 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuralFur: Animal Fur Reconstruction From Multi-View Images
Jan 18, 2026Reconstructing realistic animal fur geometry from images is a challenging task due to the fine-scale details, self-occlusion, and view-dependent appearance of fur. In contrast to human hairstyle reconstruction, there are also no datasets that can be leveraged to learn a fur prior for different animals. In this work, we present a first multi-view-based method for high-fidelity 3D fur modeling of animals using a strand-based representation, leveraging the general knowledge of a vision language model. Given multi-view RGB images, we first reconstruct a coarse surface geometry using traditional multi-view stereo techniques. We then use a vision language model (VLM) system to retrieve information about the realistic length structure of the fur for each part of the body. We use this knowledge to construct the animal's furless geometry and grow strands atop it. The fur reconstruction is supervised with both geometric and photometric losses computed from multi-view images. To mitigate orientation ambiguities stemming from the Gabor filters that are applied to the input images, we additionally utilize the VLM to guide the strands' growth direction and their relation to the gravity vector that we incorporate as a loss. With this new schema of using a VLM to guide 3D reconstruction from multi-view inputs, we show generalization across a variety of animals with different fur types. For additional results and code, please refer to https://neuralfur.is.tue.mpg.de.
Joker: Conditional 3D Head Synthesis with Extreme Facial Expressions
Oct 21, 2024



We introduce Joker, a new method for the conditional synthesis of 3D human heads with extreme expressions. Given a single reference image of a person, we synthesize a volumetric human head with the reference identity and a new expression. We offer control over the expression via a 3D morphable model (3DMM) and textual inputs. This multi-modal conditioning signal is essential since 3DMMs alone fail to define subtle emotional changes and extreme expressions, including those involving the mouth cavity and tongue articulation. Our method is built upon a 2D diffusion-based prior that generalizes well to out-of-domain samples, such as sculptures, heavy makeup, and paintings while achieving high levels of expressiveness. To improve view consistency, we propose a new 3D distillation technique that converts predictions of our 2D prior into a neural radiance field (NeRF). Both the 2D prior and our distillation technique produce state-of-the-art results, which are confirmed by our extensive evaluations. Also, to the best of our knowledge, our method is the first to achieve view-consistent extreme tongue articulation.
360° Volumetric Portrait Avatar
Dec 08, 2023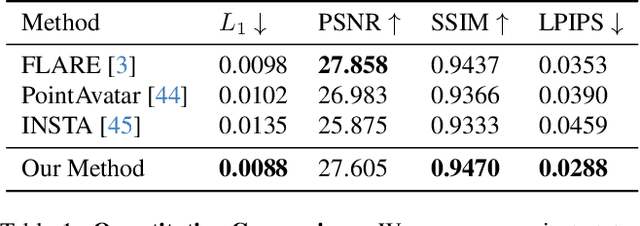

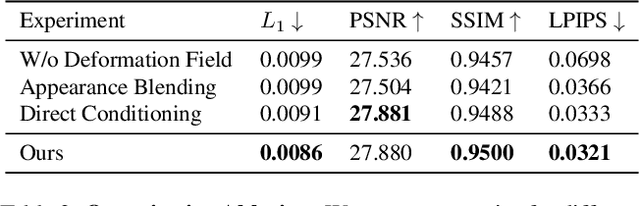

We propose 360{\deg} Volumetric Portrait (3VP) Avatar, a novel method for reconstructing 360{\deg} photo-realistic portrait avatars of human subjects solely based on monocular video inputs. State-of-the-art monocular avatar reconstruction methods rely on stable facial performance capturing. However, the common usage of 3DMM-based facial tracking has its limits; side-views can hardly be captured and it fails, especially, for back-views, as required inputs like facial landmarks or human parsing masks are missing. This results in incomplete avatar reconstructions that only cover the frontal hemisphere. In contrast to this, we propose a template-based tracking of the torso, head and facial expressions which allows us to cover the appearance of a human subject from all sides. Thus, given a sequence of a subject that is rotating in front of a single camera, we train a neural volumetric representation based on neural radiance fields. A key challenge to construct this representation is the modeling of appearance changes, especially, in the mouth region (i.e., lips and teeth). We, therefore, propose a deformation-field-based blend basis which allows us to interpolate between different appearance states. We evaluate our approach on captured real-world data and compare against state-of-the-art monocular reconstruction methods. In contrast to those, our method is the first monocular technique that reconstructs an entire 360{\deg} avatar.
GAN-Avatar: Controllable Personalized GAN-based Human Head Avatar
Nov 22, 2023

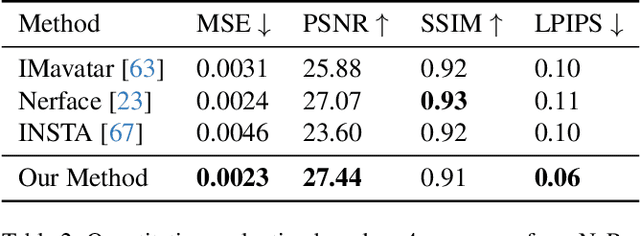
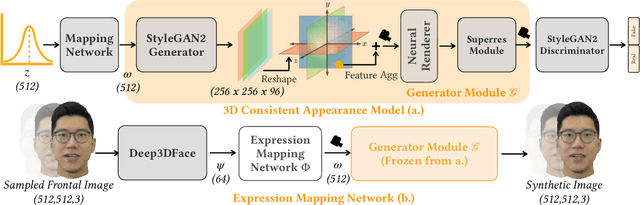
Digital humans and, especially, 3D facial avatars have raised a lot of attention in the past years, as they are the backbone of several applications like immersive telepresence in AR or VR. Despite the progress, facial avatars reconstructed from commodity hardware are incomplete and miss out on parts of the side and back of the head, severely limiting the usability of the avatar. This limitation in prior work stems from their requirement of face tracking, which fails for profile and back views. To address this issue, we propose to learn person-specific animatable avatars from images without assuming to have access to precise facial expression tracking. At the core of our method, we leverage a 3D-aware generative model that is trained to reproduce the distribution of facial expressions from the training data. To train this appearance model, we only assume to have a collection of 2D images with the corresponding camera parameters. For controlling the model, we learn a mapping from 3DMM facial expression parameters to the latent space of the generative model. This mapping can be learned by sampling the latent space of the appearance model and reconstructing the facial parameters from a normalized frontal view, where facial expression estimation performs well. With this scheme, we decouple 3D appearance reconstruction and animation control to achieve high fidelity in image synthesis. In a series of experiments, we compare our proposed technique to state-of-the-art monocular methods and show superior quality while not requiring expression tracking of the training data.