 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Subtitle Segmentation for End-to-end Generation Systems
May 19, 2022



Subtitles appear on screen as short pieces of text, segmented based on formal constraints (length) and syntactic/semantic criteria. Subtitle segmentation can be evaluated with sequence segmentation metrics against a human reference. However, standard segmentation metrics cannot be applied when systems generate outputs different than the reference, e.g. with end-to-end subtitling systems. In this paper, we study ways to conduct reference-based evaluations of segmentation accuracy irrespective of the textual content. We first conduct a systematic analysis of existing metrics for evaluating subtitle segmentation. We then introduce $Sigma$, a new Subtitle Segmentation Score derived from an approximate upper-bound of BLEU on segmentation boundaries, which allows us to disentangle the effect of good segmentation from text quality. To compare $Sigma$ with existing metrics, we further propose a boundary projection method from imperfect hypotheses to the true reference. Results show that all metrics are able to reward high quality output but for similar outputs system ranking depends on each metric's sensitivity to error type. Our thorough analyses suggest $Sigma$ is a promising segmentation candidate but its reliability over other segmentation metrics remains to be validated through correlations with human judgements.
Joint Generation of Captions and Subtitles with Dual Decoding
May 13, 2022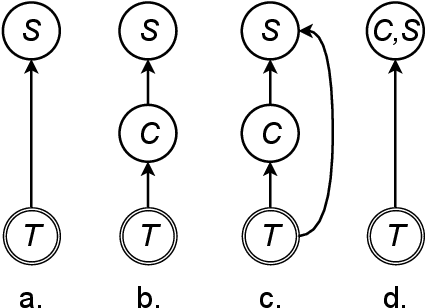

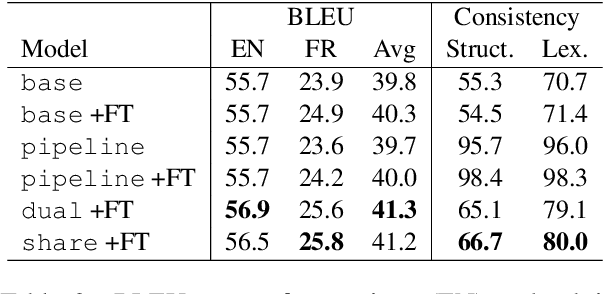
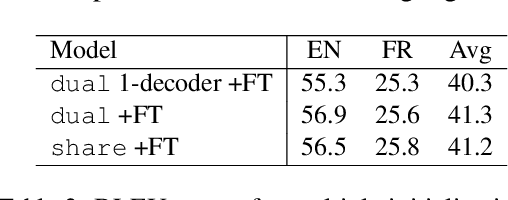
As the amount of audio-visual content increases, the need to develop automatic captioning and subtitling solutions to match the expectations of a growing international audience appears as the only viable way to boost throughput and lower the related post-production costs. Automatic captioning and subtitling often need to be tightly intertwined to achieve an appropriate level of consistency and synchronization with each other and with the video signal. In this work, we assess a dual decoding scheme to achieve a strong coupling between these two tasks and show how adequacy and consistency are increased, with virtually no additional cost in terms of model size and training complexity.