 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Large Language Models Memorizing Bug Benchmarks?
Nov 20, 2024
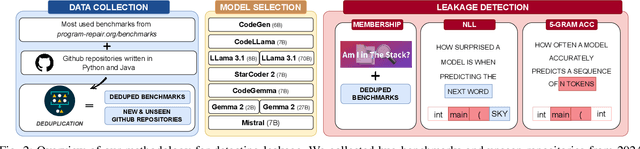
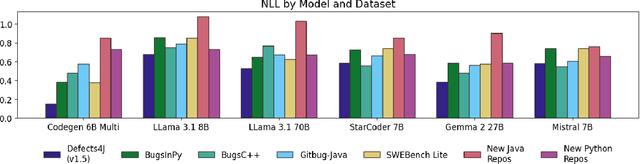
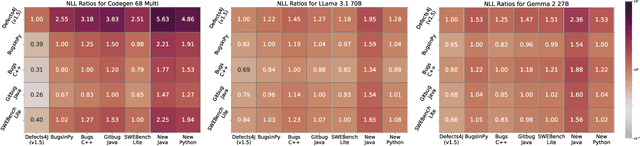
Large Language Models (LLMs) have become integral to various software engineering tasks, including code generation, bug detection, and repair. To evaluate model performance in these domains, numerous bug benchmarks containing real-world bugs from software projects have been developed. However, a growing concern within the software engineering community is that these benchmarks may not reliably reflect true LLM performance due to the risk of data leakage. Despite this concern, limited research has been conducted to quantify the impact of potential leakage. In this paper, we systematically evaluate popular LLMs to assess their susceptibility to data leakage from widely used bug benchmarks. To identify potential leakage, we use multiple metrics, including a study of benchmark membership within commonly used training datasets, as well as analyses of negative log-likelihood and n-gram accuracy. Our findings show that certain models, in particular codegen-multi, exhibit significant evidence of memorization in widely used benchmarks like Defects4J, while newer models trained on larger datasets like LLaMa 3.1 exhibit limited signs of leakage. These results highlight the need for careful benchmark selection and the adoption of robust metrics to adequately assess models capabilities.
Understanding Misconfigurations in ROS: An Empirical Study and Current Approaches
Jul 27, 2024
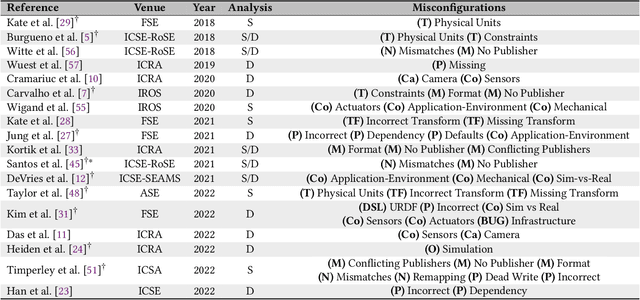
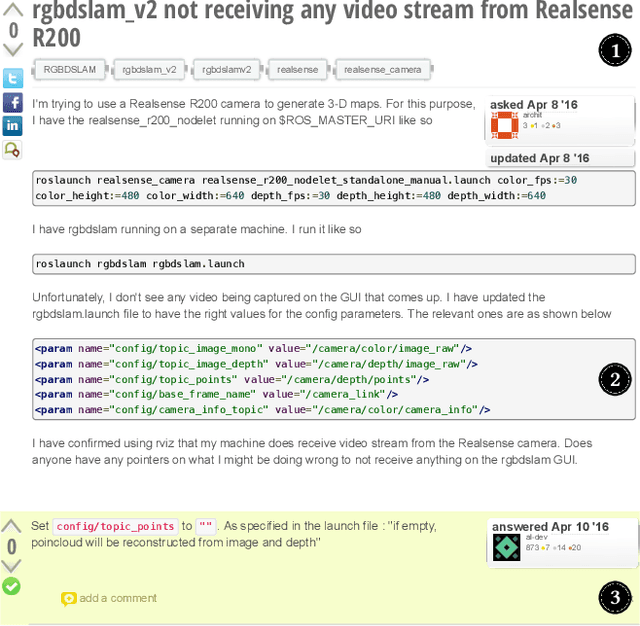
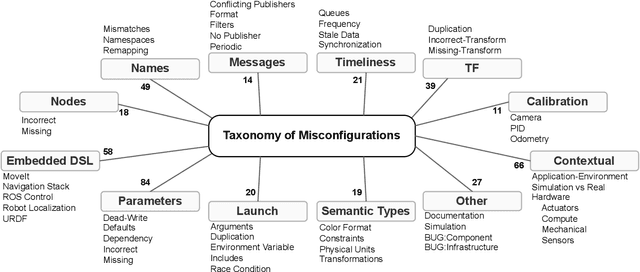
The Robot Operating System (ROS) is a popular framework and ecosystem that allows developers to build robot software systems from reusable, off-the-shelf components. Systems are often built by customizing and connecting components via configuration files. While reusable components theoretically allow rapid prototyping, ensuring proper configuration and connection is challenging, as evidenced by numerous questions on developer forums. Developers must abide to the often unchecked and unstated assumptions of individual components. Failure to do so can result in misconfigurations that are only discovered during field deployment, at which point errors may lead to unpredictable and dangerous behavior. Despite misconfigurations having been studied in the broader context of software engineering, robotics software (and ROS in particular) poses domain-specific challenges with potentially disastrous consequences. To understand and improve the reliability of ROS projects, it is critical to identify the types of misconfigurations faced by developers. To that end, we perform a study of ROS Answers, a Q&A platform, to identify and categorize misconfigurations that occur during ROS development. We then conduct a literature review to assess the coverage of these misconfigurations by existing detection techniques. In total, we find 12 high-level categories and 50 sub-categories of misconfigurations. Of these categories, 27 are not covered by existing techniques. To conclude, we discuss how to tackle those misconfigurations in future work.
Data types as a more ergonomic frontend for Grammar-Guided Genetic Programming
Oct 10, 2022

Genetic Programming (GP) is an heuristic method that can be applied to many Machine Learning, Optimization and Engineering problems. In particular, it has been widely used in Software Engineering for Test-case generation, Program Synthesis and Improvement of Software (GI). Grammar-Guided Genetic Programming (GGGP) approaches allow the user to refine the domain of valid program solutions. Backus Normal Form is the most popular interface for describing Context-Free Grammars (CFG) for GGGP. BNF and its derivatives have the disadvantage of interleaving the grammar language and the target language of the program. We propose to embed the grammar as an internal Domain-Specific Language in the host language of the framework. This approach has the same expressive power as BNF and EBNF while using the host language type-system to take advantage of all the existing tooling: linters, formatters, type-checkers, autocomplete, and legacy code support. These tools have a practical utility in designing software in general, and GP systems in particular. We also present Meta-Handlers, user-defined overrides of the tree-generation system. This technique extends our object-oriented encoding with more practicability and expressive power than existing CFG approaches, achieving the same expressive power of Attribute Grammars, but without the grammar vs target language duality. Furthermore, we evidence that this approach is feasible, showing an example Python implementation as proof. We also compare our approach against textual BNF-representations w.r.t. expressive power and ergonomics. These advantages do not come at the cost of performance, as shown by our empirical evaluation on 5 benchmarks of our example implementation against PonyGE2. We conclude that our approach has better ergonomics with the same expressive power and performance of textual BNF-based grammar encodings.