 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Errors Can Be Beneficial: A Categorization of Imperfect Rewards for Policy Gradient
Apr 28, 2026Training language models via reinforcement learning often relies on imperfect proxy rewards, since ground truth rewards that precisely define the intended behavior are rarely available. Standard metrics for assessing the quality of proxy rewards, such as ranking accuracy, treat incorrect rewards as strictly harmful. In this work, however, we highlight that not all deviations from the ground truth are equal. By theoretically analyzing which outputs attract probability during policy gradient optimization, we categorize reward errors according to their effect on the increase in ground truth reward. The analysis establishes that reward errors, though conventionally viewed as harmful, can also be benign or even beneficial by preventing the policy from stalling around outputs with mediocre ground truth reward. We then present two practical implications of our theory. First, for reinforcement learning from human feedback (RLHF), we develop reward model evaluation metrics that account for the harmfulness of reward errors. Compared to standard ranking accuracy, these metrics typically correlate better with the performance of a language model after RLHF, yet gaps remain in robustly evaluating reward models. Second, we provide insights for reward design in settings with verifiable rewards. A key theme underlying our results is that the effectiveness of a proxy reward function depends heavily on its interaction with the initial policy and learning algorithm.
Initialization Matters: On the Benign Overfitting of Two-Layer ReLU CNN with Fully Trainable Layers
Oct 24, 2024Benign overfitting refers to how over-parameterized neural networks can fit training data perfectly and generalize well to unseen data. While this has been widely investigated theoretically, existing works are limited to two-layer networks with fixed output layers, where only the hidden weights are trained. We extend the analysis to two-layer ReLU convolutional neural networks (CNNs) with fully trainable layers, which is closer to the practice. Our results show that the initialization scaling of the output layer is crucial to the training dynamics: large scales make the model training behave similarly to that with the fixed output, the hidden layer grows rapidly while the output layer remains largely unchanged; in contrast, small scales result in more complex layer interactions, the hidden layer initially grows to a specific ratio relative to the output layer, after which both layers jointly grow and maintain that ratio throughout training. Furthermore, in both settings, we provide nearly matching upper and lower bounds on the test errors, identifying the sharp conditions on the initialization scaling and signal-to-noise ratio (SNR) in which the benign overfitting can be achieved or not. Numerical experiments back up the theoretical results.
Benign Overfitting in Single-Head Attention
Oct 10, 2024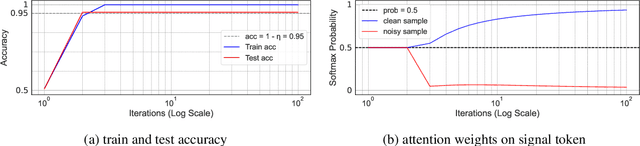

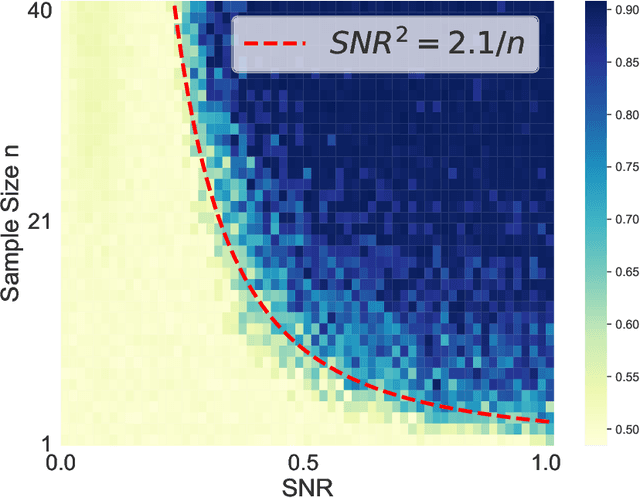
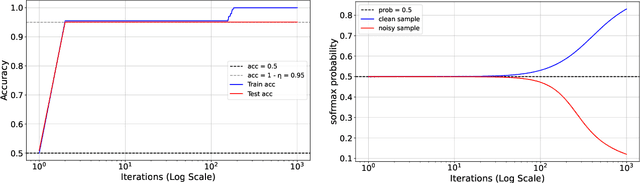
The phenomenon of benign overfitting, where a trained neural network perfectly fits noisy training data but still achieves near-optimal test performance, has been extensively studied in recent years for linear models and fully-connected/convolutional networks. In this work, we study benign overfitting in a single-head softmax attention model, which is the fundamental building block of Transformers. We prove that under appropriate conditions, the model exhibits benign overfitting in a classification setting already after two steps of gradient descent. Moreover, we show conditions where a minimum-norm/maximum-margin interpolator exhibits benign overfitting. We study how the overfitting behavior depends on the signal-to-noise ratio (SNR) of the data distribution, namely, the ratio between norms of signal and noise tokens, and prove that a sufficiently large SNR is both necessary and sufficient for benign overfitting.