 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPELL: Synthesis of Programmatic Edits using LLMs
Feb 01, 2026Library migration is a common but error-prone task in software development. Developers may need to replace one library with another due to reasons like changing requirements or licensing changes. Migration typically entails updating and rewriting source code manually. While automated migration tools exist, most rely on mining examples from real-world projects that have already undergone similar migrations. However, these data are scarce, and collecting them for arbitrary pairs of libraries is difficult. Moreover, these migration tools often miss out on leveraging modern code transformation infrastructure. In this paper, we present a new approach to automated API migration that sidesteps the limitations described above. Instead of relying on existing migration data or using LLMs directly for transformation, we use LLMs to extract migration examples. Next, we use an Agent to generalize those examples to reusable transformation scripts in PolyglotPiranha, a modern code transformation tool. Our method distills latent migration knowledge from LLMs into structured, testable, and repeatable migration logic, without requiring preexisting corpora or manual engineering effort. Experimental results across Python libraries show that our system can generate diverse migration examples and synthesize transformation scripts that generalize to real-world codebases.
Are Large Language Models Memorizing Bug Benchmarks?
Nov 20, 2024
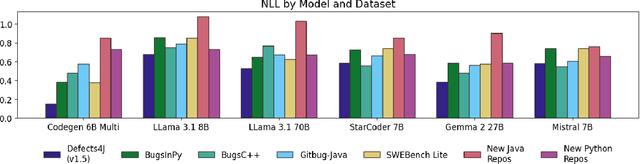
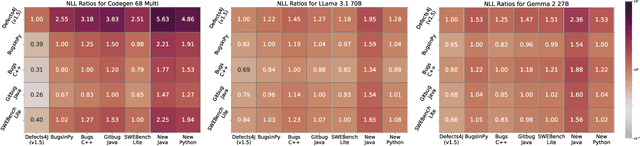
Large Language Models (LLMs) have become integral to various software engineering tasks, including code generation, bug detection, and repair. To evaluate model performance in these domains, numerous bug benchmarks containing real-world bugs from software projects have been developed. However, a growing concern within the software engineering community is that these benchmarks may not reliably reflect true LLM performance due to the risk of data leakage. Despite this concern, limited research has been conducted to quantify the impact of potential leakage. In this paper, we systematically evaluate popular LLMs to assess their susceptibility to data leakage from widely used bug benchmarks. To identify potential leakage, we use multiple metrics, including a study of benchmark membership within commonly used training datasets, as well as analyses of negative log-likelihood and n-gram accuracy. Our findings show that certain models, in particular codegen-multi, exhibit significant evidence of memorization in widely used benchmarks like Defects4J, while newer models trained on larger datasets like LLaMa 3.1 exhibit limited signs of leakage. These results highlight the need for careful benchmark selection and the adoption of robust metrics to adequately assess models capabilities.