 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew Clean Instances Help Denoising Distant Supervision
Paper and Code
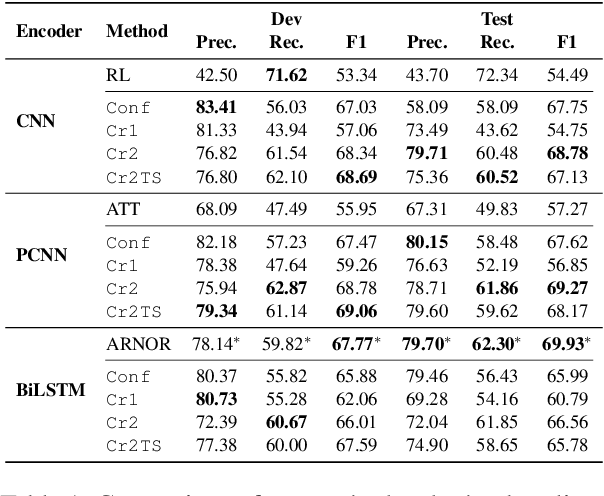
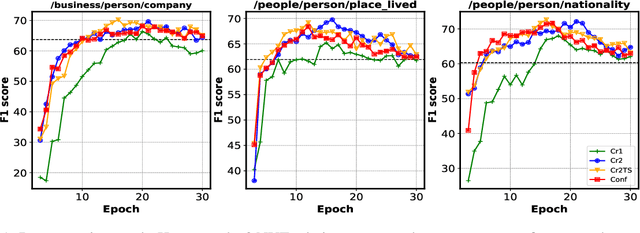
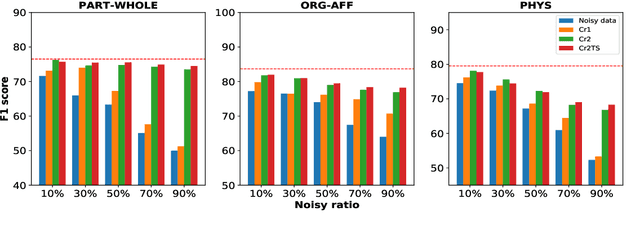
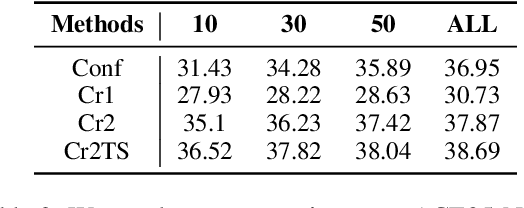
Existing distantly supervised relation extractors usually rely on noisy data for both model training and evaluation, which may lead to garbage-in-garbage-out systems. To alleviate the problem, we study whether a small clean dataset could help improve the quality of distantly supervised models. We show that besides getting a more convincing evaluation of models, a small clean dataset also helps us to build more robust denoising models. Specifically, we propose a new criterion for clean instance selection based on influence functions. It collects sample-level evidence for recognizing good instances (which is more informative than loss-level evidence). We also propose a teacher-student mechanism for controlling purity of intermediate results when bootstrapping the clean set. The whole approach is model-agnostic and demonstrates strong performances on both denoising real (NYT) and synthetic noisy datasets.