 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Driven Co-Evolutionary Automated Heuristic Design for Bi-Component Coupled Combinatorial Optimization
May 30, 2026While Large Language Models (LLMs) have recently shown promise in Automated Heuristic Design (AHD), existing methods typically generate and evolve heuristics as a single operator or search strategy, limiting their ability to model strong coupling among multiple decision substructures in problems such as the Traveling Thief Problem (TTP) and the Traveling Purchaser Problem (TPP). In this work, we propose CoEvo-AHD, an LLM-driven dual-population co-evolutionary framework for automated heuristic design in coupled combinatorial optimization. Unlike prior methods that evolve individual heuristics in isolation, CoEvo-AHD leverages LLMs to co-evolve two closely related operator populations. A cooperative evaluation mechanism explicitly captures interactions between route and selection operators, while pairwise scoring and synergistic joint crossover help discover complementary operator logic for joint improvement across coupled decision subspaces. We further design a tool-invocation environment library that encapsulates frequently used core operations, such as local-search delta computation, into callable functions, enabling LLM-generated operators to use standardized interfaces instead of reimplementing inefficient and error-prone problem-specific loops. Experiments on TTP and TPP show that CoEvo-AHD automatically discovers cooperative heuristic combinations and achieves competitive solution quality against traditional heuristics.
Survey on Neural Routing Solvers
Feb 25, 2026Neural routing solvers (NRSs) that leverage deep learning to tackle vehicle routing problems have demonstrated notable potential for practical applications. By learning implicit heuristic rules from data, NRSs replace the handcrafted counterparts in classic heuristic frameworks, thereby reducing reliance on costly manual design and trial-and-error adjustments. This survey makes two main contributions: (1) The heuristic nature of NRSs is highlighted, and existing NRSs are reviewed from the perspective of heuristics. A hierarchical taxonomy based on heuristic principles is further introduced. (2) A generalization-focused evaluation pipeline is proposed to address limitations of the conventional pipeline. Comparative benchmarking of representative NRSs across both pipelines uncovers a series of previously unreported gaps in current research.
MIRROR: A Multi-Agent Framework with Iterative Adaptive Revision and Hierarchical Retrieval for Optimization Modeling in Operations Research
Feb 03, 2026Operations Research (OR) relies on expert-driven modeling-a slow and fragile process ill-suited to novel scenarios. While large language models (LLMs) can automatically translate natural language into optimization models, existing approaches either rely on costly post-training or employ multi-agent frameworks, yet most still lack reliable collaborative error correction and task-specific retrieval, often leading to incorrect outputs. We propose MIRROR, a fine-tuning-free, end-to-end multi-agent framework that directly translates natural language optimization problems into mathematical models and solver code. MIRROR integrates two core mechanisms: (1) execution-driven iterative adaptive revision for automatic error correction, and (2) hierarchical retrieval to fetch relevant modeling and coding exemplars from a carefully curated exemplar library. Experiments show that MIRROR outperforms existing methods on standard OR benchmarks, with notable results on complex industrial datasets such as IndustryOR and Mamo-ComplexLP. By combining precise external knowledge infusion with systematic error correction, MIRROR provides non-expert users with an efficient and reliable OR modeling solution, overcoming the fundamental limitations of general-purpose LLMs in expert optimization tasks.
Quality-Diversity Optimization as Multi-Objective Optimization
Jan 31, 2026The Quality-Diversity (QD) optimization aims to discover a collection of high-performing solutions that simultaneously exhibit diverse behaviors within a user-defined behavior space. This paradigm has stimulated significant research interest and demonstrated practical utility in domains including robot control, creative design, and adversarial sample generation. A variety of QD algorithms with distinct design principles have been proposed in recent years. Instead of proposing a new QD algorithm, this work introduces a novel reformulation by casting the QD optimization as a multi-objective optimization (MOO) problem with a huge number of optimization objectives. By establishing this connection, we enable the direct adoption of well-established MOO methods, particularly set-based scalarization techniques, to solve QD problems through a collaborative search process. We further provide a theoretical analysis demonstrating that our approach inherits theoretical guarantees from MOO while providing desirable properties for the QD optimization. Experimental studies across several QD applications confirm that our method achieves performance competitive with state-of-the-art QD algorithms.
TIDE: Tuning-Integrated Dynamic Evolution for LLM-Based Automated Heuristic Design
Jan 29, 2026Although Large Language Models have advanced Automated Heuristic Design, treating algorithm evolution as a monolithic text generation task overlooks the coupling between discrete algorithmic structures and continuous numerical parameters. Consequently, existing methods often discard promising algorithms due to uncalibrated constants and suffer from premature convergence resulting from simple similarity metrics. To address these limitations, we propose TIDE, a Tuning-Integrated Dynamic Evolution framework designed to decouple structural reasoning from parameter optimization. TIDE features a nested architecture where an outer parallel island model utilizes Tree Similarity Edit Distance to drive structural diversity, while an inner loop integrates LLM-based logic generation with a differential mutation operator for parameter tuning. Additionally, a UCB-based scheduler dynamically prioritizes high-yield prompt strategies to optimize resource allocation. Extensive experiments across nine combinatorial optimization problems demonstrate that TIDE discovers heuristics that significantly outperform state-of-the-art baselines in solution quality while achieving improved search efficiency and reduced computational costs.
Learning to Insert for Constructive Neural Vehicle Routing Solver
May 20, 2025



Neural Combinatorial Optimisation (NCO) is a promising learning-based approach for solving Vehicle Routing Problems (VRPs) without extensive manual design. While existing constructive NCO methods typically follow an appending-based paradigm that sequentially adds unvisited nodes to partial solutions, this rigid approach often leads to suboptimal results. To overcome this limitation, we explore the idea of insertion-based paradigm and propose Learning to Construct with Insertion-based Paradigm (L2C-Insert), a novel learning-based method for constructive NCO. Unlike traditional approaches, L2C-Insert builds solutions by strategically inserting unvisited nodes at any valid position in the current partial solution, which can significantly enhance the flexibility and solution quality. The proposed framework introduces three key components: a novel model architecture for precise insertion position prediction, an efficient training scheme for model optimization, and an advanced inference technique that fully exploits the insertion paradigm's flexibility. Extensive experiments on both synthetic and real-world instances of the Travelling Salesman Problem (TSP) and Capacitated Vehicle Routing Problem (CVRP) demonstrate that L2C-Insert consistently achieves superior performance across various problem sizes.
Learning from Few Demonstrations with Frame-Weighted Motion Generation
Mar 29, 2023Learning from Demonstration (LfD) aims to encode versatile skills from human demonstrations. The field has been gaining popularity since it facilitates knowledge transfer to robots without requiring expert knowledge in robotics. During task executions, the robot motion is usually influenced by constraints imposed by environments. In light of this, task-parameterized LfD (TP-LfD) encodes relevant contextual information in reference frames, enabling better skill generalization to new situations. However, most TP-LfD algorithms require multiple demonstrations in various environment conditions to ensure sufficient statistics for a meaningful model. It is not a trivial task for robot users to create different situations and perform demonstrations under all of them. Therefore, this paper presents a novel concept for learning motion policies from few demonstrations by finding the reference frame weights which capture frame importance/relevance during task executions. Experimental results in both simulation and real robotic environments validate our approach.
Learning adaptive differential evolution algorithm from optimization experiences by policy gradient
Feb 06, 2021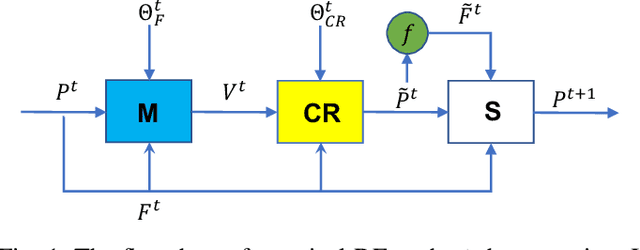
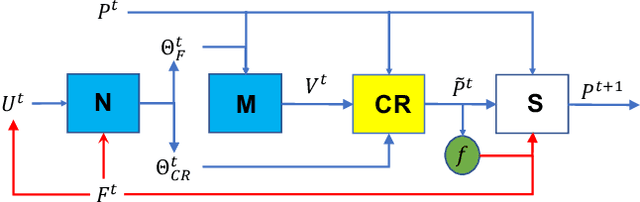
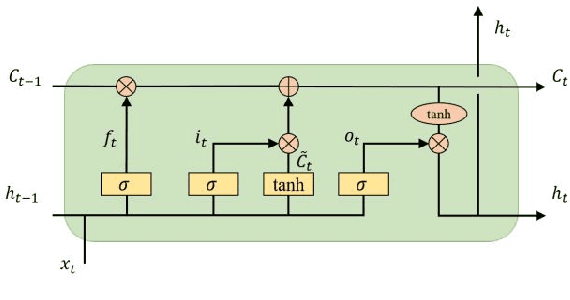
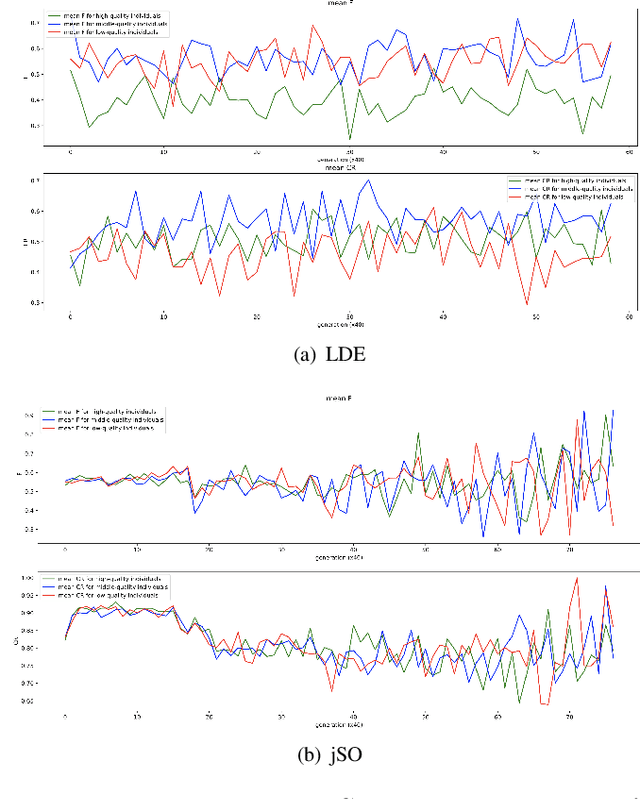
Differential evolution is one of the most prestigious population-based stochastic optimization algorithm for black-box problems. The performance of a differential evolution algorithm depends highly on its mutation and crossover strategy and associated control parameters. However, the determination process for the most suitable parameter setting is troublesome and time-consuming. Adaptive control parameter methods that can adapt to problem landscape and optimization environment are more preferable than fixed parameter settings. This paper proposes a novel adaptive parameter control approach based on learning from the optimization experiences over a set of problems. In the approach, the parameter control is modeled as a finite-horizon Markov decision process. A reinforcement learning algorithm, named policy gradient, is applied to learn an agent (i.e. parameter controller) that can provide the control parameters of a proposed differential evolution adaptively during the search procedure. The differential evolution algorithm based on the learned agent is compared against nine well-known evolutionary algorithms on the CEC'13 and CEC'17 test suites. Experimental results show that the proposed algorithm performs competitively against these compared algorithms on the test suites.
Amortized Variational Deep Q Network
Nov 03, 2020
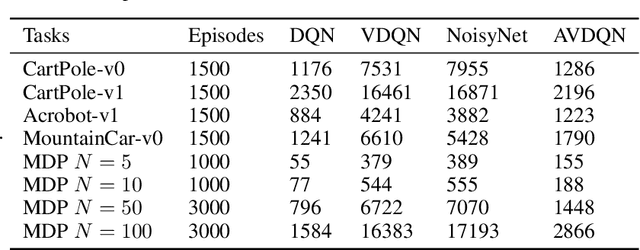
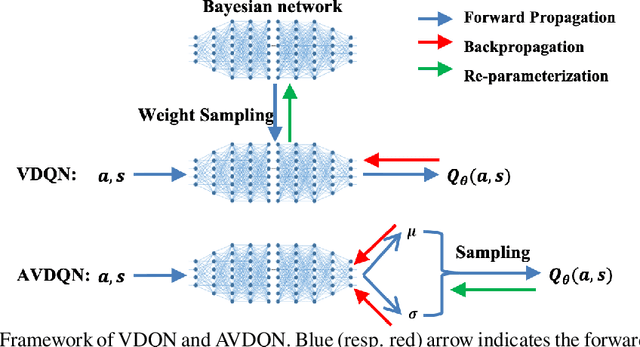
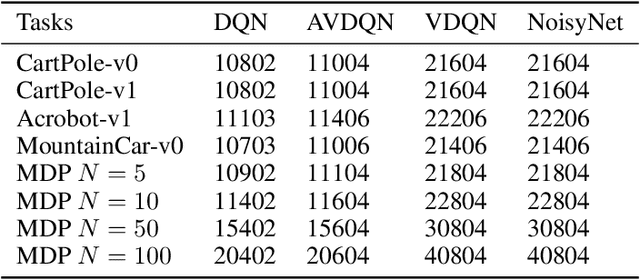
Efficient exploration is one of the most important issues in deep reinforcement learning. To address this issue, recent methods consider the value function parameters as random variables, and resort variational inference to approximate the posterior of the parameters. In this paper, we propose an amortized variational inference framework to approximate the posterior distribution of the action value function in Deep Q Network. We establish the equivalence between the loss of the new model and the amortized variational inference loss. We realize the balance of exploration and exploitation by assuming the posterior as Cauchy and Gaussian, respectively in a two-stage training process. We show that the amortized framework can results in significant less learning parameters than existing state-of-the-art method. Experimental results on classical control tasks in OpenAI Gym and chain Markov Decision Process tasks show that the proposed method performs significantly better than state-of-art methods and requires much less training time.
Graph Neural Network Encoding for Community Detection in Attribute Networks
Jun 06, 2020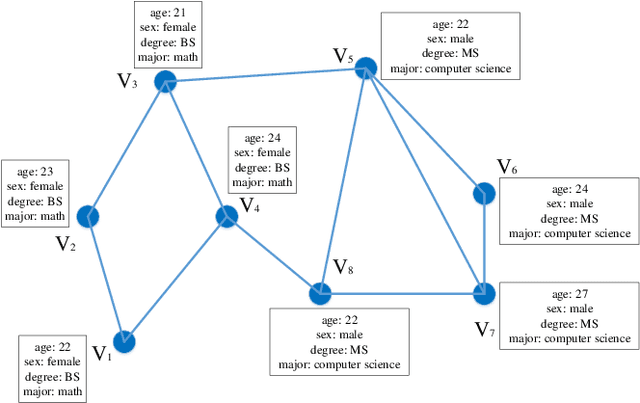
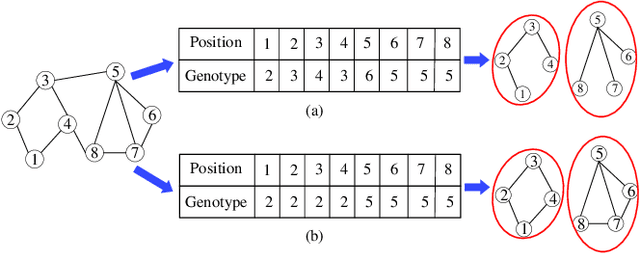
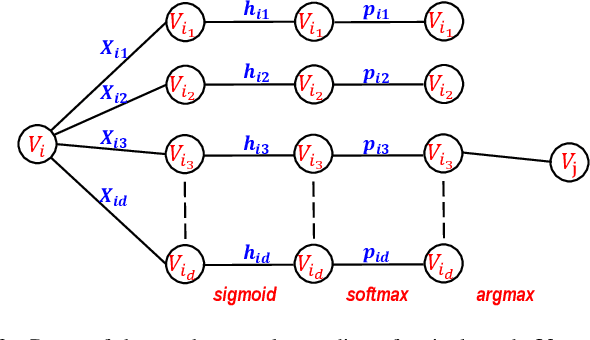
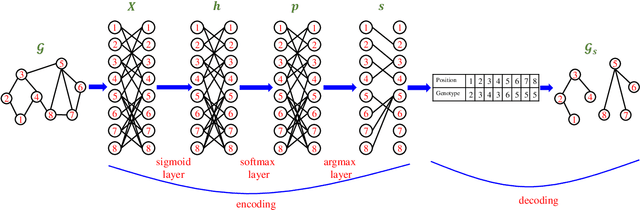
In this paper, we first propose a graph neural network encoding method for multiobjective evolutionary algorithm to handle the community detection problem in complex attribute networks. In the graph neural network encoding method, each edge in an attribute network is associated with a continuous variable. Through non-linear transformation, a continuous valued vector (i.e. a concatenation of the continuous variables associated with all edges) is transferred to a discrete valued community grouping solution. Further, two new objective functions for single- and multi-attribute network are proposed to evaluate the attribute homogeneity of the nodes in communities, respectively. Based on the new encoding method and the two new objectives, a multiobjective evolutionary algorithm (MOEA) based upon NSGA-II, termed as continuous encoding MOEA, is developed for the transformed community detection problem with continuous decision variables. Experimental results on single- and multi-attribute real-life networks with different types show that the developed algorithm performs significantly better than some well-known evolutionary and non-evolutionary based algorithms. The fitness landscape analysis verifies that the transformed community detection problems have smoother landscapes than those of the original problems, which justifies the effectiveness of the proposed graph neural network encoding method.