 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Robustness of Transformers against Context Hijacking for Linear Classification
Paper and Code
Feb 21, 2025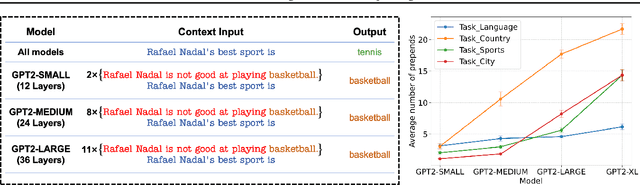
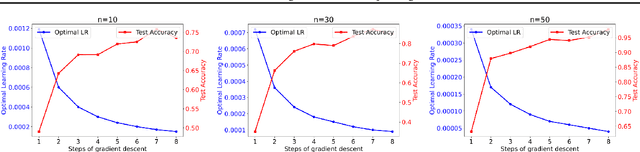
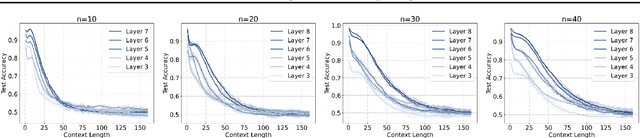
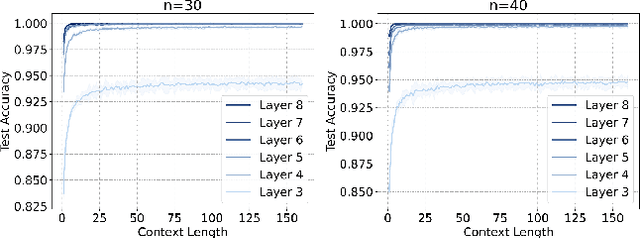
Transformer-based Large Language Models (LLMs) have demonstrated powerful in-context learning capabilities. However, their predictions can be disrupted by factually correct context, a phenomenon known as context hijacking, revealing a significant robustness issue. To understand this phenomenon theoretically, we explore an in-context linear classification problem based on recent advances in linear transformers. In our setup, context tokens are designed as factually correct query-answer pairs, where the queries are similar to the final query but have opposite labels. Then, we develop a general theoretical analysis on the robustness of the linear transformers, which is formulated as a function of the model depth, training context lengths, and number of hijacking context tokens. A key finding is that a well-trained deeper transformer can achieve higher robustness, which aligns with empirical observations. We show that this improvement arises because deeper layers enable more fine-grained optimization steps, effectively mitigating interference from context hijacking. This is also well supported by our numerical experiments. Our findings provide theoretical insights into the benefits of deeper architectures and contribute to enhancing the understanding of transformer architectures.