 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Denoising and the Generative Accumulation of Photons
Aug 01, 2023
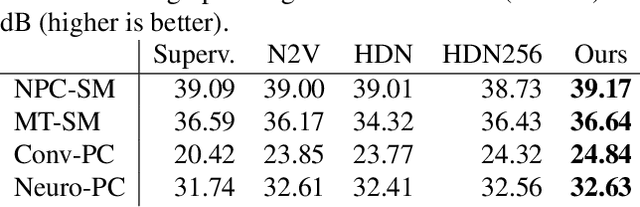
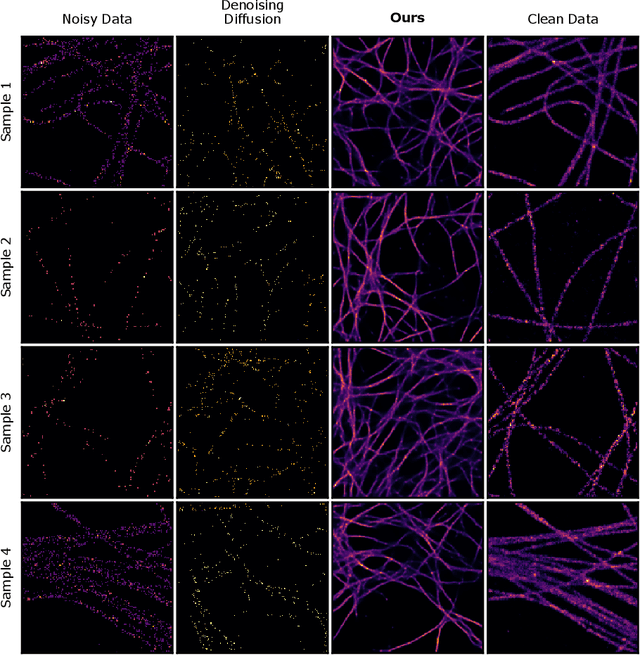

We present a fresh perspective on shot noise corrupted images and noise removal. By viewing image formation as the sequential accumulation of photons on a detector grid, we show that a network trained to predict where the next photon could arrive is in fact solving the minimum mean square error (MMSE) denoising task. This new perspective allows us to make three contributions: We present a new strategy for self-supervised denoising, We present a new method for sampling from the posterior of possible solutions by iteratively sampling and adding small numbers of photons to the image. We derive a full generative model by starting this process from an empty canvas. We call this approach generative accumulation of photons (GAP). We evaluate our method quantitatively and qualitatively on 4 new fluorescence microscopy datasets, which will be made available to the community. We find that it outperforms supervised, self-supervised and unsupervised baselines or performs on-par.
EyeNeRF: A Hybrid Representation for Photorealistic Synthesis, Animation and Relighting of Human Eyes
Jun 16, 2022
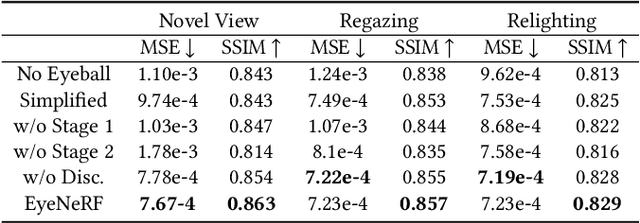
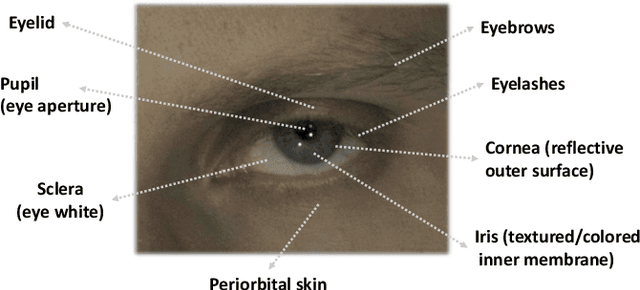
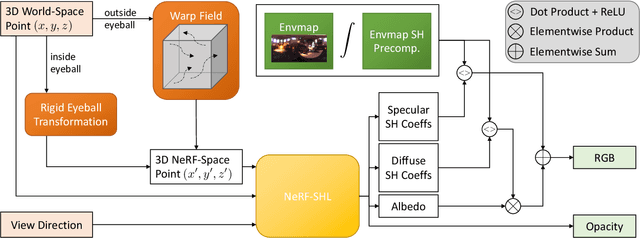
A unique challenge in creating high-quality animatable and relightable 3D avatars of people is modeling human eyes. The challenge of synthesizing eyes is multifold as it requires 1) appropriate representations for the various components of the eye and the periocular region for coherent viewpoint synthesis, capable of representing diffuse, refractive and highly reflective surfaces, 2) disentangling skin and eye appearance from environmental illumination such that it may be rendered under novel lighting conditions, and 3) capturing eyeball motion and the deformation of the surrounding skin to enable re-gazing. These challenges have traditionally necessitated the use of expensive and cumbersome capture setups to obtain high-quality results, and even then, modeling of the eye region holistically has remained elusive. We present a novel geometry and appearance representation that enables high-fidelity capture and photorealistic animation, view synthesis and relighting of the eye region using only a sparse set of lights and cameras. Our hybrid representation combines an explicit parametric surface model for the eyeball with implicit deformable volumetric representations for the periocular region and the interior of the eye. This novel hybrid model has been designed to address the various parts of that challenging facial area - the explicit eyeball surface allows modeling refraction and high-frequency specular reflection at the cornea, whereas the implicit representation is well suited to model lower-frequency skin reflection via spherical harmonics and can represent non-surface structures such as hair or diffuse volumetric bodies, both of which are a challenge for explicit surface models. We show that for high-resolution close-ups of the eye, our model can synthesize high-fidelity animated gaze from novel views under unseen illumination conditions.