 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFC-MIR: A Mobile Screen Awareness Framework for Intent-Aware Recommendation based on Frame-Compressed Multimodal Trajectory Reasoning
Dec 22, 2025Identifying user intent from mobile UI operation trajectories is critical for advancing UI understanding and enabling task automation agents. While Multimodal Large Language Models (MLLMs) excel at video understanding tasks, their real-time mobile deployment is constrained by heavy computational costs and inefficient redundant frame processing. To address these issues, we propose the FC-MIR framework: leveraging keyframe sampling and adaptive concatenation, it cuts visual redundancy to boost inference efficiency, while integrating state-of-the-art closed-source MLLMs or fine-tuned models (e.g., Qwen3-VL) for trajectory summarization and intent prediction. We further expand task scope to explore generating post-prediction operations and search suggestions, and introduce a fine-grained metric to evaluate the practical utility of summaries, predictions, and suggestions. For rigorous assessment, we construct a UI trajectory dataset covering scenarios from UI-Agents (Agent-I) and real user interactions (Person-I). Experimental results show our compression method retains performance at 50%-60% compression rates; both closed-source and fine-tuned MLLMs demonstrate strong intent summarization, supporting potential lightweight on-device deployment. However, MLLMs still struggle with useful and "surprising" suggestions, leaving room for improvement. Finally, we deploy the framework in a real-world setting, integrating UI perception and UI-Agent proxies to lay a foundation for future progress in this field.
UI-R1: Enhancing Action Prediction of GUI Agents by Reinforcement Learning
Mar 27, 2025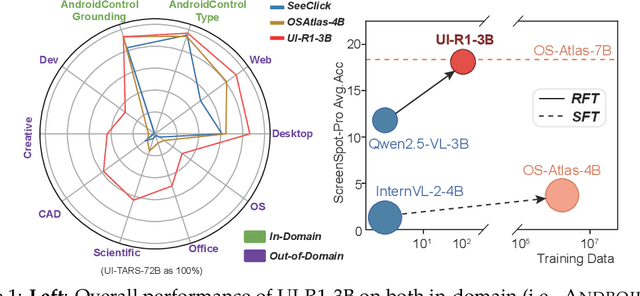
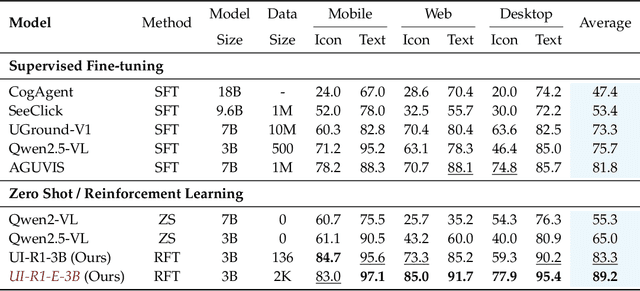
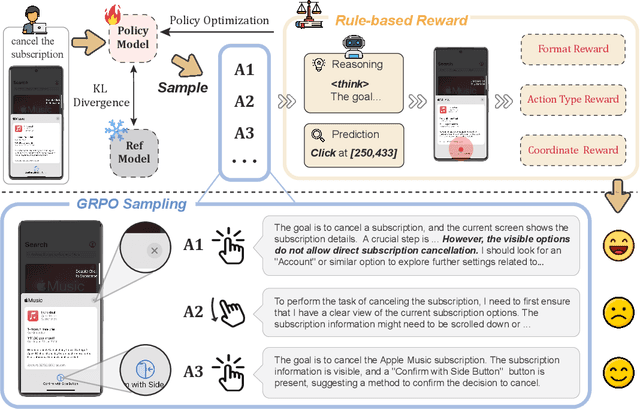
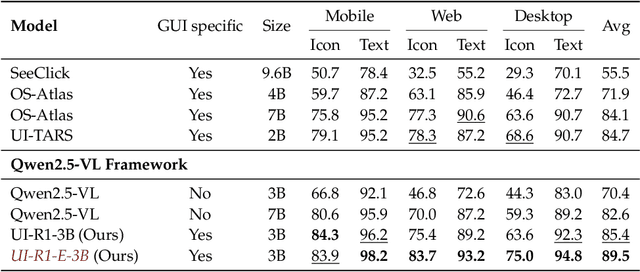
The recent DeepSeek-R1 has showcased the emergence of reasoning capabilities in LLMs through reinforcement learning (RL) with rule-based rewards. Building on this idea, we are the first to explore how rule-based RL can enhance the reasoning capabilities of multimodal large language models (MLLMs) for graphic user interface (GUI) action prediction tasks. To this end, we curate a small yet high-quality dataset of 136 challenging tasks, encompassing five common action types on mobile devices. We also introduce a unified rule-based action reward, enabling model optimization via policy-based algorithms such as Group Relative Policy Optimization (GRPO). Experimental results demonstrate that our proposed data-efficient model, UI-R1-3B, achieves substantial improvements on both in-domain (ID) and out-of-domain (OOD) tasks. Specifically, on the ID benchmark AndroidControl, the action type accuracy improves by 15%, while grounding accuracy increases by 10.3%, compared with the base model (i.e. Qwen2.5-VL-3B). On the OOD GUI grounding benchmark ScreenSpot-Pro, our model surpasses the base model by 6.0% and achieves competitive performance with larger models (e.g., OS-Atlas-7B), which are trained via supervised fine-tuning (SFT) on 76K data. These results underscore the potential of rule-based reinforcement learning to advance GUI understanding and control, paving the way for future research in this domain.
Personal LLM Agents: Insights and Survey about the Capability, Efficiency and Security
Jan 10, 2024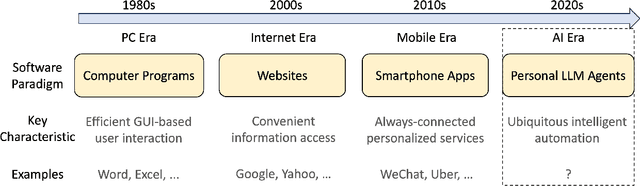
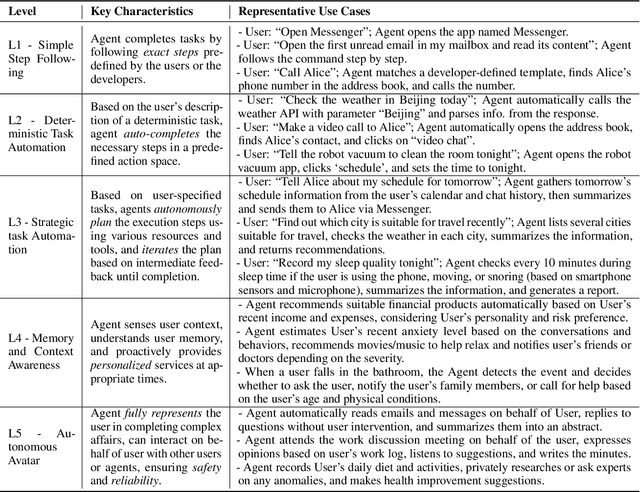
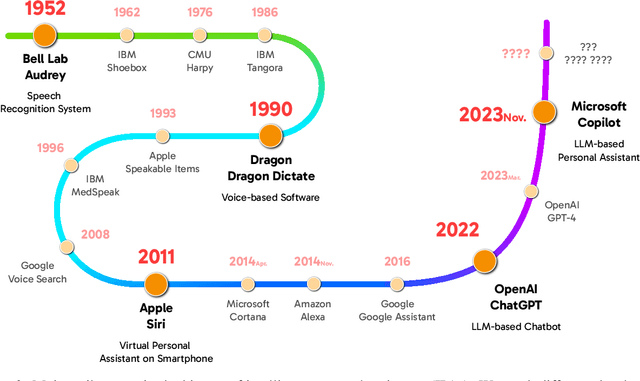
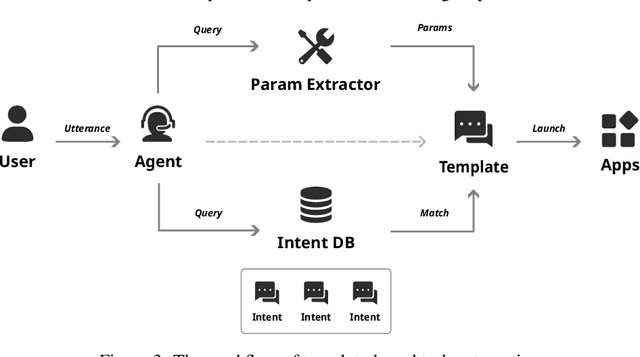
Since the advent of personal computing devices, intelligent personal assistants (IPAs) have been one of the key technologies that researchers and engineers have focused on, aiming to help users efficiently obtain information and execute tasks, and provide users with more intelligent, convenient, and rich interaction experiences. With the development of smartphones and IoT, computing and sensing devices have become ubiquitous, greatly expanding the boundaries of IPAs. However, due to the lack of capabilities such as user intent understanding, task planning, tool using, and personal data management etc., existing IPAs still have limited practicality and scalability. Recently, the emergence of foundation models, represented by large language models (LLMs), brings new opportunities for the development of IPAs. With the powerful semantic understanding and reasoning capabilities, LLM can enable intelligent agents to solve complex problems autonomously. In this paper, we focus on Personal LLM Agents, which are LLM-based agents that are deeply integrated with personal data and personal devices and used for personal assistance. We envision that Personal LLM Agents will become a major software paradigm for end-users in the upcoming era. To realize this vision, we take the first step to discuss several important questions about Personal LLM Agents, including their architecture, capability, efficiency and security. We start by summarizing the key components and design choices in the architecture of Personal LLM Agents, followed by an in-depth analysis of the opinions collected from domain experts. Next, we discuss several key challenges to achieve intelligent, efficient and secure Personal LLM Agents, followed by a comprehensive survey of representative solutions to address these challenges.