 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Augmented Segmentation and Registration in Ultrasound-Guided Spinal Surgery via Realistic Ultrasound Synthesis from Diagnostic CT Volume
Jan 05, 2023This paper aims to tackle the issues on unavailable or insufficient clinical US data and meaningful annotation to enable bone segmentation and registration for US-guided spinal surgery. While the US is not a standard paradigm for spinal surgery, the scarcity of intra-operative clinical US data is an insurmountable bottleneck in training a neural network. Moreover, due to the characteristics of US imaging, it is difficult to clearly annotate bone surfaces which causes the trained neural network missing its attention to the details. Hence, we propose an In silico bone US simulation framework that synthesizes realistic US images from diagnostic CT volume. Afterward, using these simulated bone US we train a lightweight vision transformer model that can achieve accurate and on-the-fly bone segmentation for spinal sonography. In the validation experiments, the realistic US simulation was conducted by deriving from diagnostic spinal CT volume to facilitate a radiation-free US-guided pedicle screw placement procedure. When it is employed for training bone segmentation task, the Chamfer distance achieves 0.599mm; when it is applied for CT-US registration, the associated bone segmentation accuracy achieves 0.93 in Dice, and the registration accuracy based on the segmented point cloud is 0.13~3.37mm in a complication-free manner. While bone US images exhibit strong echoes at the medium interface, it may enable the model indistinguishable between thin interfaces and bone surfaces by simply relying on small neighborhood information. To overcome these shortcomings, we propose to utilize a Long-range Contrast Learning Module to fully explore the Long-range Contrast between the candidates and their surrounding pixels.
Exact Sparse Orthogonal Dictionary Learning
Mar 20, 2021
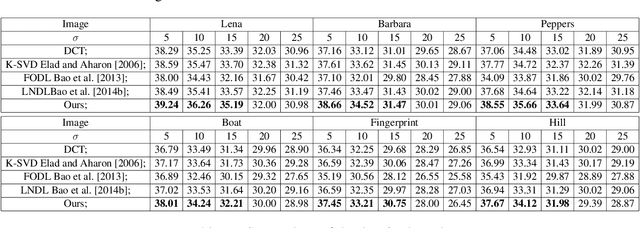
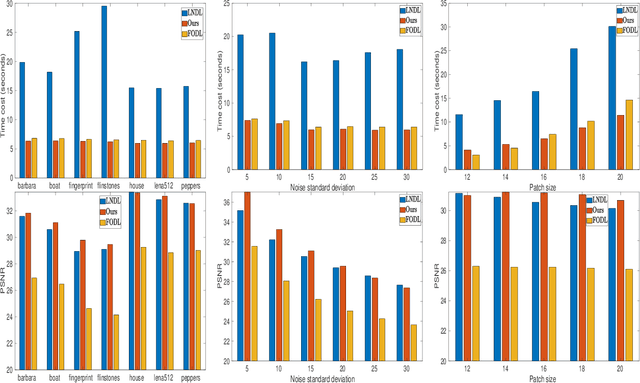

Over the past decade, learning a dictionary from input images for sparse modeling has been one of the topics which receive most research attention in image processing and compressed sensing. Most existing dictionary learning methods consider an over-complete dictionary, such as the K-SVD method, which may result in high mutual incoherence and therefore has a negative impact in recognition. On the other side, the sparse codes are usually optimized by adding the $\ell_0$ or $\ell_1$-norm penalty, but with no strict sparsity guarantee. In this paper, we propose an orthogonal dictionary learning model which can obtain strictly sparse codes and orthogonal dictionary with global sequence convergence guarantee. We find that our method can result in better denoising results than over-complete dictionary based learning methods, and has the additional advantage of high computation efficiency.