 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Large Language Models Memorizing Bug Benchmarks?
Paper and Code
Nov 20, 2024
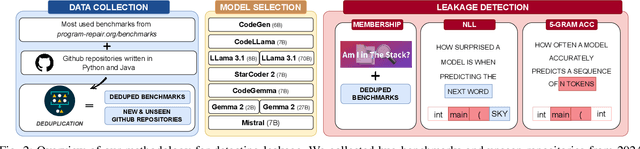
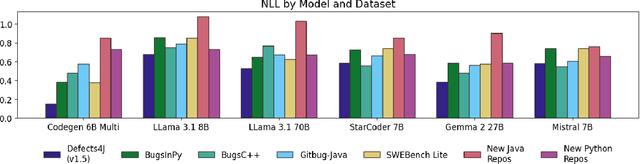
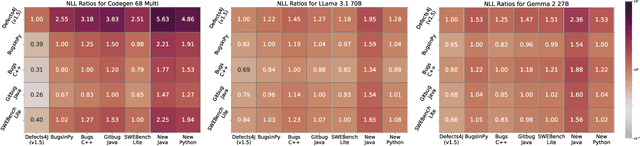
Large Language Models (LLMs) have become integral to various software engineering tasks, including code generation, bug detection, and repair. To evaluate model performance in these domains, numerous bug benchmarks containing real-world bugs from software projects have been developed. However, a growing concern within the software engineering community is that these benchmarks may not reliably reflect true LLM performance due to the risk of data leakage. Despite this concern, limited research has been conducted to quantify the impact of potential leakage. In this paper, we systematically evaluate popular LLMs to assess their susceptibility to data leakage from widely used bug benchmarks. To identify potential leakage, we use multiple metrics, including a study of benchmark membership within commonly used training datasets, as well as analyses of negative log-likelihood and n-gram accuracy. Our findings show that certain models, in particular codegen-multi, exhibit significant evidence of memorization in widely used benchmarks like Defects4J, while newer models trained on larger datasets like LLaMa 3.1 exhibit limited signs of leakage. These results highlight the need for careful benchmark selection and the adoption of robust metrics to adequately assess models capabilities.