 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRGB-D Salient Object Detection via 3D Convolutional Neural Networks
Paper and Code
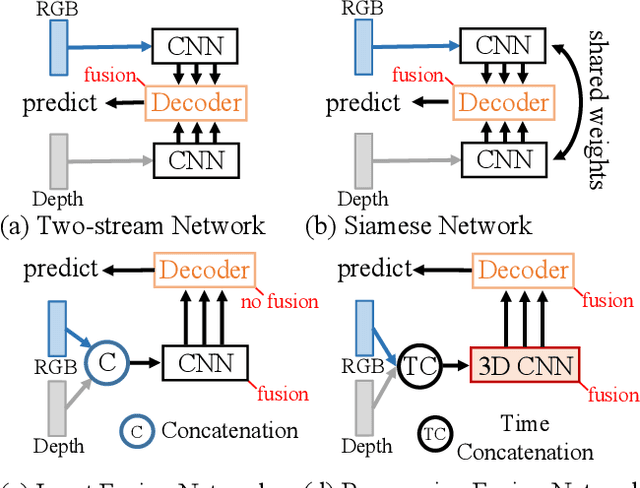



RGB-D salient object detection (SOD) recently has attracted increasing research interest and many deep learning methods based on encoder-decoder architectures have emerged. However, most existing RGB-D SOD models conduct feature fusion either in the single encoder or the decoder stage, which hardly guarantees sufficient cross-modal fusion ability. In this paper, we make the first attempt in addressing RGB-D SOD through 3D convolutional neural networks. The proposed model, named RD3D, aims at pre-fusion in the encoder stage and in-depth fusion in the decoder stage to effectively promote the full integration of RGB and depth streams. Specifically, RD3D first conducts pre-fusion across RGB and depth modalities through an inflated 3D encoder, and later provides in-depth feature fusion by designing a 3D decoder equipped with rich back-projection paths (RBPP) for leveraging the extensive aggregation ability of 3D convolutions. With such a progressive fusion strategy involving both the encoder and decoder, effective and thorough interaction between the two modalities can be exploited and boost the detection accuracy. Extensive experiments on six widely used benchmark datasets demonstrate that RD3D performs favorably against 14 state-of-the-art RGB-D SOD approaches in terms of four key evaluation metrics. Our code will be made publicly available: https://github.com/PPOLYpubki/RD3D.