 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneEval: Evaluating Semantic Coherence in Text-Conditioned 3D Indoor Scene Synthesis
Paper and Code

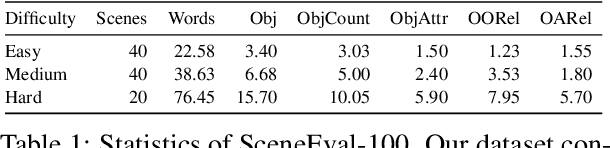
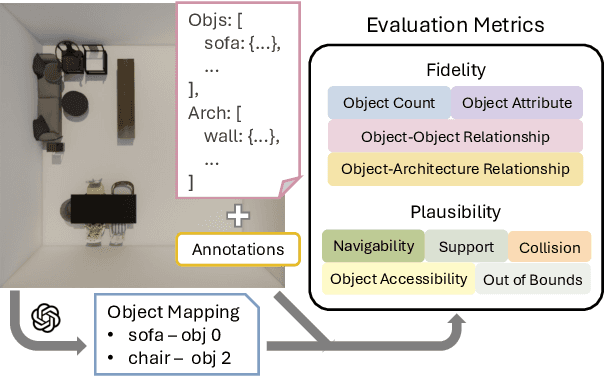

Despite recent advances in text-conditioned 3D indoor scene generation, there remain gaps in the evaluation of these methods. Existing metrics primarily assess the realism of generated scenes by comparing them to a set of ground-truth scenes, often overlooking alignment with the input text - a critical factor in determining how effectively a method meets user requirements. We present SceneEval, an evaluation framework designed to address this limitation. SceneEval includes metrics for both explicit user requirements, such as the presence of specific objects and their attributes described in the input text, and implicit expectations, like the absence of object collisions, providing a comprehensive assessment of scene quality. To facilitate evaluation, we introduce SceneEval-100, a dataset of scene descriptions with annotated ground-truth scene properties. We evaluate recent scene generation methods using SceneEval and demonstrate its ability to provide detailed assessments of the generated scenes, highlighting strengths and areas for improvement across multiple dimensions. Our results show that current methods struggle at generating scenes that meet user requirements, underscoring the need for further research in this direction.