 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge2023 Low-Power Computer Vision Challenge (LPCVC) Summary
Mar 11, 2024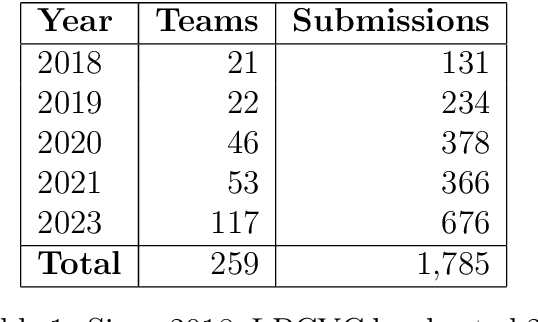
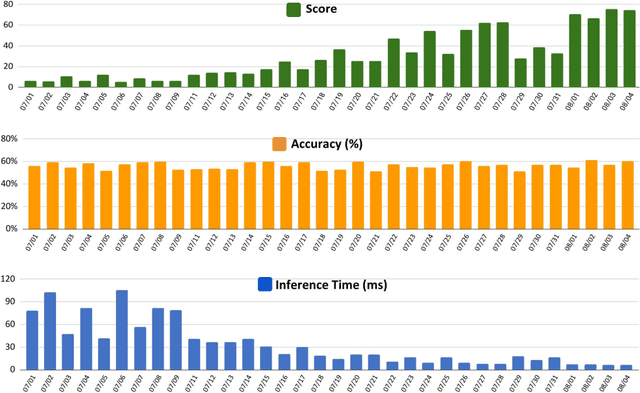

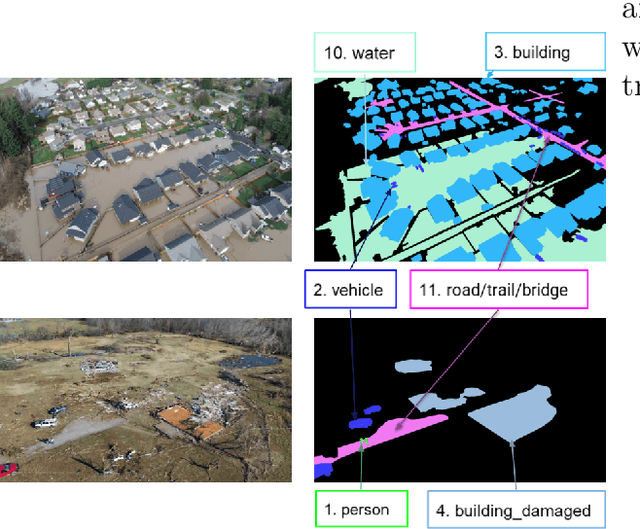
This article describes the 2023 IEEE Low-Power Computer Vision Challenge (LPCVC). Since 2015, LPCVC has been an international competition devoted to tackling the challenge of computer vision (CV) on edge devices. Most CV researchers focus on improving accuracy, at the expense of ever-growing sizes of machine models. LPCVC balances accuracy with resource requirements. Winners must achieve high accuracy with short execution time when their CV solutions run on an embedded device, such as Raspberry PI or Nvidia Jetson Nano. The vision problem for 2023 LPCVC is segmentation of images acquired by Unmanned Aerial Vehicles (UAVs, also called drones) after disasters. The 2023 LPCVC attracted 60 international teams that submitted 676 solutions during the submission window of one month. This article explains the setup of the competition and highlights the winners' methods that improve accuracy and shorten execution time.
EPSD: Early Pruning with Self-Distillation for Efficient Model Compression
Jan 31, 2024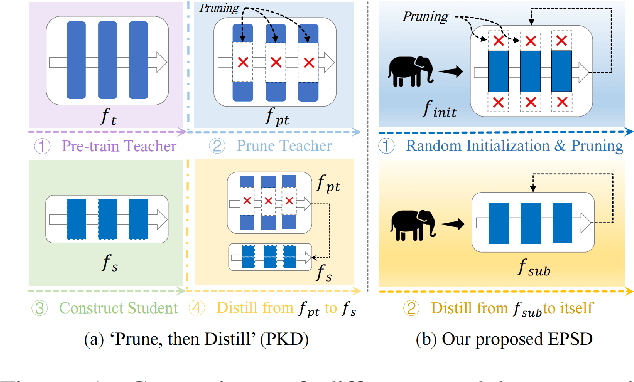
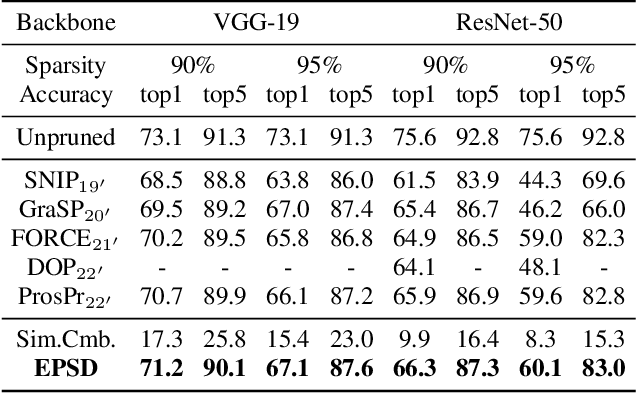
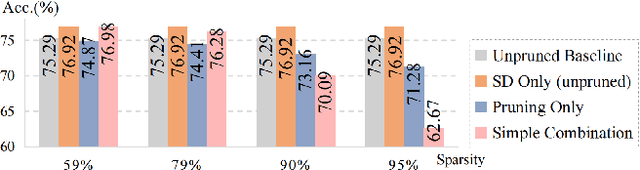
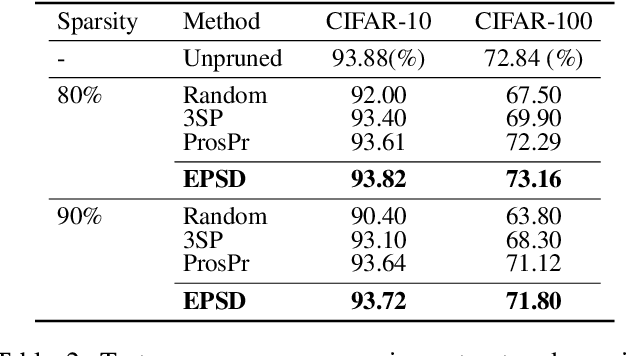
Neural network compression techniques, such as knowledge distillation (KD) and network pruning, have received increasing attention. Recent work `Prune, then Distill' reveals that a pruned student-friendly teacher network can benefit the performance of KD. However, the conventional teacher-student pipeline, which entails cumbersome pre-training of the teacher and complicated compression steps, makes pruning with KD less efficient. In addition to compressing models, recent compression techniques also emphasize the aspect of efficiency. Early pruning demands significantly less computational cost in comparison to the conventional pruning methods as it does not require a large pre-trained model. Likewise, a special case of KD, known as self-distillation (SD), is more efficient since it requires no pre-training or student-teacher pair selection. This inspires us to collaborate early pruning with SD for efficient model compression. In this work, we propose the framework named Early Pruning with Self-Distillation (EPSD), which identifies and preserves distillable weights in early pruning for a given SD task. EPSD efficiently combines early pruning and self-distillation in a two-step process, maintaining the pruned network's trainability for compression. Instead of a simple combination of pruning and SD, EPSD enables the pruned network to favor SD by keeping more distillable weights before training to ensure better distillation of the pruned network. We demonstrated that EPSD improves the training of pruned networks, supported by visual and quantitative analyses. Our evaluation covered diverse benchmarks (CIFAR-10/100, Tiny-ImageNet, full ImageNet, CUB-200-2011, and Pascal VOC), with EPSD outperforming advanced pruning and SD techniques.