 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Contextual Inertia: Reinforcement Learning with Single-Turn Anchors for Stable Multi-Turn Interaction
Mar 05, 2026While LLMs demonstrate strong reasoning capabilities when provided with full information in a single turn, they exhibit substantial vulnerability in multi-turn interactions. Specifically, when information is revealed incrementally or requires updates, models frequently fail to integrate new constraints, leading to a collapse in performance compared to their single-turn baselines. We term the root cause as \emph{Contextual Inertia}: a phenomenon where models rigidly adhere to previous reasoning traces. Even when users explicitly provide corrections or new data in later turns, the model ignores them, preferring to maintain consistency with its previous (incorrect) reasoning path. To address this, we introduce \textbf{R}einforcement \textbf{L}earning with \textbf{S}ingle-\textbf{T}urn \textbf{A}nchors (\textbf{RLSTA}), a generalizable training approach designed to stabilize multi-turn interaction across diverse scenarios and domains. RLSTA leverages the model's superior single-turn capabilities as stable internal anchors to provide reward signals. By aligning multi-turn responses with these anchors, RLSTA empowers models to break contextual inertia and self-calibrate their reasoning based on the latest information. Experiments show that RLSTA significantly outperforms standard fine-tuning and abstention-based methods. Notably, our method exhibits strong cross-domain generalization (e.g., math to code) and proves effective even without external verifiers, highlighting its potential for general-domain applications.
Towards Theoretical Understanding of Transformer Test-Time Computing: Investigation on In-Context Linear Regression
Aug 11, 2025Using more test-time computation during language model inference, such as generating more intermediate thoughts or sampling multiple candidate answers, has proven effective in significantly improving model performance. This paper takes an initial step toward bridging the gap between practical language model inference and theoretical transformer analysis by incorporating randomness and sampling. We focus on in-context linear regression with continuous/binary coefficients, where our framework simulates language model decoding through noise injection and binary coefficient sampling. Through this framework, we provide detailed analyses of widely adopted inference techniques. Supported by empirical results, our theoretical framework and analysis demonstrate the potential for offering new insights into understanding inference behaviors in real-world language models.
On the Mechanism of Reasoning Pattern Selection in Reinforcement Learning for Language Models
Jun 05, 2025Reinforcement learning (RL) has demonstrated remarkable success in enhancing model capabilities, including instruction-following, preference learning, and reasoning. Yet despite its empirical successes, the mechanisms by which RL improves reasoning abilities remain poorly understood. We present a systematic study of Reinforcement Learning with Verifiable Rewards (RLVR), showing that its primary benefit comes from optimizing the selection of existing reasoning patterns. Through extensive experiments, we demonstrate that RLVR-trained models preferentially adopt high-success-rate reasoning patterns while mostly maintaining stable performance on individual patterns. We further develop theoretical analyses on the convergence and training dynamics of RLVR based on a simplified question-reason-answer model. We study the gradient flow and show that RLVR can indeed find the solution that selects the reason pattern with the highest success rate. Besides, our theoretical results reveal two distinct regimes regarding the convergence of RLVR training: (1) rapid convergence for models with relatively strong initial reasoning capabilities versus (2) slower optimization dynamics for weaker models. Furthermore, we show that the slower optimization for weaker models can be mitigated by applying the supervised fine-tuning (SFT) before RLVR, when using a feasibly high-quality SFT dataset. We validate the theoretical findings through extensive experiments. This work advances our theoretical understanding of RL's role in LLM fine-tuning and offers insights for further enhancing reasoning capabilities.
On the Robustness of Transformers against Context Hijacking for Linear Classification
Feb 21, 2025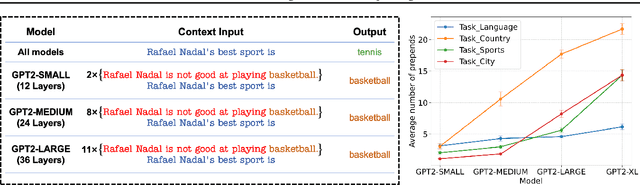
Transformer-based Large Language Models (LLMs) have demonstrated powerful in-context learning capabilities. However, their predictions can be disrupted by factually correct context, a phenomenon known as context hijacking, revealing a significant robustness issue. To understand this phenomenon theoretically, we explore an in-context linear classification problem based on recent advances in linear transformers. In our setup, context tokens are designed as factually correct query-answer pairs, where the queries are similar to the final query but have opposite labels. Then, we develop a general theoretical analysis on the robustness of the linear transformers, which is formulated as a function of the model depth, training context lengths, and number of hijacking context tokens. A key finding is that a well-trained deeper transformer can achieve higher robustness, which aligns with empirical observations. We show that this improvement arises because deeper layers enable more fine-grained optimization steps, effectively mitigating interference from context hijacking. This is also well supported by our numerical experiments. Our findings provide theoretical insights into the benefits of deeper architectures and contribute to enhancing the understanding of transformer architectures.
How Transformers Utilize Multi-Head Attention in In-Context Learning? A Case Study on Sparse Linear Regression
Aug 08, 2024Despite the remarkable success of transformer-based models in various real-world tasks, their underlying mechanisms remain poorly understood. Recent studies have suggested that transformers can implement gradient descent as an in-context learner for linear regression problems and have developed various theoretical analyses accordingly. However, these works mostly focus on the expressive power of transformers by designing specific parameter constructions, lacking a comprehensive understanding of their inherent working mechanisms post-training. In this study, we consider a sparse linear regression problem and investigate how a trained multi-head transformer performs in-context learning. We experimentally discover that the utilization of multi-heads exhibits different patterns across layers: multiple heads are utilized and essential in the first layer, while usually only a single head is sufficient for subsequent layers. We provide a theoretical explanation for this observation: the first layer preprocesses the context data, and the following layers execute simple optimization steps based on the preprocessed context. Moreover, we demonstrate that such a preprocess-then-optimize algorithm can significantly outperform naive gradient descent and ridge regression algorithms. Further experimental results support our explanations. Our findings offer insights into the benefits of multi-head attention and contribute to understanding the more intricate mechanisms hidden within trained transformers.
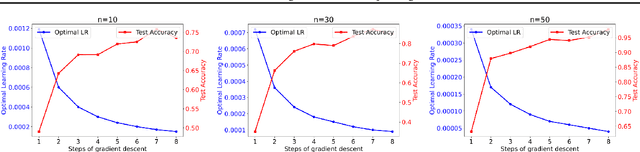
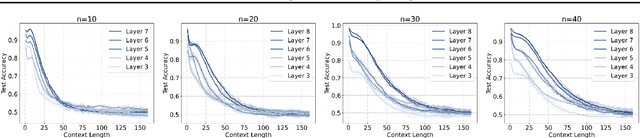
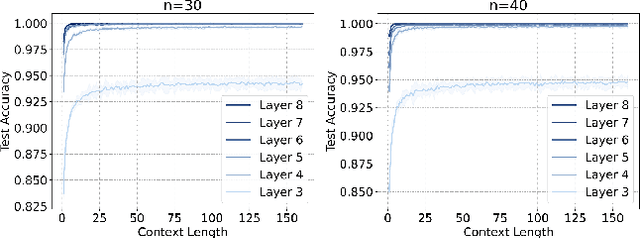
What Can Transformer Learn with Varying Depth? Case Studies on Sequence Learning Tasks
Apr 02, 2024We study the capabilities of the transformer architecture with varying depth. Specifically, we designed a novel set of sequence learning tasks to systematically evaluate and comprehend how the depth of transformer affects its ability to perform memorization, reasoning, generalization, and contextual generalization. We show a transformer with only one attention layer can excel in memorization but falls short in other tasks. Then, we show that exhibiting reasoning and generalization ability requires the transformer to have at least two attention layers, while context generalization ability may necessitate three attention layers. Additionally, we identify a class of simple operations that a single attention layer can execute, and show that the complex tasks can be approached as the combinations of these simple operations and thus can be resolved by stacking multiple attention layers. This sheds light on studying more practical and complex tasks beyond our design. Numerical experiments corroborate our theoretical findings.