 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePathologist-like explainable AI for interpretable Gleason grading in prostate cancer
Oct 19, 2024



The aggressiveness of prostate cancer, the most common cancer in men worldwide, is primarily assessed based on histopathological data using the Gleason scoring system. While artificial intelligence (AI) has shown promise in accurately predicting Gleason scores, these predictions often lack inherent explainability, potentially leading to distrust in human-machine interactions. To address this issue, we introduce a novel dataset of 1,015 tissue microarray core images, annotated by an international group of 54 pathologists. The annotations provide detailed localized pattern descriptions for Gleason grading in line with international guidelines. Utilizing this dataset, we develop an inherently explainable AI system based on a U-Net architecture that provides predictions leveraging pathologists' terminology. This approach circumvents post-hoc explainability methods while maintaining or exceeding the performance of methods trained directly for Gleason pattern segmentation (Dice score: 0.713 $\pm$ 0.003 trained on explanations vs. 0.691 $\pm$ 0.010 trained on Gleason patterns). By employing soft labels during training, we capture the intrinsic uncertainty in the data, yielding strong results in Gleason pattern segmentation even in the context of high interobserver variability. With the release of this dataset, we aim to encourage further research into segmentation in medical tasks with high levels of subjectivity and to advance the understanding of pathologists' reasoning processes.
Prompt Injection Attacks on Large Language Models in Oncology
Jul 23, 2024



Vision-language artificial intelligence models (VLMs) possess medical knowledge and can be employed in healthcare in numerous ways, including as image interpreters, virtual scribes, and general decision support systems. However, here, we demonstrate that current VLMs applied to medical tasks exhibit a fundamental security flaw: they can be attacked by prompt injection attacks, which can be used to output harmful information just by interacting with the VLM, without any access to its parameters. We performed a quantitative study to evaluate the vulnerabilities to these attacks in four state of the art VLMs which have been proposed to be of utility in healthcare: Claude 3 Opus, Claude 3.5 Sonnet, Reka Core, and GPT-4o. Using a set of N=297 attacks, we show that all of these models are susceptible. Specifically, we show that embedding sub-visual prompts in medical imaging data can cause the model to provide harmful output, and that these prompts are non-obvious to human observers. Thus, our study demonstrates a key vulnerability in medical VLMs which should be mitigated before widespread clinical adoption.
Superhuman performance in urology board questions by an explainable large language model enabled for context integration of the European Association of Urology guidelines: the UroBot study
Jun 04, 2024



Large Language Models (LLMs) are revolutionizing medical Question-Answering (medQA) through extensive use of medical literature. However, their performance is often hampered by outdated training data and a lack of explainability, which limits clinical applicability. This study aimed to create and assess UroBot, a urology-specialized chatbot, by comparing it with state-of-the-art models and the performance of urologists on urological board questions, ensuring full clinician-verifiability. UroBot was developed using OpenAI's GPT-3.5, GPT-4, and GPT-4o models, employing retrieval-augmented generation (RAG) and the latest 2023 guidelines from the European Association of Urology (EAU). The evaluation included ten runs of 200 European Board of Urology (EBU) In-Service Assessment (ISA) questions, with performance assessed by the mean Rate of Correct Answers (RoCA). UroBot-4o achieved an average RoCA of 88.4%, surpassing GPT-4o by 10.8%, with a score of 77.6%. It was also clinician-verifiable and exhibited the highest run agreement as indicated by Fleiss' Kappa (k = 0.979). By comparison, the average performance of urologists on board questions, as reported in the literature, is 68.7%. UroBot's clinician-verifiable nature and superior accuracy compared to both existing models and urologists on board questions highlight its potential for clinical integration. The study also provides the necessary code and instructions for further development of UroBot.
Advancing dermatological diagnosis: Development of a hyperspectral dermatoscope for enhanced skin imaging
Mar 01, 2024



Clinical dermatology necessitates precision and innovation for efficient diagnosis and treatment of various skin conditions. This paper introduces the development of a cutting-edge hyperspectral dermatoscope (the Hyperscope) tailored for human skin analysis. We detail the requirements to such a device and the design considerations, from optical configurations to sensor selection, necessary to capture a wide spectral range with high fidelity. Preliminary results from 15 individuals and 160 recorded skin images demonstrate the potential of the Hyperscope in identifying and characterizing various skin conditions, offering a promising avenue for non-invasive skin evaluation and a platform for future research in dermatology-related hyperspectral imaging.
Clinical Melanoma Diagnosis with Artificial Intelligence: Insights from a Prospective Multicenter Study
Jan 25, 2024Early detection of melanoma, a potentially lethal type of skin cancer with high prevalence worldwide, improves patient prognosis. In retrospective studies, artificial intelligence (AI) has proven to be helpful for enhancing melanoma detection. However, there are few prospective studies confirming these promising results. Existing studies are limited by low sample sizes, too homogenous datasets, or lack of inclusion of rare melanoma subtypes, preventing a fair and thorough evaluation of AI and its generalizability, a crucial aspect for its application in the clinical setting. Therefore, we assessed 'All Data are Ext' (ADAE), an established open-source ensemble algorithm for detecting melanomas, by comparing its diagnostic accuracy to that of dermatologists on a prospectively collected, external, heterogeneous test set comprising eight distinct hospitals, four different camera setups, rare melanoma subtypes, and special anatomical sites. We advanced the algorithm with real test-time augmentation (R-TTA, i.e. providing real photographs of lesions taken from multiple angles and averaging the predictions), and evaluated its generalization capabilities. Overall, the AI showed higher balanced accuracy than dermatologists (0.798, 95% confidence interval (CI) 0.779-0.814 vs. 0.781, 95% CI 0.760-0.802; p<0.001), obtaining a higher sensitivity (0.921, 95% CI 0.900- 0.942 vs. 0.734, 95% CI 0.701-0.770; p<0.001) at the cost of a lower specificity (0.673, 95% CI 0.641-0.702 vs. 0.828, 95% CI 0.804-0.852; p<0.001). As the algorithm exhibited a significant performance advantage on our heterogeneous dataset exclusively comprising melanoma-suspicious lesions, AI may offer the potential to support dermatologists particularly in diagnosing challenging cases.
On the calibration of neural networks for histological slide-level classification
Dec 15, 2023
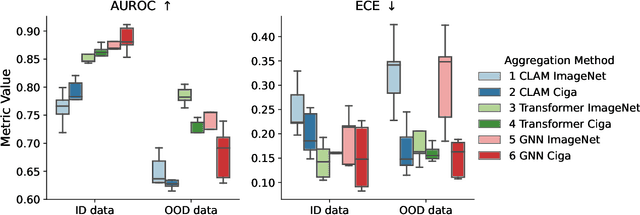
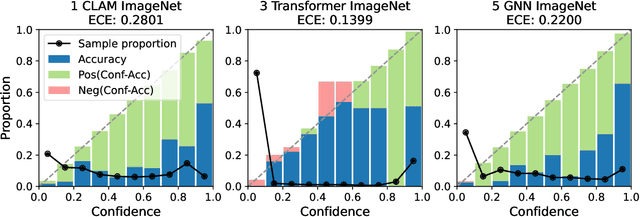
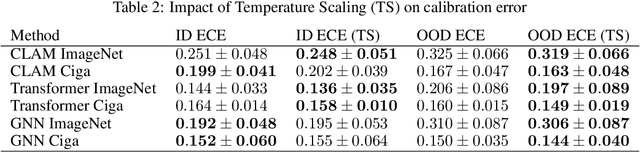
Deep Neural Networks have shown promising classification performance when predicting certain biomarkers from Whole Slide Images in digital pathology. However, the calibration of the networks' output probabilities is often not evaluated. Communicating uncertainty by providing reliable confidence scores is of high relevance in the medical context. In this work, we compare three neural network architectures that combine feature representations on patch-level to a slide-level prediction with respect to their classification performance and evaluate their calibration. As slide-level classification task, we choose the prediction of Microsatellite Instability from Colorectal Cancer tissue sections. We observe that Transformers lead to good results in terms of classification performance and calibration. When evaluating the classification performance on a separate dataset, we observe that Transformers generalize best. The investigation of reliability diagrams provides additional insights to the Expected Calibration Error metric and we observe that especially Transformers push the output probabilities to extreme values, which results in overconfident predictions.
Mitigating the Influence of Domain Shift in Skin Lesion Classification: A Benchmark Study of Unsupervised Domain Adaptation Methods on Dermoscopic Images
Oct 05, 2023



The potential of deep neural networks in skin lesion classification has already been demonstrated to be on-par if not superior to the dermatologists diagnosis. However, the performance of these models usually deteriorates when the test data differs significantly from the training data (i.e. domain shift). This concerning limitation for models intended to be used in real-world skin lesion classification tasks poses a risk to patients. For example, different image acquisition systems or previously unseen anatomical sites on the patient can suffice to cause such domain shifts. Mitigating the negative effect of such shifts is therefore crucial, but developing effective methods to address domain shift has proven to be challenging. In this study, we carry out an in-depth analysis of eight different unsupervised domain adaptation methods to analyze their effectiveness in improving generalization for dermoscopic datasets. To ensure robustness of our findings, we test each method on a total of ten distinct datasets, thereby covering a variety of possible domain shifts. In addition, we investigated which factors in the domain shifted datasets have an impact on the effectiveness of domain adaptation methods. Our findings show that all of the eight domain adaptation methods result in improved AUPRC for the majority of analyzed datasets. Altogether, these results indicate that unsupervised domain adaptations generally lead to performance improvements for the binary melanoma-nevus classification task regardless of the nature of the domain shift. However, small or heavily imbalanced datasets lead to a reduced conformity of the results due to the influence of these factors on the methods performance.
Evaluating Deep Learning-based Melanoma Classification using Immunohistochemistry and Routine Histology: A Three Center Study
Sep 08, 2023



Pathologists routinely use immunohistochemical (IHC)-stained tissue slides against MelanA in addition to hematoxylin and eosin (H&E)-stained slides to improve their accuracy in diagnosing melanomas. The use of diagnostic Deep Learning (DL)-based support systems for automated examination of tissue morphology and cellular composition has been well studied in standard H&E-stained tissue slides. In contrast, there are few studies that analyze IHC slides using DL. Therefore, we investigated the separate and joint performance of ResNets trained on MelanA and corresponding H&E-stained slides. The MelanA classifier achieved an area under receiver operating characteristics curve (AUROC) of 0.82 and 0.74 on out of distribution (OOD)-datasets, similar to the H&E-based benchmark classification of 0.81 and 0.75, respectively. A combined classifier using MelanA and H&E achieved AUROCs of 0.85 and 0.81 on the OOD datasets. DL MelanA-based assistance systems show the same performance as the benchmark H&E classification and may be improved by multi stain classification to assist pathologists in their clinical routine.
Using Multiple Dermoscopic Photographs of One Lesion Improves Melanoma Classification via Deep Learning: A Prognostic Diagnostic Accuracy Study
Jun 05, 2023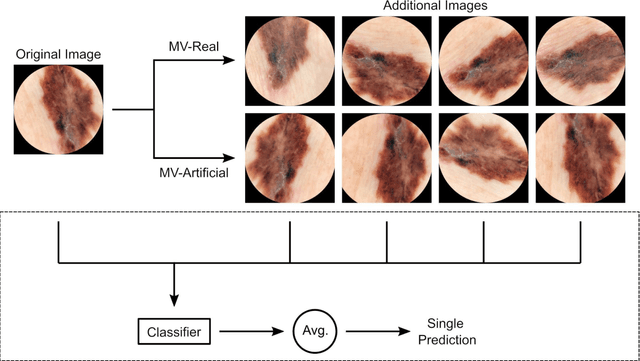
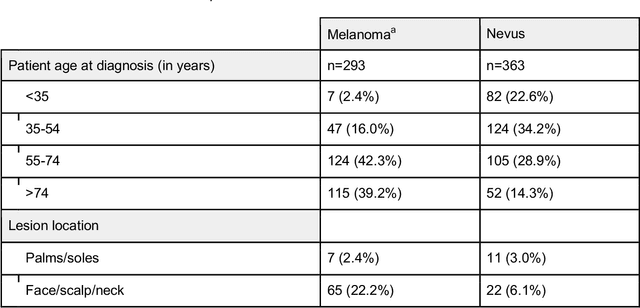
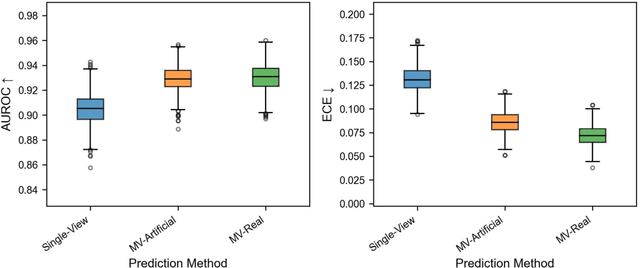
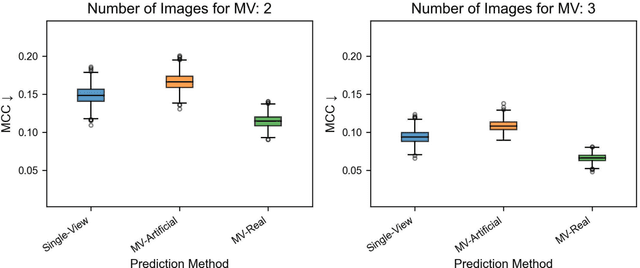
Background: Convolutional neural network (CNN)-based melanoma classifiers face several challenges that limit their usefulness in clinical practice. Objective: To investigate the impact of multiple real-world dermoscopic views of a single lesion of interest on a CNN-based melanoma classifier. Methods: This study evaluated 656 suspected melanoma lesions. Classifier performance was measured using area under the receiver operating characteristic curve (AUROC), expected calibration error (ECE) and maximum confidence change (MCC) for (I) a single-view scenario, (II) a multiview scenario using multiple artificially modified images per lesion and (III) a multiview scenario with multiple real-world images per lesion. Results: The multiview approach with real-world images significantly increased the AUROC from 0.905 (95% CI, 0.879-0.929) in the single-view approach to 0.930 (95% CI, 0.909-0.951). ECE and MCC also improved significantly from 0.131 (95% CI, 0.105-0.159) to 0.072 (95% CI: 0.052-0.093) and from 0.149 (95% CI, 0.125-0.171) to 0.115 (95% CI: 0.099-0.131), respectively. Comparing multiview real-world to artificially modified images showed comparable diagnostic accuracy and uncertainty estimation, but significantly worse robustness for the latter. Conclusion: Using multiple real-world images is an inexpensive method to positively impact the performance of a CNN-based melanoma classifier.
Domain shifts in dermoscopic skin cancer datasets: Evaluation of essential limitations for clinical translation
Apr 18, 2023
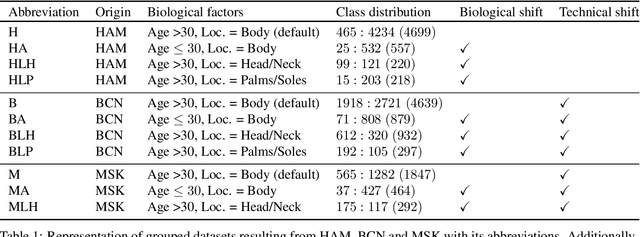
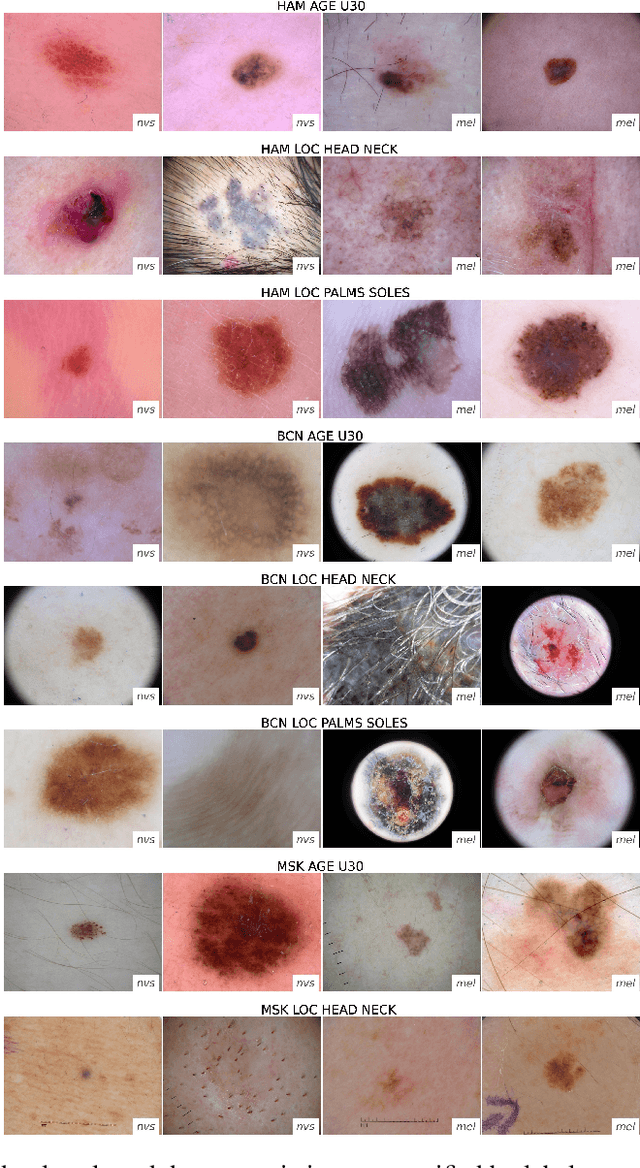
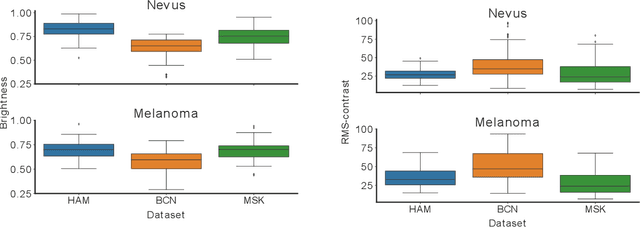
The limited ability of Convolutional Neural Networks to generalize to images from previously unseen domains is a major limitation, in particular, for safety-critical clinical tasks such as dermoscopic skin cancer classification. In order to translate CNN-based applications into the clinic, it is essential that they are able to adapt to domain shifts. Such new conditions can arise through the use of different image acquisition systems or varying lighting conditions. In dermoscopy, shifts can also occur as a change in patient age or occurence of rare lesion localizations (e.g. palms). These are not prominently represented in most training datasets and can therefore lead to a decrease in performance. In order to verify the generalizability of classification models in real world clinical settings it is crucial to have access to data which mimics such domain shifts. To our knowledge no dermoscopic image dataset exists where such domain shifts are properly described and quantified. We therefore grouped publicly available images from ISIC archive based on their metadata (e.g. acquisition location, lesion localization, patient age) to generate meaningful domains. To verify that these domains are in fact distinct, we used multiple quantification measures to estimate the presence and intensity of domain shifts. Additionally, we analyzed the performance on these domains with and without an unsupervised domain adaptation technique. We observed that in most of our grouped domains, domain shifts in fact exist. Based on our results, we believe these datasets to be helpful for testing the generalization capabilities of dermoscopic skin cancer classifiers.