 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHSM: Hierarchical Scene Motifs for Multi-Scale Indoor Scene Generation
Mar 21, 2025
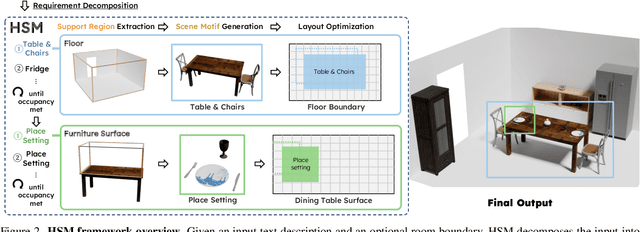

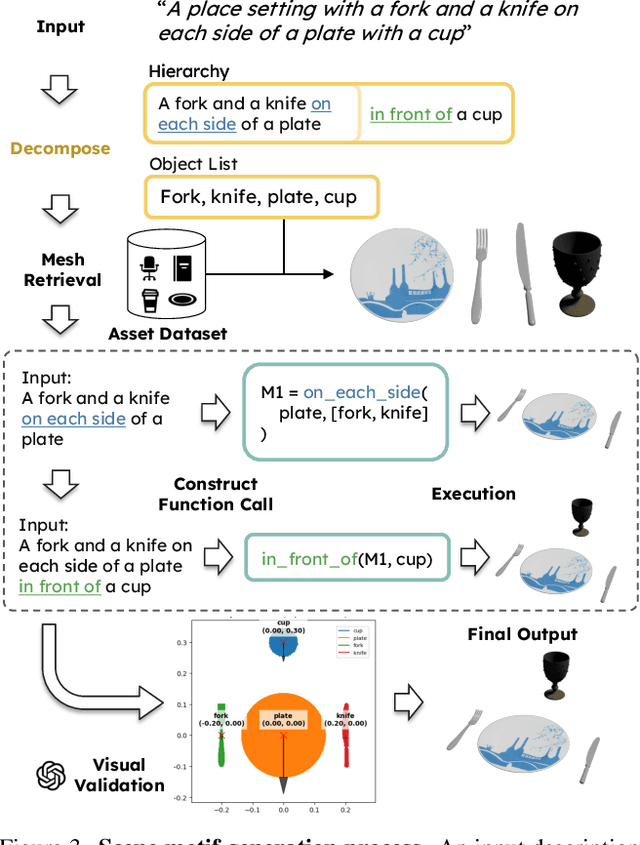
Despite advances in indoor 3D scene layout generation, synthesizing scenes with dense object arrangements remains challenging. Existing methods primarily focus on large furniture while neglecting smaller objects, resulting in unrealistically empty scenes. Those that place small objects typically do not honor arrangement specifications, resulting in largely random placement not following the text description. We present HSM, a hierarchical framework for indoor scene generation with dense object arrangements across spatial scales. Indoor scenes are inherently hierarchical, with surfaces supporting objects at different scales, from large furniture on floors to smaller objects on tables and shelves. HSM embraces this hierarchy and exploits recurring cross-scale spatial patterns to generate complex and realistic indoor scenes in a unified manner. Our experiments show that HSM outperforms existing methods by generating scenes that are more realistic and better conform to user input across room types and spatial configurations.
IROAM: Improving Roadside Monocular 3D Object Detection Learning from Autonomous Vehicle Data Domain
Jan 30, 2025



In autonomous driving, The perception capabilities of the ego-vehicle can be improved with roadside sensors, which can provide a holistic view of the environment. However, existing monocular detection methods designed for vehicle cameras are not suitable for roadside cameras due to viewpoint domain gaps. To bridge this gap and Improve ROAdside Monocular 3D object detection, we propose IROAM, a semantic-geometry decoupled contrastive learning framework, which takes vehicle-side and roadside data as input simultaneously. IROAM has two significant modules. In-Domain Query Interaction module utilizes a transformer to learn content and depth information for each domain and outputs object queries. Cross-Domain Query Enhancement To learn better feature representations from two domains, Cross-Domain Query Enhancement decouples queries into semantic and geometry parts and only the former is used for contrastive learning. Experiments demonstrate the effectiveness of IROAM in improving roadside detector's performance. The results validate that IROAM has the capabilities to learn cross-domain information.
EMIFF: Enhanced Multi-scale Image Feature Fusion for Vehicle-Infrastructure Cooperative 3D Object Detection
Feb 23, 2024



In autonomous driving, cooperative perception makes use of multi-view cameras from both vehicles and infrastructure, providing a global vantage point with rich semantic context of road conditions beyond a single vehicle viewpoint. Currently, two major challenges persist in vehicle-infrastructure cooperative 3D (VIC3D) object detection: $1)$ inherent pose errors when fusing multi-view images, caused by time asynchrony across cameras; $2)$ information loss in transmission process resulted from limited communication bandwidth. To address these issues, we propose a novel camera-based 3D detection framework for VIC3D task, Enhanced Multi-scale Image Feature Fusion (EMIFF). To fully exploit holistic perspectives from both vehicles and infrastructure, we propose Multi-scale Cross Attention (MCA) and Camera-aware Channel Masking (CCM) modules to enhance infrastructure and vehicle features at scale, spatial, and channel levels to correct the pose error introduced by camera asynchrony. We also introduce a Feature Compression (FC) module with channel and spatial compression blocks for transmission efficiency. Experiments show that EMIFF achieves SOTA on DAIR-V2X-C datasets, significantly outperforming previous early-fusion and late-fusion methods with comparable transmission costs.
VIMI: Vehicle-Infrastructure Multi-view Intermediate Fusion for Camera-based 3D Object Detection
Mar 20, 2023



In autonomous driving, Vehicle-Infrastructure Cooperative 3D Object Detection (VIC3D) makes use of multi-view cameras from both vehicles and traffic infrastructure, providing a global vantage point with rich semantic context of road conditions beyond a single vehicle viewpoint. Two major challenges prevail in VIC3D: 1) inherent calibration noise when fusing multi-view images, caused by time asynchrony across cameras; 2) information loss when projecting 2D features into 3D space. To address these issues, We propose a novel 3D object detection framework, Vehicles-Infrastructure Multi-view Intermediate fusion (VIMI). First, to fully exploit the holistic perspectives from both vehicles and infrastructure, we propose a Multi-scale Cross Attention (MCA) module that fuses infrastructure and vehicle features on selective multi-scales to correct the calibration noise introduced by camera asynchrony. Then, we design a Camera-aware Channel Masking (CCM) module that uses camera parameters as priors to augment the fused features. We further introduce a Feature Compression (FC) module with channel and spatial compression blocks to reduce the size of transmitted features for enhanced efficiency. Experiments show that VIMI achieves 15.61% overall AP_3D and 21.44% AP_BEV on the new VIC3D dataset, DAIR-V2X-C, significantly outperforming state-of-the-art early fusion and late fusion methods with comparable transmission cost.
Calibration-free BEV Representation for Infrastructure Perception
Mar 07, 2023Effective BEV object detection on infrastructure can greatly improve traffic scenes understanding and vehicle-toinfrastructure (V2I) cooperative perception. However, cameras installed on infrastructure have various postures, and previous BEV detection methods rely on accurate calibration, which is difficult for practical applications due to inevitable natural factors (e.g., wind and snow). In this paper, we propose a Calibration-free BEV Representation (CBR) network, which achieves 3D detection based on BEV representation without calibration parameters and additional depth supervision. Specifically, we utilize two multi-layer perceptrons for decoupling the features from perspective view to front view and birdeye view under boxes-induced foreground supervision. Then, a cross-view feature fusion module matches features from orthogonal views according to similarity and conducts BEV feature enhancement with front view features. Experimental results on DAIR-V2X demonstrate that CBR achieves acceptable performance without any camera parameters and is naturally not affected by calibration noises. We hope CBR can serve as a baseline for future research addressing practical challenges of infrastructure perception.
Improving RGB-D Point Cloud Registration by Learning Multi-scale Local Linear Transformation
Sep 01, 2022


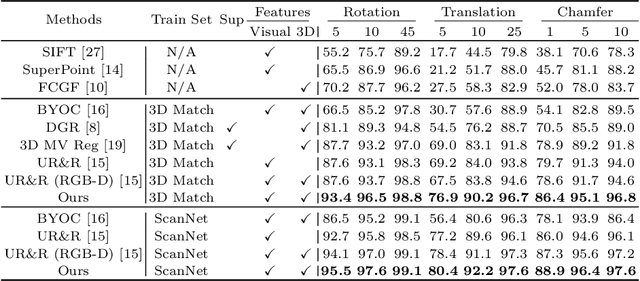
Point cloud registration aims at estimating the geometric transformation between two point cloud scans, in which point-wise correspondence estimation is the key to its success. In addition to previous methods that seek correspondences by hand-crafted or learnt geometric features, recent point cloud registration methods have tried to apply RGB-D data to achieve more accurate correspondence. However, it is not trivial to effectively fuse the geometric and visual information from these two distinctive modalities, especially for the registration problem. In this work, we propose a new Geometry-Aware Visual Feature Extractor (GAVE) that employs multi-scale local linear transformation to progressively fuse these two modalities, where the geometric features from the depth data act as the geometry-dependent convolution kernels to transform the visual features from the RGB data. The resultant visual-geometric features are in canonical feature spaces with alleviated visual dissimilarity caused by geometric changes, by which more reliable correspondence can be achieved. The proposed GAVE module can be readily plugged into recent RGB-D point cloud registration framework. Extensive experiments on 3D Match and ScanNet demonstrate that our method outperforms the state-of-the-art point cloud registration methods even without correspondence or pose supervision. The code is available at: https://github.com/514DNA/LLT.