Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Do Networks Need Negative Weights?
Paper and Code
Aug 05, 2022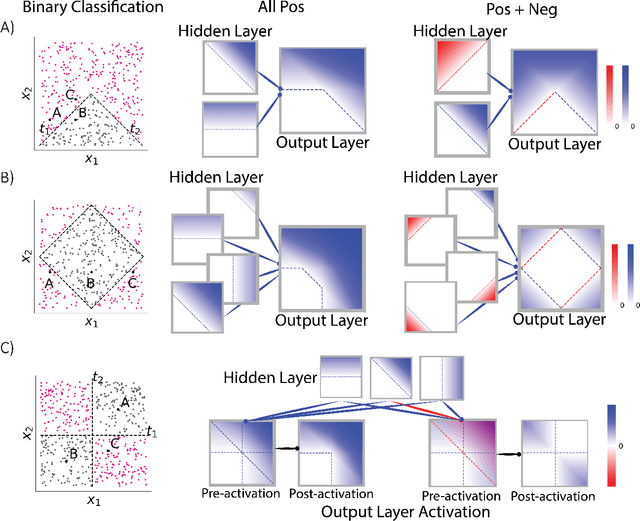
Why do networks have negative weights at all? The answer is: to learn more functions. We mathematically prove that deep neural networks with all non-negative weights are not universal approximators. This fundamental result is assumed by much of the deep learning literature without previously proving the result and demonstrating its necessity.
* Submitted
View paper on