 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Unsupervised Denoising
Oct 27, 2023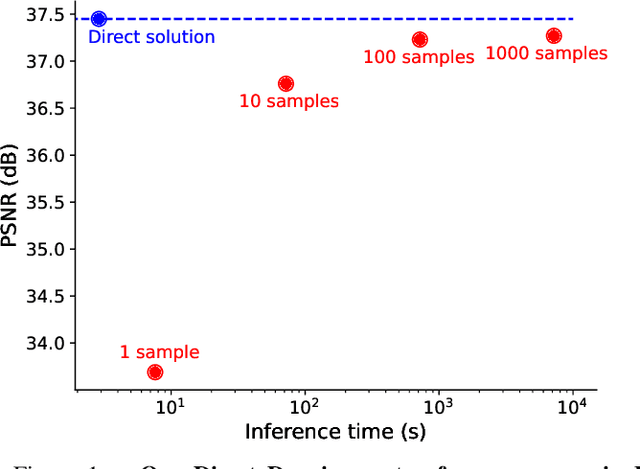
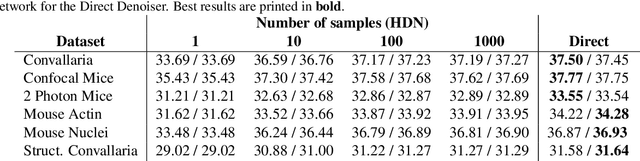
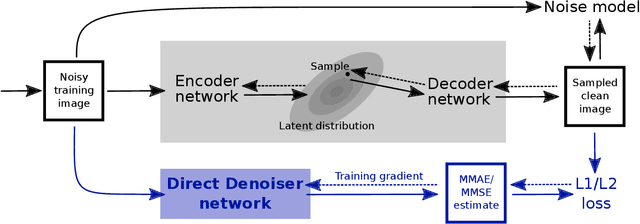
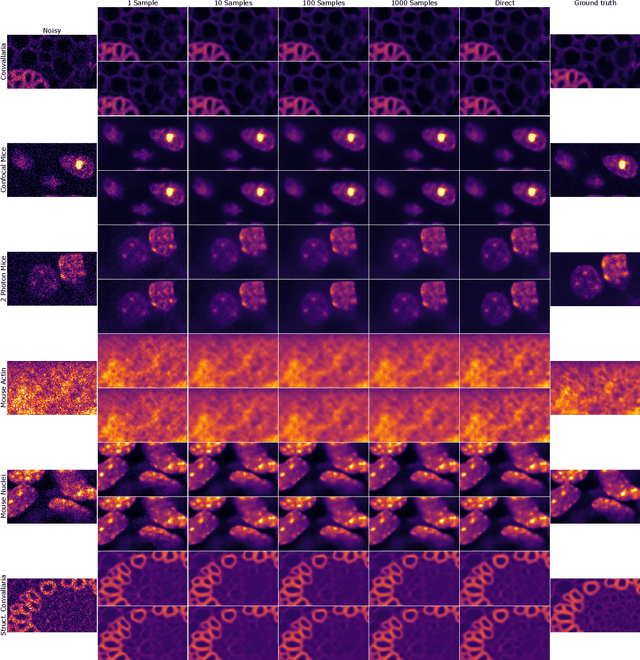
Traditional supervised denoisers are trained using pairs of noisy input and clean target images. They learn to predict a central tendency of the posterior distribution over possible clean images. When, e.g., trained with the popular quadratic loss function, the network's output will correspond to the minimum mean square error (MMSE) estimate. Unsupervised denoisers based on Variational AutoEncoders (VAEs) have succeeded in achieving state-of-the-art results while requiring only unpaired noisy data as training input. In contrast to the traditional supervised approach, unsupervised denoisers do not directly produce a single prediction, such as the MMSE estimate, but allow us to draw samples from the posterior distribution of clean solutions corresponding to the noisy input. To approximate the MMSE estimate during inference, unsupervised methods have to create and draw a large number of samples - a computationally expensive process - rendering the approach inapplicable in many situations. Here, we present an alternative approach that trains a deterministic network alongside the VAE to directly predict a central tendency. Our method achieves results that surpass the results achieved by the unsupervised method at a fraction of the computational cost.
Unsupervised Structured Noise Removal with Variational Lossy Autoencoder
Oct 11, 2023Most unsupervised denoising methods are based on the assumption that imaging noise is either pixel-independent, i.e., spatially uncorrelated, or signal-independent, i.e., purely additive. However, in practice many imaging setups, especially in microscopy, suffer from a combination of signal-dependent noise (e.g. Poisson shot noise) and axis-aligned correlated noise (e.g. stripe shaped scanning or readout artifacts). In this paper, we present the first unsupervised deep learning-based denoiser that can remove this type of noise without access to any clean images or a noise model. Unlike self-supervised techniques, our method does not rely on removing pixels by masking or subsampling so can utilize all available information. We implement a Variational Autoencoder (VAE) with a specially designed autoregressive decoder capable of modelling the noise component of an image but incapable of independently modelling the underlying clean signal component. As a consequence, our VAE's encoder learns to encode only underlying clean signal content and to discard imaging noise. We also propose an additional decoder for mapping the encoder's latent variables back into image space, thereby sampling denoised images. Experimental results demonstrate that our approach surpasses existing methods for self- and unsupervised image denoising while being robust with respect to the size of the autoregressive receptive field. Code for this project can be found at https://github.com/krulllab/DVLAE.
Image Denoising and the Generative Accumulation of Photons
Aug 01, 2023
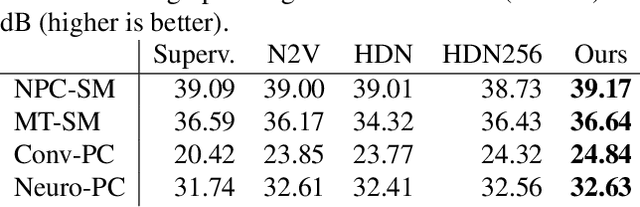
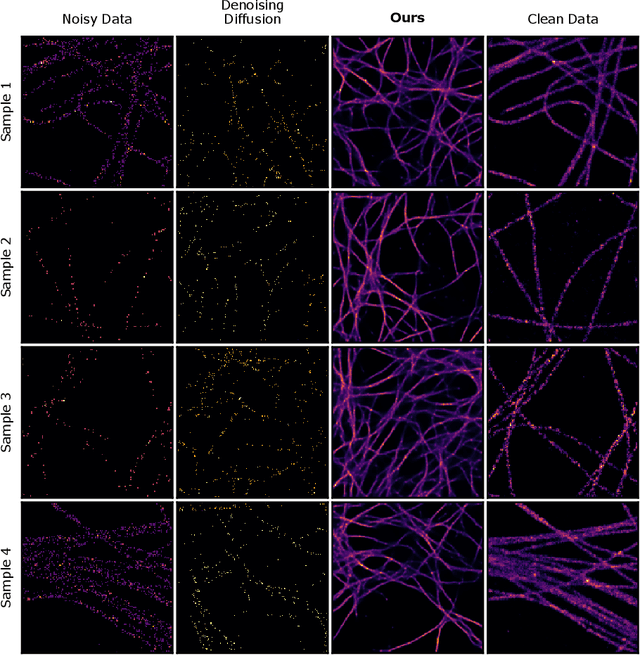

We present a fresh perspective on shot noise corrupted images and noise removal. By viewing image formation as the sequential accumulation of photons on a detector grid, we show that a network trained to predict where the next photon could arrive is in fact solving the minimum mean square error (MMSE) denoising task. This new perspective allows us to make three contributions: We present a new strategy for self-supervised denoising, We present a new method for sampling from the posterior of possible solutions by iteratively sampling and adding small numbers of photons to the image. We derive a full generative model by starting this process from an empty canvas. We call this approach generative accumulation of photons (GAP). We evaluate our method quantitatively and qualitatively on 4 new fluorescence microscopy datasets, which will be made available to the community. We find that it outperforms supervised, self-supervised and unsupervised baselines or performs on-par.