 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHSM: Hierarchical Scene Motifs for Multi-Scale Indoor Scene Generation
Mar 21, 2025
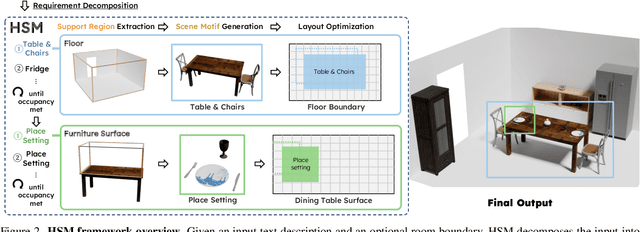

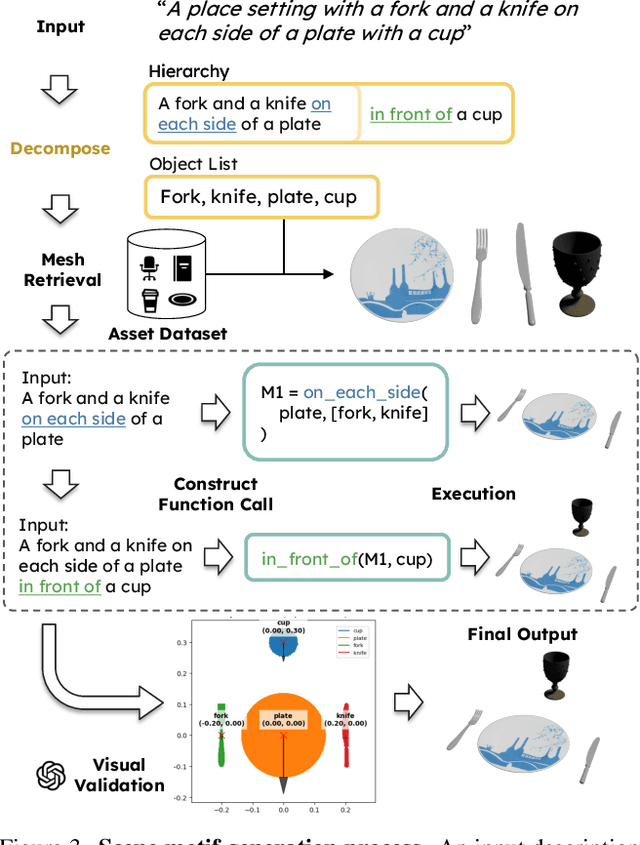
Despite advances in indoor 3D scene layout generation, synthesizing scenes with dense object arrangements remains challenging. Existing methods primarily focus on large furniture while neglecting smaller objects, resulting in unrealistically empty scenes. Those that place small objects typically do not honor arrangement specifications, resulting in largely random placement not following the text description. We present HSM, a hierarchical framework for indoor scene generation with dense object arrangements across spatial scales. Indoor scenes are inherently hierarchical, with surfaces supporting objects at different scales, from large furniture on floors to smaller objects on tables and shelves. HSM embraces this hierarchy and exploits recurring cross-scale spatial patterns to generate complex and realistic indoor scenes in a unified manner. Our experiments show that HSM outperforms existing methods by generating scenes that are more realistic and better conform to user input across room types and spatial configurations.
SceneEval: Evaluating Semantic Coherence in Text-Conditioned 3D Indoor Scene Synthesis
Mar 18, 2025
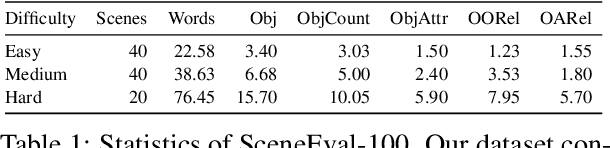
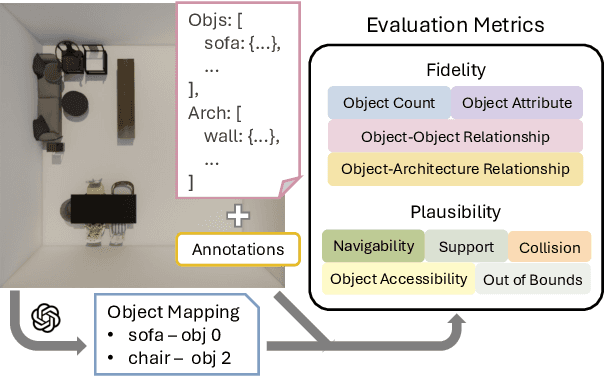

Despite recent advances in text-conditioned 3D indoor scene generation, there remain gaps in the evaluation of these methods. Existing metrics primarily assess the realism of generated scenes by comparing them to a set of ground-truth scenes, often overlooking alignment with the input text - a critical factor in determining how effectively a method meets user requirements. We present SceneEval, an evaluation framework designed to address this limitation. SceneEval includes metrics for both explicit user requirements, such as the presence of specific objects and their attributes described in the input text, and implicit expectations, like the absence of object collisions, providing a comprehensive assessment of scene quality. To facilitate evaluation, we introduce SceneEval-100, a dataset of scene descriptions with annotated ground-truth scene properties. We evaluate recent scene generation methods using SceneEval and demonstrate its ability to provide detailed assessments of the generated scenes, highlighting strengths and areas for improvement across multiple dimensions. Our results show that current methods struggle at generating scenes that meet user requirements, underscoring the need for further research in this direction.
CAGE: Controllable Articulation GEneration
Dec 15, 2023



We address the challenge of generating 3D articulated objects in a controllable fashion. Currently, modeling articulated 3D objects is either achieved through laborious manual authoring, or using methods from prior work that are hard to scale and control directly. We leverage the interplay between part shape, connectivity, and motion using a denoising diffusion-based method with attention modules designed to extract correlations between part attributes. Our method takes an object category label and a part connectivity graph as input and generates an object's geometry and motion parameters. The generated objects conform to user-specified constraints on the object category, part shape, and part articulation. Our experiments show that our method outperforms the state-of-the-art in articulated object generation, producing more realistic objects while conforming better to user constraints. Video Summary at: http://youtu.be/cH_rbKbyTpE