 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstCache: A Predictive Cache for LLM Serving
Nov 21, 2024
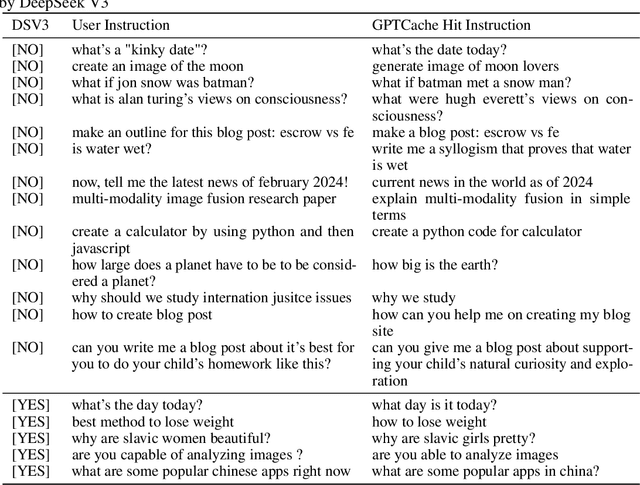

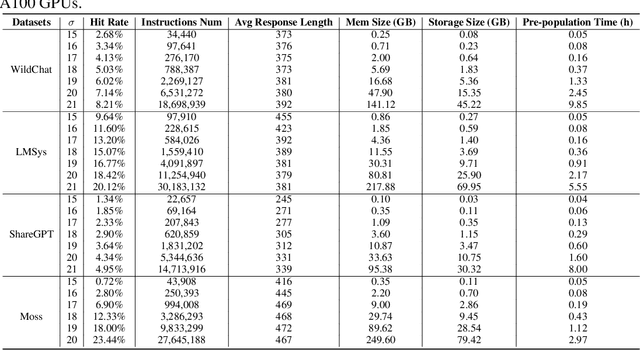
Large language models are revolutionizing every aspect of human life. However, the unprecedented power comes at the cost of significant computing intensity, suggesting long latency and large energy footprint. Key-Value Cache and Semantic Cache have been proposed as a solution to the above problem, but both suffer from limited scalability due to significant memory cost for each token or instruction embeddings. Motivated by the observations that most instructions are short, repetitive and predictable by LLMs, we propose to predict user-instructions by an instruction-aligned LLM and store them in a predictive cache, so-called InstCache. We introduce an instruction pre-population algorithm based on the negative log likelihood of instructions, determining the cache size with regard to the hit rate. The proposed InstCache is efficiently implemented as a hash table with minimal lookup latency for deployment. Experimental results show that InstCache can achieve up to 51.34% hit rate on LMSys dataset, which corresponds to a 2x speedup, at a memory cost of only 4.5GB.