 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCP$^3$: Channel Pruning Plug-in for Point-based Networks
Mar 23, 2023



Channel pruning can effectively reduce both computational cost and memory footprint of the original network while keeping a comparable accuracy performance. Though great success has been achieved in channel pruning for 2D image-based convolutional networks (CNNs), existing works seldom extend the channel pruning methods to 3D point-based neural networks (PNNs). Directly implementing the 2D CNN channel pruning methods to PNNs undermine the performance of PNNs because of the different representations of 2D images and 3D point clouds as well as the network architecture disparity. In this paper, we proposed CP$^3$, which is a Channel Pruning Plug-in for Point-based network. CP$^3$ is elaborately designed to leverage the characteristics of point clouds and PNNs in order to enable 2D channel pruning methods for PNNs. Specifically, it presents a coordinate-enhanced channel importance metric to reflect the correlation between dimensional information and individual channel features, and it recycles the discarded points in PNN's sampling process and reconsiders their potentially-exclusive information to enhance the robustness of channel pruning. Experiments on various PNN architectures show that CP$^3$ constantly improves state-of-the-art 2D CNN pruning approaches on different point cloud tasks. For instance, our compressed PointNeXt-S on ScanObjectNN achieves an accuracy of 88.52% with a pruning rate of 57.8%, outperforming the baseline pruning methods with an accuracy gain of 1.94%.
Label-Guided Auxiliary Training Improves 3D Object Detector
Jul 24, 2022
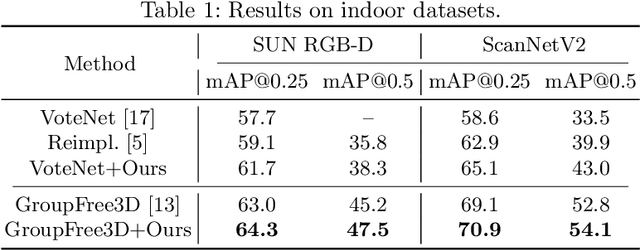
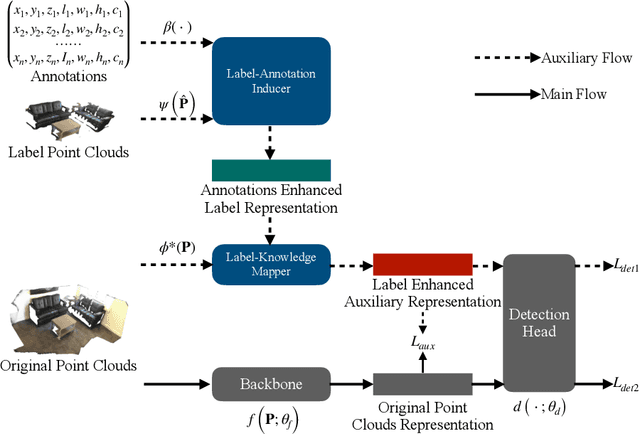
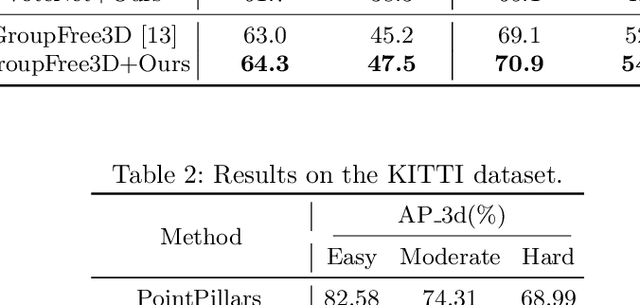
Detecting 3D objects from point clouds is a practical yet challenging task that has attracted increasing attention recently. In this paper, we propose a Label-Guided auxiliary training method for 3D object detection (LG3D), which serves as an auxiliary network to enhance the feature learning of existing 3D object detectors. Specifically, we propose two novel modules: a Label-Annotation-Inducer that maps annotations and point clouds in bounding boxes to task-specific representations and a Label-Knowledge-Mapper that assists the original features to obtain detection-critical representations. The proposed auxiliary network is discarded in inference and thus has no extra computational cost at test time. We conduct extensive experiments on both indoor and outdoor datasets to verify the effectiveness of our approach. For example, our proposed LG3D improves VoteNet by 2.5% and 3.1% mAP on the SUN RGB-D and ScanNetV2 datasets, respectively.