 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemorization and Generalization in Neural Code Intelligence Models
Paper and Code

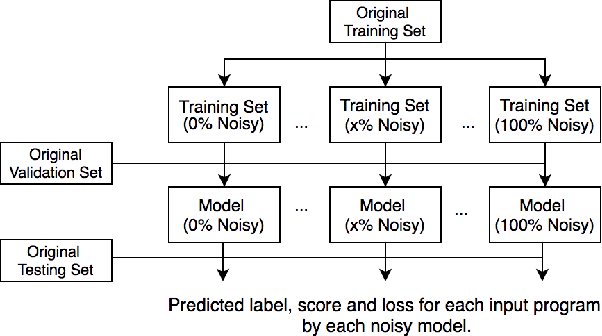
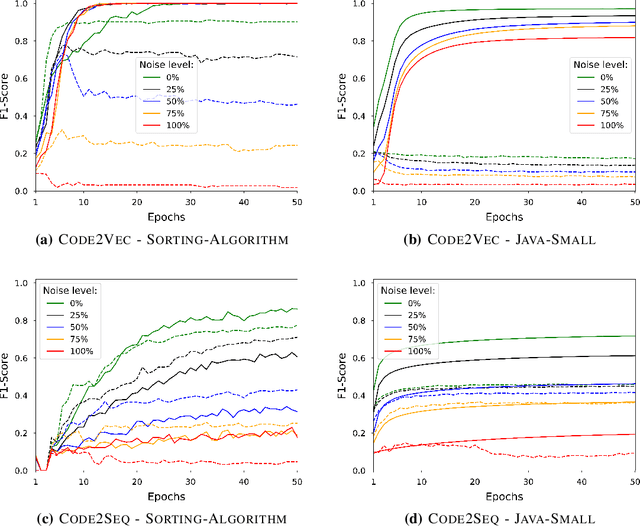
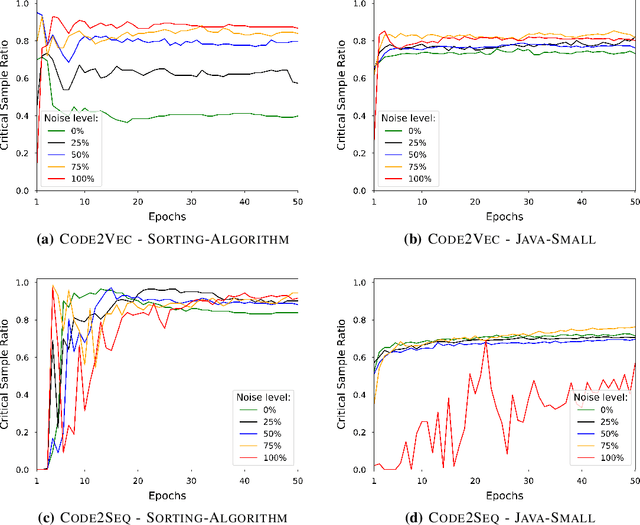
Deep Neural Networks (DNN) are increasingly commonly used in software engineering and code intelligence tasks. These are powerful tools that are capable of learning highly generalizable patterns from large datasets through millions of parameters. At the same time, training DNNs means walking a knife's edges, because their large capacity also renders them prone to memorizing data points. While traditionally thought of as an aspect of over-training, recent work suggests that the memorization risk manifests especially strongly when the training datasets are noisy and memorization is the only recourse. Unfortunately, most code intelligence tasks rely on rather noise-prone and repetitive data sources, such as GitHub, which, due to their sheer size, cannot be manually inspected and evaluated. We evaluate the memorization and generalization tendencies in neural code intelligence models through a case study across several benchmarks and model families by leveraging established approaches from other fields that use DNNs, such as introducing targeted noise into the training dataset. In addition to reinforcing prior general findings about the extent of memorization in DNNs, our results shed light on the impact of noisy dataset in training.