decisions made by binary classifiers: a classifier describes a Boolean function, and the reasons behind an instance being classified as positive are the prime-implicants of the function that are satisfied by the instance. One drawback of these works is that they do not explicitly treat scenarios where the underlying data is known to be constrained, e.g., certain combinations of features may not exist, may not be observable, or may be required to be disregarded. We propose a more general theory, also based on prime-implicants, tailored to taking constraints into account. The main idea is to view classifiers in the presence of constraints as describing partial Boolean functions, i.e., that are undefined on instances that do not satisfy the constraints. We prove that this simple idea results in reasons that are no less (and sometimes more) succinct. That is, not taking constraints into account (e.g., ignored, or taken as negative instances) results in reasons that are subsumed by reasons that do take constraints into account. We illustrate this improved parsimony on synthetic classifiers and classifiers learned from real data.
Equilibria for Games with Combined Qualitative and Quantitative Objectives
Aug 13, 2020
The overall aim of our research is to develop techniques to reason about the equilibrium properties of multi-agent systems. We model multi-agent systems as concurrent games, in which each player is a process that is assumed to act independently and strategically in pursuit of personal preferences. In this article, we study these games in the context of finite-memory strategies, and we assume players' preferences are defined by a qualitative and a quantitative objective, which are related by a lexicographic order: a player first prefers to satisfy its qualitative objective (given as a formula of Linear Temporal Logic) and then prefers to minimise costs (given by a mean-payoff function). Our main result is that deciding the existence of a strict epsilon Nash equilibrium in such games is 2ExpTime-complete (and hence decidable), even if players' deviations are implemented as infinite-memory strategies.
Stochastic Fairness and Language-Theoretic Fairness in Planning on Nondeterministic Domains
Dec 24, 2019
We address two central notions of fairness in the literature of planning on nondeterministic fully observable domains. The first, which we call stochastic fairness, is classical, and assumes an environment which operates probabilistically using possibly unknown probabilities. The second, which is language-theoretic, assumes that if an action is taken from a given state infinitely often then all its possible outcomes should appear infinitely often (we call this state-action fairness). While the two notions coincide for standard reachability goals, they diverge for temporally extended goals. This important difference has been overlooked in the planning literature, and we argue has led to confusion in a number of published algorithms which use reductions that were stated for state-action fairness, for which they are incorrect, while being correct for stochastic fairness. We remedy this and provide an optimal sound and complete algorithm for solving state-action fair planning for LTL/LTLf goals, as well as a correct proof of the lower bound of the goal-complexity (our proof is general enough that it provides new proofs also for the no-fairness and stochastic-fairness cases). Overall, we show that stochastic fairness is better behaved than state-action fairness.
Generalized Planning: Non-Deterministic Abstractions and Trajectory Constraints
Sep 26, 2019
We study the characterization and computation of general policies for families of problems that share a structure characterized by a common reduction into a single abstract problem. Policies $\mu$ that solve the abstract problem P have been shown to solve all problems Q that reduce to P provided that $\mu$ terminates in Q. In this work, we shed light on why this termination condition is needed and how it can be removed. The key observation is that the abstract problem P captures the common structure among the concrete problems Q that is local (Markovian) but misses common structure that is global. We show how such global structure can be captured by means of trajectory constraints that in many cases can be expressed as LTL formulas, thus reducing generalized planning to LTL synthesis. Moreover, for a broad class of problems that involve integer variables that can be increased or decreased, trajectory constraints can be compiled away, reducing generalized planning to fully observable non-deterministic planning.
Changing Observations in Epistemic Temporal Logic
Sep 03, 2018

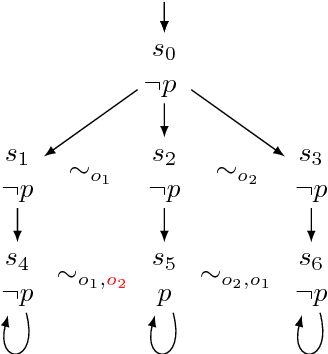
We study dynamic changes of agents' observational power in logics of knowledge and time. We consider CTL*K, the extension of CTL* with knowledge operators, and enrich it with a new operator that models a change in an agent's way of observing the system. We extend the classic semantics of knowledge for perfect-recall agents to account for changes of observation, and we show that this new operator strictly increases the expressivity of CTL*K. We reduce the model-checking problem for our logic to that for CTL*K, which is known to be decidable. This provides a solution to the model-checking problem for our logic, but its complexity is not optimal. Indeed we provide a direct decision procedure with better complexity.
Planning and Synthesis Under Assumptions
Jul 18, 2018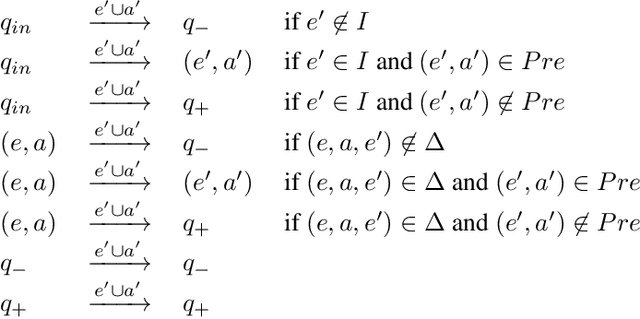
In Reasoning about Action and Planning, one synthesizes the agent plan by taking advantage of the assumption on how the environment works (that is, one exploits the environment's effects, its fairness, its trajectory constraints). In this paper we study this form of synthesis in detail. We consider assumptions as constraints on the possible strategies that the environment can have in order to respond to the agent's actions. Such constraints may be given in the form of a planning domain (or action theory), as linear-time formulas over infinite or finite runs, or as a combination of the two (e.g., FOND under fairness). We argue though that not all assumption specifications are meaningful: they need to be consistent, which means that there must exist an environment strategy fulfilling the assumption in spite of the agent actions. For such assumptions, we study how to do synthesis/planning for agent goals, ranging from a classical reachability to goal on traces specified in LTL and LTLf/LDLf, characterizing the problem both mathematically and algorithmically.