 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Potential of LLMs in Medical Education: Generating Questions and Answers for Qualification Exams
Oct 31, 2024Recent research on large language models (LLMs) has primarily focused on their adaptation and application in specialized domains. The application of LLMs in the medical field is mainly concentrated on tasks such as the automation of medical report generation, summarization, diagnostic reasoning, and question-and-answer interactions between doctors and patients. The challenge of becoming a good teacher is more formidable than that of becoming a good student, and this study pioneers the application of LLMs in the field of medical education. In this work, we investigate the extent to which LLMs can generate medical qualification exam questions and corresponding answers based on few-shot prompts. Utilizing a real-world Chinese dataset of elderly chronic diseases, we tasked the LLMs with generating open-ended questions and answers based on a subset of sampled admission reports across eight widely used LLMs, including ERNIE 4, ChatGLM 4, Doubao, Hunyuan, Spark 4, Qwen, Llama 3, and Mistral. Furthermore, we engaged medical experts to manually evaluate these open-ended questions and answers across multiple dimensions. The study found that LLMs, after using few-shot prompts, can effectively mimic real-world medical qualification exam questions, whereas there is room for improvement in the correctness, evidence-based statements, and professionalism of the generated answers. Moreover, LLMs also demonstrate a decent level of ability to correct and rectify reference answers. Given the immense potential of artificial intelligence in the medical field, the task of generating questions and answers for medical qualification exams aimed at medical students, interns and residents can be a significant focus of future research.
Hierarchical Skip Decoding for Efficient Autoregressive Text Generation
Mar 22, 2024Autoregressive decoding strategy is a commonly used method for text generation tasks with pre-trained language models, while early-exiting is an effective approach to speedup the inference stage. In this work, we propose a novel decoding strategy named Hierarchical Skip Decoding (HSD) for efficient autoregressive text generation. Different from existing methods that require additional trainable components, HSD is a plug-and-play method applicable to autoregressive text generation models, it adaptively skips decoding layers in a hierarchical manner based on the current sequence length, thereby reducing computational workload and allocating computation resources. Comprehensive experiments on five text generation datasets with pre-trained language models demonstrate HSD's advantages in balancing efficiency and text quality. With almost half of the layers skipped, HSD can sustain 90% of the text quality compared to vanilla autoregressive decoding, outperforming the competitive approaches.
Parameter-Efficient Fine-Tuning with Layer Pruning on Free-Text Sequence-to-Sequence Modeling
May 19, 2023The increasing size of language models raises great research interests in parameter-efficient fine-tuning such as LoRA that freezes the pre-trained model, and injects small-scale trainable parameters for multiple downstream tasks (e.g., summarization, question answering and translation). To further enhance the efficiency of fine-tuning, we propose a framework that integrates LoRA and structured layer pruning. The integrated framework is validated on two created deidentified medical report summarization datasets based on MIMIC-IV-Note and two public medical dialogue datasets. By tuning 0.6% parameters of the original model and pruning over 30% Transformer-layers, our framework can reduce 50% of GPU memory usage and speed up 100% of the training phase, while preserving over 92% generation qualities on free-text sequence-to-sequence tasks.
Leveraging Summary Guidance on Medical Report Summarization
Feb 08, 2023This study presents three deidentified large medical text datasets, named DISCHARGE, ECHO and RADIOLOGY, which contain 50K, 16K and 378K pairs of report and summary that are derived from MIMIC-III, respectively. We implement convincing baselines of automated abstractive summarization on the proposed datasets with pre-trained encoder-decoder language models, including BERT2BERT, T5-large and BART. Further, based on the BART model, we leverage the sampled summaries from the train set as prior knowledge guidance, for encoding additional contextual representations of the guidance with the encoder and enhancing the decoding representations in the decoder. The experimental results confirm the improvement of ROUGE scores and BERTScore made by the proposed method, outperforming the larger model T5-large.
Active Learning with Effective Scoring Functions for Semi-Supervised Temporal Action Localization
Aug 31, 2022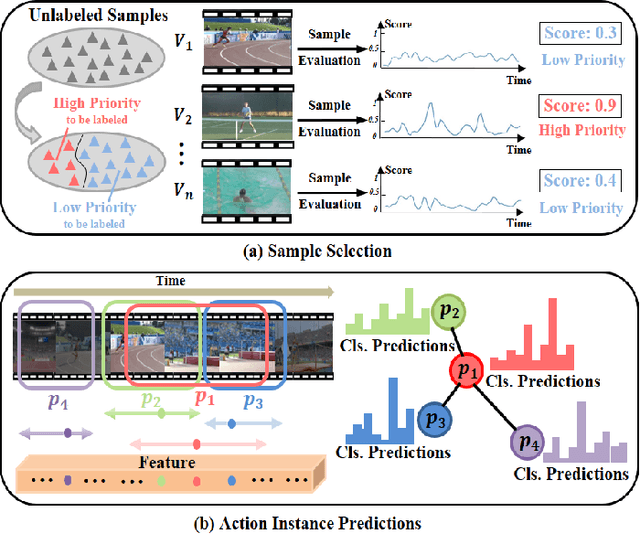
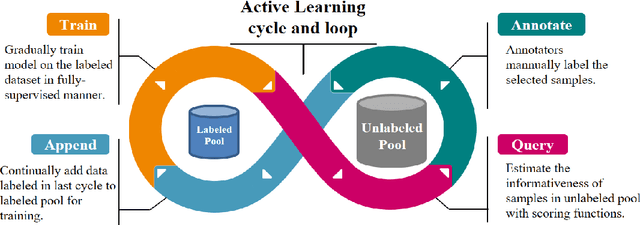
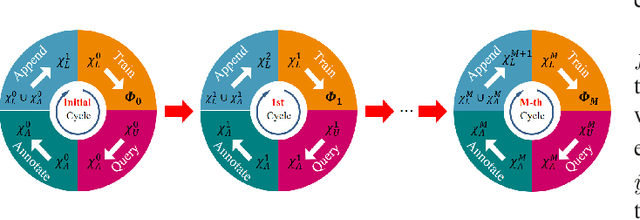
Temporal Action Localization (TAL) aims to predict both action category and temporal boundary of action instances in untrimmed videos, i.e., start and end time. Fully-supervised solutions are usually adopted in most existing works, and proven to be effective. One of the practical bottlenecks in these solutions is the large amount of labeled training data required. To reduce expensive human label cost, this paper focuses on a rarely investigated yet practical task named semi-supervised TAL and proposes an effective active learning method, named AL-STAL. We leverage four steps for actively selecting video samples with high informativeness and training the localization model, named \emph{Train, Query, Annotate, Append}. Two scoring functions that consider the uncertainty of localization model are equipped in AL-STAL, thus facilitating the video sample rank and selection. One takes entropy of predicted label distribution as measure of uncertainty, named Temporal Proposal Entropy (TPE). And the other introduces a new metric based on mutual information between adjacent action proposals and evaluates the informativeness of video samples, named Temporal Context Inconsistency (TCI). To validate the effectiveness of proposed method, we conduct extensive experiments on two benchmark datasets THUMOS'14 and ActivityNet 1.3. Experiment results show that AL-STAL outperforms the existing competitors and achieves satisfying performance compared with fully-supervised learning.
Learnable Faster Kernel-PCA for Nonlinear Fault Detection: Deep Autoencoder-Based Realization
Dec 08, 2021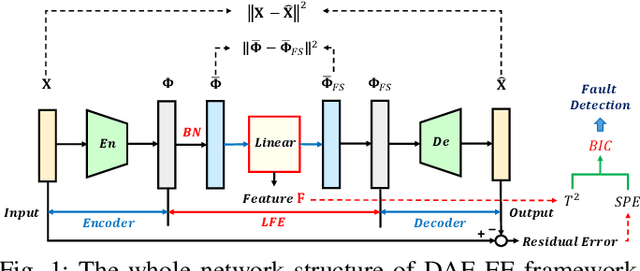
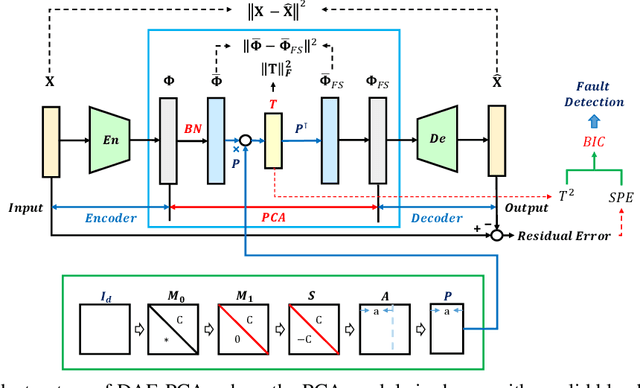
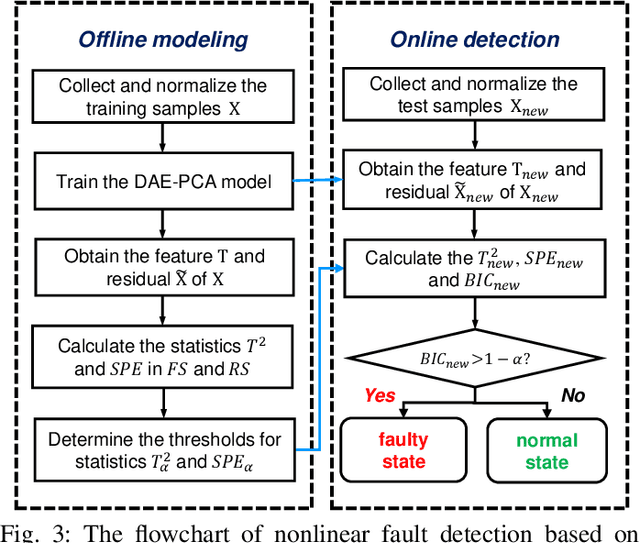
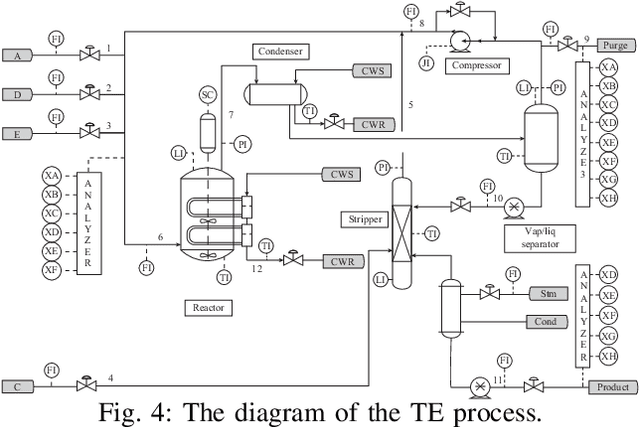
Kernel principal component analysis (KPCA) is a well-recognized nonlinear dimensionality reduction method that has been widely used in nonlinear fault detection tasks. As a kernel trick-based method, KPCA inherits two major problems. First, the form and the parameters of the kernel function are usually selected blindly, depending seriously on trial-and-error. As a result, there may be serious performance degradation in case of inappropriate selections. Second, at the online monitoring stage, KPCA has much computational burden and poor real-time performance, because the kernel method requires to leverage all the offline training data. In this work, to deal with the two drawbacks, a learnable faster realization of the conventional KPCA is proposed. The core idea is to parameterize all feasible kernel functions using the novel nonlinear DAE-FE (deep autoencoder based feature extraction) framework and propose DAE-PCA (deep autoencoder based principal component analysis) approach in detail. The proposed DAE-PCA method is proved to be equivalent to KPCA but has more advantage in terms of automatic searching of the most suitable nonlinear high-dimensional space according to the inputs. Furthermore, the online computational efficiency improves by approximately 100 times compared with the conventional KPCA. With the Tennessee Eastman (TE) process benchmark, the effectiveness and superiority of the proposed method is illustrated.