 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarmonizing knowledge Transfer in Neural Network with Unified Distillation
Sep 27, 2024Knowledge distillation (KD), known for its ability to transfer knowledge from a cumbersome network (teacher) to a lightweight one (student) without altering the architecture, has been garnering increasing attention. Two primary categories emerge within KD methods: feature-based, focusing on intermediate layers' features, and logits-based, targeting the final layer's logits. This paper introduces a novel perspective by leveraging diverse knowledge sources within a unified KD framework. Specifically, we aggregate features from intermediate layers into a comprehensive representation, effectively gathering semantic information from different stages and scales. Subsequently, we predict the distribution parameters from this representation. These steps transform knowledge from the intermediate layers into corresponding distributive forms, thereby allowing for knowledge distillation through a unified distribution constraint at different stages of the network, ensuring the comprehensiveness and coherence of knowledge transfer. Numerous experiments were conducted to validate the effectiveness of the proposed method.
Student-Oriented Teacher Knowledge Refinement for Knowledge Distillation
Sep 27, 2024



Knowledge distillation has become widely recognized for its ability to transfer knowledge from a large teacher network to a compact and more streamlined student network. Traditional knowledge distillation methods primarily follow a teacher-oriented paradigm that imposes the task of learning the teacher's complex knowledge onto the student network. However, significant disparities in model capacity and architectural design hinder the student's comprehension of the complex knowledge imparted by the teacher, resulting in sub-optimal performance. This paper introduces a novel perspective emphasizing student-oriented and refining the teacher's knowledge to better align with the student's needs, thereby improving knowledge transfer effectiveness. Specifically, we present the Student-Oriented Knowledge Distillation (SoKD), which incorporates a learnable feature augmentation strategy during training to refine the teacher's knowledge of the student dynamically. Furthermore, we deploy the Distinctive Area Detection Module (DAM) to identify areas of mutual interest between the teacher and student, concentrating knowledge transfer within these critical areas to avoid transferring irrelevant information. This customized module ensures a more focused and effective knowledge distillation process. Our approach, functioning as a plug-in, could be integrated with various knowledge distillation methods. Extensive experimental results demonstrate the efficacy and generalizability of our method.
CMG-Net: An End-to-End Contact-Based Multi-Finger Dexterous Grasping Network
Mar 23, 2023



In this paper, we propose a novel representation for grasping using contacts between multi-finger robotic hands and objects to be manipulated. This representation significantly reduces the prediction dimensions and accelerates the learning process. We present an effective end-to-end network, CMG-Net, for grasping unknown objects in a cluttered environment by efficiently predicting multi-finger grasp poses and hand configurations from a single-shot point cloud. Moreover, we create a synthetic grasp dataset that consists of five thousand cluttered scenes, 80 object categories, and 20 million annotations. We perform a comprehensive empirical study and demonstrate the effectiveness of our grasping representation and CMG-Net. Our work significantly outperforms the state-of-the-art for three-finger robotic hands. We also demonstrate that the model trained using synthetic data performs very well for real robots.
CP$^3$: Channel Pruning Plug-in for Point-based Networks
Mar 23, 2023



Channel pruning can effectively reduce both computational cost and memory footprint of the original network while keeping a comparable accuracy performance. Though great success has been achieved in channel pruning for 2D image-based convolutional networks (CNNs), existing works seldom extend the channel pruning methods to 3D point-based neural networks (PNNs). Directly implementing the 2D CNN channel pruning methods to PNNs undermine the performance of PNNs because of the different representations of 2D images and 3D point clouds as well as the network architecture disparity. In this paper, we proposed CP$^3$, which is a Channel Pruning Plug-in for Point-based network. CP$^3$ is elaborately designed to leverage the characteristics of point clouds and PNNs in order to enable 2D channel pruning methods for PNNs. Specifically, it presents a coordinate-enhanced channel importance metric to reflect the correlation between dimensional information and individual channel features, and it recycles the discarded points in PNN's sampling process and reconsiders their potentially-exclusive information to enhance the robustness of channel pruning. Experiments on various PNN architectures show that CP$^3$ constantly improves state-of-the-art 2D CNN pruning approaches on different point cloud tasks. For instance, our compressed PointNeXt-S on ScanObjectNN achieves an accuracy of 88.52% with a pruning rate of 57.8%, outperforming the baseline pruning methods with an accuracy gain of 1.94%.
Label-Guided Auxiliary Training Improves 3D Object Detector
Jul 24, 2022
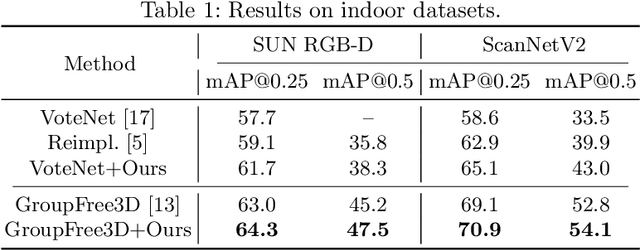
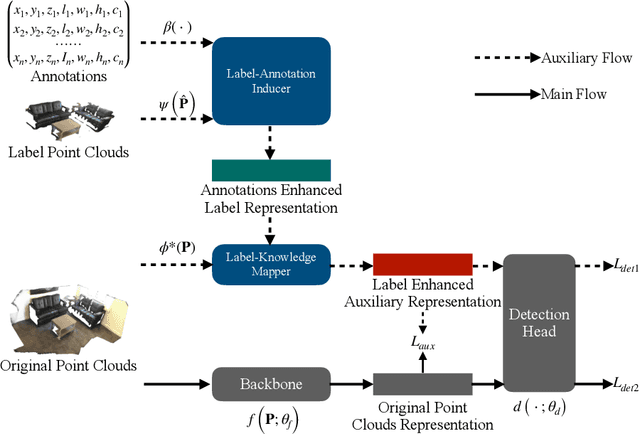
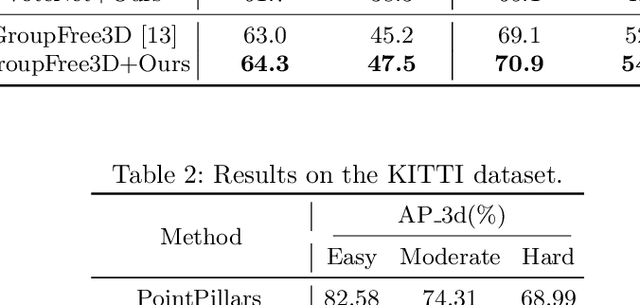
Detecting 3D objects from point clouds is a practical yet challenging task that has attracted increasing attention recently. In this paper, we propose a Label-Guided auxiliary training method for 3D object detection (LG3D), which serves as an auxiliary network to enhance the feature learning of existing 3D object detectors. Specifically, we propose two novel modules: a Label-Annotation-Inducer that maps annotations and point clouds in bounding boxes to task-specific representations and a Label-Knowledge-Mapper that assists the original features to obtain detection-critical representations. The proposed auxiliary network is discarded in inference and thus has no extra computational cost at test time. We conduct extensive experiments on both indoor and outdoor datasets to verify the effectiveness of our approach. For example, our proposed LG3D improves VoteNet by 2.5% and 3.1% mAP on the SUN RGB-D and ScanNetV2 datasets, respectively.