 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFilter Distribution Templates in Convolutional Networks for Image Classification Tasks
Apr 28, 2021
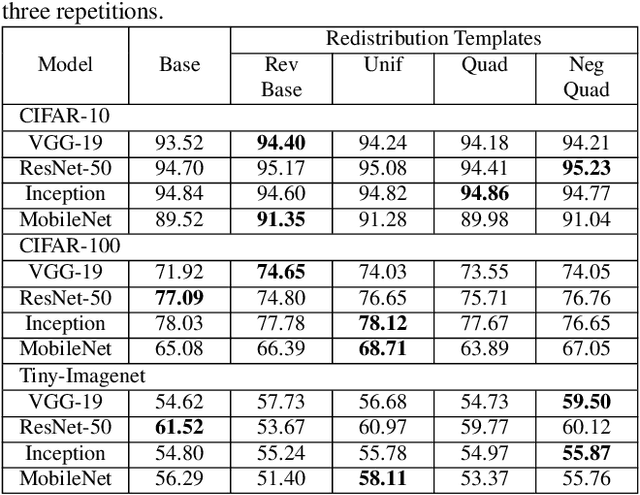
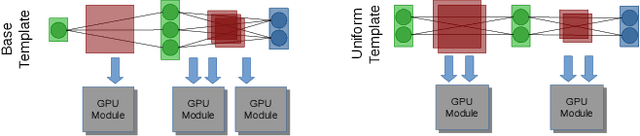
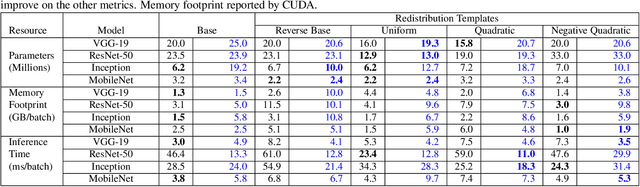
Neural network designers have reached progressive accuracy by increasing models depth, introducing new layer types and discovering new combinations of layers. A common element in many architectures is the distribution of the number of filters in each layer. Neural network models keep a pattern design of increasing filters in deeper layers such as those in LeNet, VGG, ResNet, MobileNet and even in automatic discovered architectures such as NASNet. It remains unknown if this pyramidal distribution of filters is the best for different tasks and constrains. In this work we present a series of modifications in the distribution of filters in four popular neural network models and their effects in accuracy and resource consumption. Results show that by applying this approach, some models improve up to 8.9% in accuracy showing reductions in parameters up to 54%.
Towards Efficient Convolutional Network Models with Filter Distribution Templates
Apr 17, 2021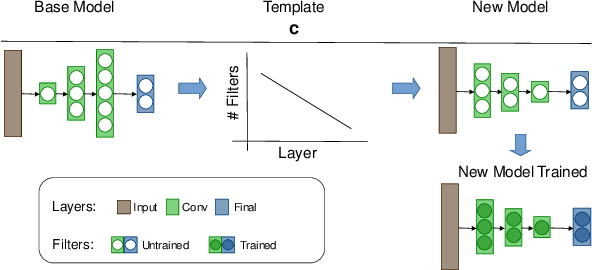
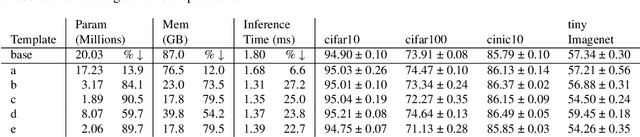
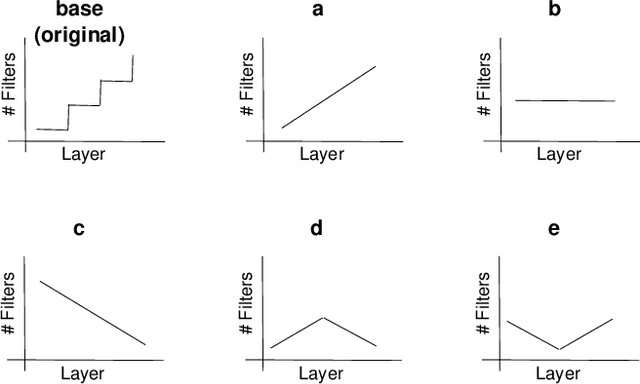

Increasing number of filters in deeper layers when feature maps are decreased is a widely adopted pattern in convolutional network design. It can be found in classical CNN architectures and in automatic discovered models. Even CNS methods commonly explore a selection of multipliers derived from this pyramidal pattern. We defy this practice by introducing a small set of templates consisting of easy to implement, intuitive and aggressive variations of the original pyramidal distribution of filters in VGG and ResNet architectures. Experiments on CIFAR, CINIC10 and TinyImagenet datasets show that models produced by our templates, are more efficient in terms of fewer parameters and memory needs.