 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Mid-level Words on Riemannian Manifold for Action Recognition
Paper and Code
Nov 16, 2015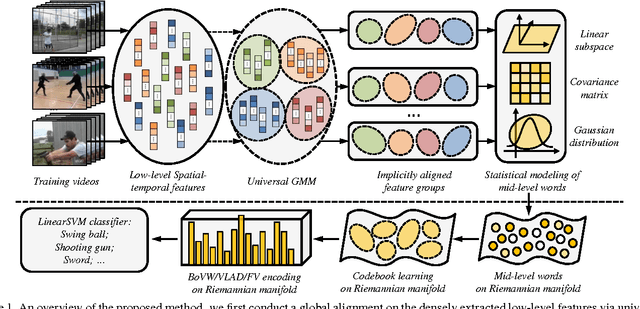



Human action recognition remains a challenging task due to the various sources of video data and large intra-class variations. It thus becomes one of the key issues in recent research to explore effective and robust representation to handle such challenges. In this paper, we propose a novel representation approach by constructing mid-level words in videos and encoding them on Riemannian manifold. Specifically, we first conduct a global alignment on the densely extracted low-level features to build a bank of corresponding feature groups, each of which can be statistically modeled as a mid-level word lying on some specific Riemannian manifold. Based on these mid-level words, we construct intrinsic Riemannian codebooks by employing K-Karcher-means clustering and Riemannian Gaussian Mixture Model, and consequently extend the Riemannian manifold version of three well studied encoding methods in Euclidean space, i.e. Bag of Visual Words (BoVW), Vector of Locally Aggregated Descriptors (VLAD), and Fisher Vector (FV), to obtain the final action video representations. Our method is evaluated in two tasks on four popular realistic datasets: action recognition on YouTube, UCF50, HMDB51 databases, and action similarity labeling on ASLAN database. In all cases, the reported results achieve very competitive performance with those most recent state-of-the-art works.