 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Potential of LLMs in Medical Education: Generating Questions and Answers for Qualification Exams
Oct 31, 2024Recent research on large language models (LLMs) has primarily focused on their adaptation and application in specialized domains. The application of LLMs in the medical field is mainly concentrated on tasks such as the automation of medical report generation, summarization, diagnostic reasoning, and question-and-answer interactions between doctors and patients. The challenge of becoming a good teacher is more formidable than that of becoming a good student, and this study pioneers the application of LLMs in the field of medical education. In this work, we investigate the extent to which LLMs can generate medical qualification exam questions and corresponding answers based on few-shot prompts. Utilizing a real-world Chinese dataset of elderly chronic diseases, we tasked the LLMs with generating open-ended questions and answers based on a subset of sampled admission reports across eight widely used LLMs, including ERNIE 4, ChatGLM 4, Doubao, Hunyuan, Spark 4, Qwen, Llama 3, and Mistral. Furthermore, we engaged medical experts to manually evaluate these open-ended questions and answers across multiple dimensions. The study found that LLMs, after using few-shot prompts, can effectively mimic real-world medical qualification exam questions, whereas there is room for improvement in the correctness, evidence-based statements, and professionalism of the generated answers. Moreover, LLMs also demonstrate a decent level of ability to correct and rectify reference answers. Given the immense potential of artificial intelligence in the medical field, the task of generating questions and answers for medical qualification exams aimed at medical students, interns and residents can be a significant focus of future research.
Hierarchical Skip Decoding for Efficient Autoregressive Text Generation
Mar 22, 2024Autoregressive decoding strategy is a commonly used method for text generation tasks with pre-trained language models, while early-exiting is an effective approach to speedup the inference stage. In this work, we propose a novel decoding strategy named Hierarchical Skip Decoding (HSD) for efficient autoregressive text generation. Different from existing methods that require additional trainable components, HSD is a plug-and-play method applicable to autoregressive text generation models, it adaptively skips decoding layers in a hierarchical manner based on the current sequence length, thereby reducing computational workload and allocating computation resources. Comprehensive experiments on five text generation datasets with pre-trained language models demonstrate HSD's advantages in balancing efficiency and text quality. With almost half of the layers skipped, HSD can sustain 90% of the text quality compared to vanilla autoregressive decoding, outperforming the competitive approaches.
Parameter-Efficient Fine-Tuning with Layer Pruning on Free-Text Sequence-to-Sequence Modeling
May 19, 2023The increasing size of language models raises great research interests in parameter-efficient fine-tuning such as LoRA that freezes the pre-trained model, and injects small-scale trainable parameters for multiple downstream tasks (e.g., summarization, question answering and translation). To further enhance the efficiency of fine-tuning, we propose a framework that integrates LoRA and structured layer pruning. The integrated framework is validated on two created deidentified medical report summarization datasets based on MIMIC-IV-Note and two public medical dialogue datasets. By tuning 0.6% parameters of the original model and pruning over 30% Transformer-layers, our framework can reduce 50% of GPU memory usage and speed up 100% of the training phase, while preserving over 92% generation qualities on free-text sequence-to-sequence tasks.
Leveraging Summary Guidance on Medical Report Summarization
Feb 08, 2023This study presents three deidentified large medical text datasets, named DISCHARGE, ECHO and RADIOLOGY, which contain 50K, 16K and 378K pairs of report and summary that are derived from MIMIC-III, respectively. We implement convincing baselines of automated abstractive summarization on the proposed datasets with pre-trained encoder-decoder language models, including BERT2BERT, T5-large and BART. Further, based on the BART model, we leverage the sampled summaries from the train set as prior knowledge guidance, for encoding additional contextual representations of the guidance with the encoder and enhancing the decoding representations in the decoder. The experimental results confirm the improvement of ROUGE scores and BERTScore made by the proposed method, outperforming the larger model T5-large.
Differentiable N-gram Objective on Abstractive Summarization
Feb 10, 2022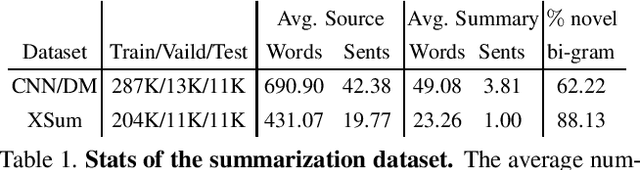
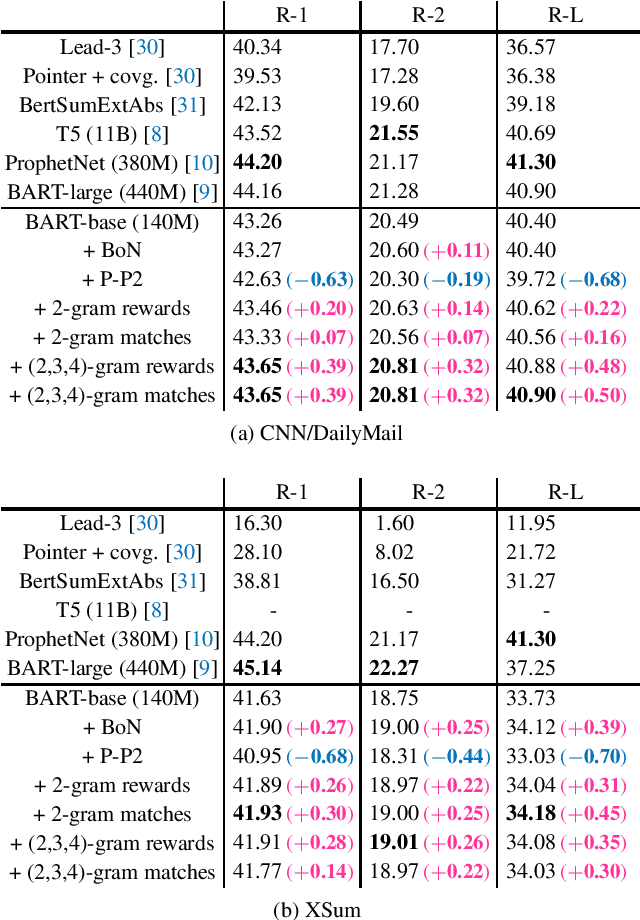

ROUGE is a standard automatic evaluation metric based on n-grams for sequence-to-sequence tasks, while cross-entropy loss is an essential objective of neural network language model that optimizes at a unigram level. We present differentiable n-gram objectives, attempting to alleviate the discrepancy between training criterion and evaluating criterion. The objective maximizes the probabilistic weight of matched sub-sequences, and the novelty of our work is the objective weights the matched sub-sequences equally and does not ceil the number of matched sub-sequences by the ground truth count of n-grams in reference sequence. We jointly optimize cross-entropy loss and the proposed objective, providing decent ROUGE score enhancement over abstractive summarization dataset CNN/DM and XSum, outperforming alternative n-gram objectives.