 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models are Better Bug Detector Through Code-Pair Classification
Paper and Code
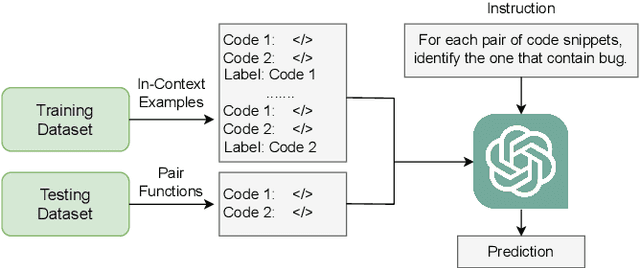
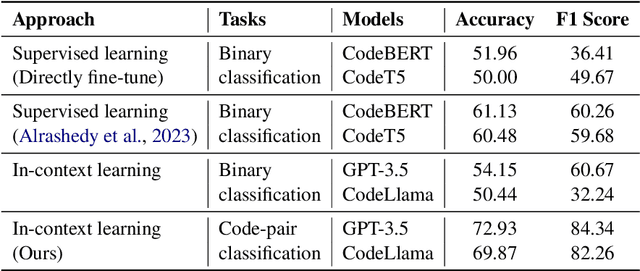
Large language models (LLMs) such as GPT-3.5 and CodeLlama are powerful models for code generation and understanding. Fine-tuning these models comes with a high computational cost and requires a large labeled dataset. Alternatively, in-context learning techniques allow models to learn downstream tasks with only a few examples. Recently, researchers have shown how in-context learning performs well in bug detection and repair. In this paper, we propose code-pair classification task in which both the buggy and non-buggy versions are given to the model, and the model identifies the buggy ones. We evaluate our task in real-world dataset of bug detection and two most powerful LLMs. Our experiments indicate that an LLM can often pick the buggy from the non-buggy version of the code, and the code-pair classification task is much easier compared to be given a snippet and deciding if and where a bug exists.